
目标检测论文解读12——RetinaNet
引言
这篇论文深刻分析了one-stage的模型精度比two-stage更差的原因,并提出Focal Loss提高精度。
思路
在论文中,作者指出,造成one-stage模型精度差的原因主要是:正负样本极不平衡。一张图片只有那么几个目标,但是用来分类的Anchor Box却能达到几千个,大量的样本都是负样本,而且大多数负样本都是容易分类的简单样本,这些简单样本的loss虽然低但是凭借着数量众多,能对loss有很大的贡献。因此分类器只用无脑判负也能达到不错的效果。
作者提出的Focal Loss能很好减少简单样本对梯度的影响。
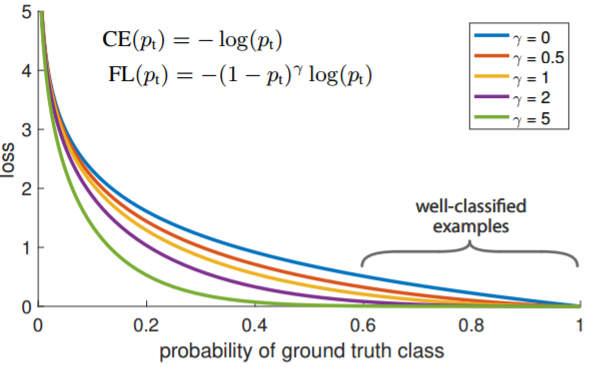
相比于传统的CE(Pt)=-log(Pt)(这里Pt代表正负样本预测正确的可能性),Focal Loss在前面乘了一项(1-Pt)^r。
为什么多了这一项就能减少简单样本对梯度的影响呢?
可以看到,Pt越接近1表示这个样本预测正确的可能性越大,也就是这个样本越简单。而(1-Pt)^r这一项,显然是随着Pt的升高而减小,也就是样本越简单,Pt越小,Focal Loss整体的值也越小。这样就能减少简单样本对梯度的影响了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号