
4.kafka API producer
1.Producer流程
首先构建待发送的消息对象ProducerRecord,然后调用KafkaProducer.send方法进行发送。KafkaProducer接收到消息后首先对其进行序列化,然后结合本地缓存的元数据信息一起发送给partitioner去确定目标分区,最后追加写入到内存中的消息缓冲池(accumulator)。此时KafkaProducer.send方法成功返回。同时,KafkaProducer中还有一个专门的Sender IO线程负责将缓冲池中的消息分批次发送给对应的broker,完成真正的消息发送逻辑。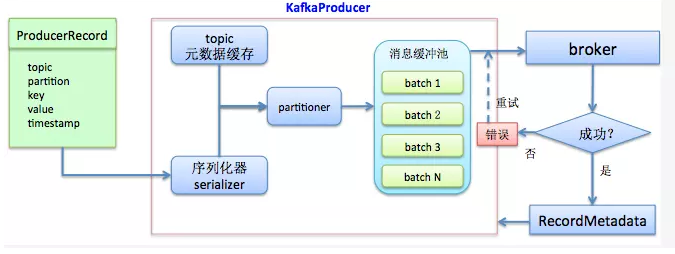
2.API 实现
2.1创建topic
bin/kafka-topics.sh --create --zookeeper h201:2181,h202:2181,h203:2181 --replication-factor 2 --partitions 3 --topic topic11
2.2创建 producer
[hadoop@h201 kkk]$ vi cp.java
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
public class cp {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Properties props = new Properties();
props.put("bootstrap.servers", "h201:9092,h202:9092,h203:9093");//kafka集群,broker-list
props.put("acks", "all");
props.put("retries", 1);//重试次数
props.put("batch.size", 16384);//批次大小
props.put("linger.ms", 1);//等待时间
props.put("buffer.memory", 33554432);//RecordAccumulator缓冲区大小
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++) {
producer.send(new ProducerRecord<String, String>("topic11", Integer.toString(i), Integer.toString(i)));
}
producer.close();
}
}
[hadoop@h201 kkk]$ /usr/jdk1.8.0_144/bin/javac -classpath /home/hadoop/kafka_2.12-0.10.2.1/libs/kafka-clients-0.10.2.1.jar cp.java
[hadoop@h201 kkk]$ /usr/jdk1.8.0_144/bin/java cp
代码解释:
3.1Properties类
继承于 Hashtable.表示一个持久的属性集.属性列表中每个键及其对应值都是一个字符串。
类中properties是配置文件,主要的作用是通过修改配置文件可以方便的修改代码中的参数,实现不用改class文件即可灵活变更参数。
3.2KafkaProducer类
用于向kafka集群发布消息记录,其中<K, V>为泛型,指明发送的消息记录key/value对的类型。
kafka producer(生产者)是线程安全的,多个线程共享一个producer实例,相比于多个producer实例,这样做的效率更高、更快。
从上述构造函数可以看出,可以通过Map和Properties两种形式传递配置信息,用于构造Producer对象,配置信息均为key/value对。
kafka的包org.apache.kafka.common.serialization中,提供了许多已经实现好的序列化和反序列化的类,可以直接使用。你也可以实现自己的序列化和反序列化类(实现Serializer接口),选择合适的构造函数构造你的Producer类。
方法: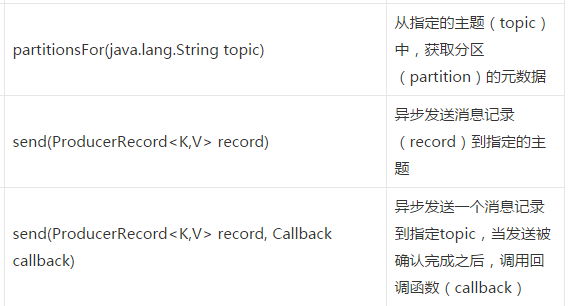
3.3 ProducerRecord
消息记录,记录了要发送给kafka集群的消息、分区等信息
topic:必须字段,表示该消息记录record发送到那个topic。
value:必须字段,表示消息内容。
partition:可选字段,要发送到哪个分区partition。
key:可选字段,消息记录的key,可用于计算选定partition。
timestamp:可选字段,时间戳;表示该条消息记录的创建时间createtime,如果不指定,则默认使用producer的当前时间。
headers:可选字段,(作用暂时不明,待再查证补充)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号