通过源码理解手写简单版本MyBatis框架(十)
一、需求分析
1.1项目需求
通过原始的JDBC代码来操作数据库非常的麻烦,里面存在着太多的重复代码和低下的开发效率,针对这种情况需要提供一个更加高效的持久层框架。
1.2 核心功能
首先来看下JDBC操作查询的代码。
public class JdbcTest { public static void main(String[] args) { new JdbcTest().queryUser(); new JdbcTest().addUser(); } /** * * 通过JDBC查询用户信息 */ public void queryUser(){ Connection conn = null; Statement stmt = null; User user = new User(); try { // 注册 JDBC 驱动 // Class.forName("com.mysql.cj.jdbc.Driver"); // 打开连接 conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8&serverTimezone=UTC", "root", "root"); // 执行查询 stmt = conn.createStatement(); String sql = "SELECT id,user_name,real_name,password,age,d_id from t_user where id = 1"; ResultSet rs = stmt.executeQuery(sql); // 获取结果集 while (rs.next()) { Integer id = rs.getInt("id"); String userName = rs.getString("user_name"); String realName = rs.getString("real_name"); String password = rs.getString("password"); Integer did = rs.getInt("d_id"); user.setId(id); user.setUserName(userName); user.setRealName(realName); user.setPassword(password); user.setDId(did); System.out.println(user); } rs.close(); stmt.close(); conn.close(); } catch (SQLException se) { se.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } finally { try { if (stmt != null) stmt.close(); } catch (SQLException se2) { } try { if (conn != null) conn.close(); } catch (SQLException se) { se.printStackTrace(); } } } /** * 通过JDBC实现添加用户信息的操作 */ public void addUser(){ Connection conn = null; Statement stmt = null; try { // 注册 JDBC 驱动 // Class.forName("com.mysql.cj.jdbc.Driver"); // 打开连接 conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8&serverTimezone=UTC", "root", "root"); // 执行查询 stmt = conn.createStatement(); String sql = "INSERT INTO T_USER(user_name,real_name,password,age,d_id)values('ww','王五','111',22,1001)"; int i = stmt.executeUpdate(sql); System.out.println("影响的行数:" + i); stmt.close(); conn.close(); } catch (SQLException se) { se.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } finally { try { if (stmt != null) stmt.close(); } catch (SQLException se2) { } try { if (conn != null) conn.close(); } catch (SQLException se) { se.printStackTrace(); } } } }
通过上面的代码,可以发现问题还是比较多的。
1.2.1 资源管理
它需要实现对连接资源的自动管理,也就是把创建Connection、创建Statement、关闭Connection、关闭Statement这些操作封装到底层的对象中,不需要在应用层手动调用。
rs.close();
stmt.close();
conn.close();
1.2.2 SQL语句
在代码中我们直接将SQL语句和业务代码写在了一起,耦合性太高了,我们需要把SQL语句抽离出来实现集中管理,开发人员不用在业务代码里面写SQL语句
1.2.3 结果集映射
在上面的代码中我们需要根据字段取出值,然后把值设置到对应对象的属性中,这个操作也是很繁琐的,所以我们也希望框架能够自动帮助我们实现结果集的转换,也就是我们指定了映射规则之后,这个框架会自动帮我们把ResultSet映射成实体类对象。
while (rs.next()) { Integer id = rs.getInt("id"); String userName = rs.getString("user_name"); String realName = rs.getString("real_name"); String password = rs.getString("password"); Integer did = rs.getInt("d_id"); user.setId(id); user.setUserName(userName); user.setRealName(realName); user.setPassword(password); user.setDId(did); System.out.println(user); }
1.2.4 对外API
实现了上面的功能以后,这个框架需要提供一个API来给我们操作数据库,这里面定义了对数据库的操作的常用的方法。
1.3 功能分解
项目的需求我们也已经清楚了,那么我们应该要怎么来解决这些问题呢?,我们先来分析下需要哪些核心对象
1.3.1 核心对象
1、存放参数和结果映射关系、存放SQL语句,我们需要定义一个配置类;
2、执行对数据库的操作,处理参数和结果集的映射,创建和释放资源,需要定义一个执行器;
3、有了这个执行器以后,我们不能直接调用它,而是定义一个给应用层使用的API,它可以根据SQL的id找到SQL语句,交给执行器执行;
4、如果由用户直接使用id查找SQL语句太麻烦了,干脆把存放SQL的命名空间定义成一个接口,把SQL的id定义成方法,这样只要调用接口方法就可以找到要执行的SQL。刚好动态代理可以实现这个功能。这个时候需要引入一个代理类。
核心对象有了,第二个:分析一下这个框架操作数据库的主要流程,先从单条查询入手。
1.3.2 操作流程
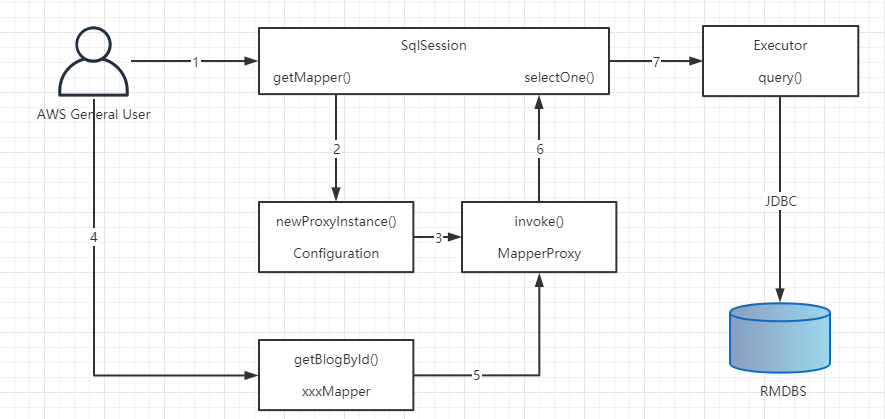
1、定义配置类对象Configuration。里面要存放SQL语句,还有查询方法和结果映射的关系。
2、定义应用层的API SqlSession。在SqlSession里面封装增删改查和操作事务的方法(selectOne())。
3、如果直接把Statement ID传给SqlSession去执行SQL,会出现硬编码,所以决定把SQL语句的标识设计成一个接口+方法名(Mapper接口),调用接口的方法就能找到SQL语句。
4、这个需要代理模式实现,所以要创建一个实现了InvocationHandler的触发管理类MapperProxy。代理类在Configuration中通过JDK动态代理创建。
5、有了代理对象之后,调用接口方法,就是调用触发管理器MapperProxy的invoke()方法。
6、代理对象的invoke()方法调用了SqlSession的selectOne()。
7、SqlSession只是一个API,还不是真正的SQL执行者,所以接下来会调用执行器Executor的query()方法。
8、执行器Executor的query()方法里面就是对JDBC底层的Statement的封装,最终实现对数据库的操作,和结果的返回。
二、代码实现
2.1 SqlSession
针对不同用户的请求操作可以通过SqlSession来处理,在SqlSession中可以提供基础的操作API,我定义的名称为GhySqlSession,暂时不需要考虑其他的实现,所以先不用创建接口,直接写类。
根据刚才总结的流程图,SqlSession需要有一个获取代理对象的方法,那么这个代理对象是从哪里获取到的呢?是从配置类里面获取到的,因为配置类里面有接口和它要产生的代理类的对应关系。
所以,要先持有一个Configuration对象,叫GhyConfiguration,创建这个类。除了获取代理对象之外,它里面还存储了接口方法(也就是statementId)和SQL语句的绑定关系。
在SqlSession中定义的对外的API,最后都会调用Executor去操作数据库,所以还要持有一个Executor对象,叫GhyExecutor,也创建它
public class GhySqlSession { private GhyConfiguration configuration; private GhyExecutor executor; }
除了这两个属性之外,还要定义SqlSession的行为,也就是它的主要的方法。
第一个方法是查询方法,selectOne(),由于它可以返回任意类型(List、Map、对象类型),把返回值定义成 T泛型。selectOne()有两个参数,一个是String类型的statementId,我们会根据它找到SQL语句。一个是Object类型的parameter参数(可以是Integer也可以是String等等,任意类型),用来填充SQL里面的占位符。
/** * 对外提供的查询的方法 * @param <T> * @return */ public <T> T selectOne(String statementId,Object parameter){ String sql=statementId; //先用statementId代替SQL return executor.query(sql,parameter); }
它会调用Executor的query()方法,所以创建Executor类,传入这两个参数,一样返回一个泛型。Executor里面要传入SQL,但是目前还没拿到,先用statementId代替。
/** * SQL语句的执行器 */ public class GhyExecutor { public <T> T query(String sql ,Object parameter) { return null; } }
SqlSession的第二个方法是获取代理对象的方法,通过这种方式去避免了statementId的硬编码。在SqlSession中创建一个getMapper()的方法,由于可以返回任意类型的代理类,所以把返回值也定义成泛型 T。我是根据接口类型获取到代理对象的,所以传入参数要用类型Class。
//获取代理对象 public <T> T getMapper(Class clazz){ return configuration.getMapper(clazz ); }
2.2 Configuration
代理对象不是在SqlSession里面获取到的,要进一步调用Configuration的getMapper()方法。返回值需要强转成(T)。
/** * 用来保存相关的配置信息 */ public class GhyConfiguration { public <T> T getMapper(Class clazz){ return null; } }
2.3 MapperProxy
我们要在Configuration中通过getMapper()方法拿到这个代理对象,必须要有一个实现了InvocationHandler的代理类(触发管理器)。创建它:GhyMapperProxy。实现invoke()方法。
public class GhyMapperProxy implements InvocationHandler { @Override public Object invoke(Object proxy,Method method,Object[] args) throws Throwable { return null; } }
invoke()的实现先留着。MapperProxy已经有了,回到Configuration.getMapper()完成获取代理对象的逻辑。返回代理对象,直接使用JDK的动态代理:第一个参数是类加载器,第二个参数是被代理类实现的接口(这里没有被代理类),第三个参数是H(触发管理器)。把返回结果强转为(T):
public <T> T getMapper(Class clazz,GhySqlSession sqlSession){ return (T) Proxy.newProxyInstance(this.getClass().getClassLoader(), new Class[]{clazz}, new GhyMapperProxy()); }
获取代理类的逻辑已经实现完了,可以在SqlSession中通过getMapper()拿到代理对象了,也就是可以调用invoke()方法了。接下来去完成MapperProxy 的invoke()方法。在MapperProxy的invoke()方法里面又调用了SqlSession的selectOne()方法。一个问题出现了:在MapperProxy里面根本没有SqlSession对象?这两个对象的关系怎么建立起来?MapperProxy怎么拿到一个SqlSession对象?很简单,我们可通过构造函数传入它。先定义一个属性,然后在MapperProxy的构造函数里面赋值
public class GhyMapperProxy implements InvocationHandler { private GhySqlSession sqlSession; public GhyMapperProxy(GhySqlSession sqlSession) { this.sqlSession = sqlSession; } @Override public Object invoke(Object proxy,Method method,Object[] args) throws Throwable { return null; } }
因为修改了代理类的构造函数,这个时候Configuration创建代理类的方法getMapper()也要修改。问题:Configuration也没有SqlSession,没办法传入MapperProxy的构造函数。怎么拿到SqlSession呢?是直接new一个吗?不需要,可以在SqlSession调用它的时候直接把自己传进来(修改的地方:MapperProxy的构造函数添加了sqlSession,getMapper()方法也添加了SqlSession):
/** * 用来保存相关的配置信息 */ public class GhyConfiguration { public <T> T getMapper(Class clazz,GhySqlSession sqlSession){ return (T) Proxy.newProxyInstance(this.getClass().getClassLoader(), new Class[]{clazz}, new GhyMapperProxy(sqlSession)); } }
那么SqlSession的getMapper()方法也要修改(红色是修改的地方):
//获取代理对象 public <T> T getMapper(Class clazz){ return configuration.getMapper(clazz,this); }
现在在MapperProxy里面已经就可以拿到SqlSession对象了,在invoke()方法里面会调用SqlSession的selectOne()方法。我们继续来完成invoke()方法。selectOne()方法有两个参数, statementId和paramater,这两个怎么拿到呢?statementId其实就是接口的全路径+方法名,中间加一个英文的点。paramater可以从方法参数中拿到(args[0])。因为我们定义的是String,还要把拿到的Object强转一下。把statementId和parameter传给SqlSession:
public class GhyMapperProxy implements InvocationHandler { private GhySqlSession sqlSession; public GhyMapperProxy(GhySqlSession sqlSession) { this.sqlSession = sqlSession; } @Override public Object invoke(Object proxy,Method method,Object[] args) throws Throwable { String mapperInterface = method.getDeclaringClass().getName(); String methodName = method.getName(); String statementId = mapperInterface +"." +methodName; return sqlSession.selectOne(statementId,args[0]); } }
到了sqlSession的selectOne()方法,这里要去调用Executor的query方法,这个时候必须传入SQL语句和parameter(根据statementId获取)。怎么根据StatementId找到我们要执行的SQL语句呢?他们之间的绑定关系我们配置在哪里?为了简便,免去读取文件流和解析XML标签的麻烦,我把SQL语句放在Properties文件里面。在resources目录下创建一个sql.properties文件。key就是接口全路径+方法名称,SQL是我们的查询SQL。参数这里,因为我们要传入一个整数,所以先用一个%d的占位符代替:
com.ghy.versionsone.mapper.UserMapper.selectOne=select * from t_user where id = %d
在sqlSession的selectOne()方法里面,我们要根据StatementId获取到SQL,然后传给Executor。这个绑定关系是放在Configuration里面的。怎么快速地解析Properties文件?为了避免重复解析,我们在Configuration创建一个静态属性和静态方法,直接解析sql.properties文件里面的所有KV键值对:
/** * 用来保存相关的配置信息 */ public class GhyConfiguration { // 存储属性文件的信息 public static final ResourceBundle sqlMappings; static { sqlMappings = ResourceBundle.getBundle("sql"); } public <T> T getMapper(Class clazz,GhySqlSession sqlSession){ return (T) Proxy.newProxyInstance(this.getClass().getClassLoader(), new Class[]{clazz}, new GhyMapperProxy(sqlSession)); } }
/**
* 对外提供的查询的方法
* @param <T>
* @return
*/
public <T> T selectOne(String statementId,Object parameter){
String sql = GhyConfiguration.sqlMappings.getString(statementId);
// String sql=statementId; //先用statementId代替SQL
System.out.println ("sql:"+sql);
if (null !=sql && !"".equals ( sql )){
return executor.query(sql,parameter);
}
return null;
}
在SqlSession中,SQL语句已经拿到了,接下来就是Executor类的query()方法,Executor是数据库操作的真正执行者。干脆直接把以前文章中写的JDBC的代码全部复制过来,职责先不用细分。参数用传入的参数替换%d占位符,需要format一下。
2.4 Executor
在Executor中我们就可以直接来执行SQL的执行了
/** * SQL语句的执行器 */ public class GhyExecutor { public <T> T query(String sql,Object parameter){ Connection conn = null; Statement stmt = null; User user = new User(); try { // Class.forName("com.mysql.jdbc.Driver"); // 打开连接 conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mybatis?characterEncoding=utf-8&serverTimezone=UTC", "root", "root"); // 执行查询 stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery(String.format(sql,parameter)); // 获取结果集 while (rs.next()) { user.setId(rs.getInt("id")); user.setUserName(rs.getString("user_name")); user.setPassword(rs.getString("password")); user.setRealName(rs.getString("real_name")); } System.out.println(user); rs.close(); stmt.close(); conn.close(); } catch (SQLException se) { se.printStackTrace(); } catch (Exception e) { e.printStackTrace(); } finally { try { if (stmt != null) { stmt.close(); } } catch (SQLException se2) { } try { if (conn != null) { conn.close(); } } catch (SQLException se) { se.printStackTrace(); } } return (T) user; } }
到这儿我们就可以来写个测试类来跑下程序了
public class Test {
public static void main(String[] args) {
GhySqlSession sqlSession = new GhySqlSession();
// sqlSession.selectOne("com.ghy.versionsone.entity.User.selectOne",1);
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.selectOne(1);
System.out.println(user);
}
}

三、不足总结
1、在Executor中,对参数、语句和结果集的处理是耦合的,没有实现职责分离;
2、参数:没有实现对语句的预编译,只有简单的格式化,效率不高,还存在SQL注入的风险;
3、语句执行:数据库连接硬编码;
4、结果集:还只能处理Blog类型,没有实现根据实体类自动映射。
git源码:https://gitee.com/TongHuaShuShuoWoDeJieJu/ljx-my-baits.git

 浙公网安备 33010602011771号
浙公网安备 33010602011771号