
spark 机器学习 随机森林 实现(二)
通过天气,温度,风速3个特征,建立随机森林,判断特征的优先级
结果 天气 温度 风速
结果(0否,1是)
天气(0晴天,1阴天,2下雨)
温度(0热,1舒适,2冷)
风速(0没风,1微风,2大风)
1 1:0 2:1 3:0
结果去打球 1字段:晴天 2字段:温度舒适 3字段:风速没风
[hadoop@h201 pp]$ cat pp1.txt
1 1:0 2:1 3:0
0 1:2 2:2 3:2
1 1:0 2:0 3:0
1 1:0 2:0 3:1
1 1:0 2:1 3:1
1 1:0 2:1 3:1
1 1:0 2:1 3:0
0 1:1 2:2 3:2
0 1:1 2:2 3:2
0 1:2 2:2 3:2
0 1:2 2:1 3:1
0 1:2 2:1 3:2
0 1:1 2:2 3:2
1 1:0 2:1 3:0
本例子 用官方提供代码进行更改完成
hadoop fs -put pp1.txt /
scala> import org.apache.spark.mllib.tree.RandomForest
scala> import org.apache.spark.mllib.tree.model.RandomForestModel
scala> import org.apache.spark.mllib.util.MLUtils
val data = MLUtils.loadLibSVMFile(sc, "hdfs://h201:9000/pp1.txt")
//标记点是将密集向量或者稀疏向量与应答标签相关联(结果),在MLlib中,标记点用于监督学习算法。LIBSVM是林智仁教授等开发设计的一个简单、易用和快速有效的SVM模式识别与回归的软件包。MLlib已经提供了MLUtils.loadLibSVMFile方法读取存储在LIBSVM格式文本文件中的训练数据
//数据格式 :空格分割,第一部分为结果,后面为特征向量
scala> val splits = data.randomSplit(Array(0.7, 0.3))
scala> val (trainingData, testData) = (splits(0), splits(1))
scala> val numClasses = 2
//分类数
scala> val categoricalFeaturesInfo = Map[Int, Int]()
// categoricalFeaturesInfo 为空,意味着所有的特征为连续型变量
scala> val numTrees = 3
//树的个数
scala> val featureSubsetStrategy = "auto"
//特征子集采样策略,auto 表示算法自主选取
scala> val impurity = "gini"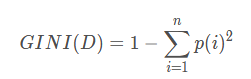
//以性别举例:性别 :1-(1/2)^2-(1/2)^2 =0.5
scala> val maxDepth = 4
//树的最大层次
scala> val maxBins = 32
//特征最大装箱数
val model = RandomForest.trainClassifier(trainingData, numClasses, categoricalFeaturesInfo,
numTrees, featureSubsetStrategy, impurity, maxDepth, maxBins)
//训练随机森林分类器
val labelAndPreds = testData.map { point =>
val prediction = model.predict(point.features)
(point.label, prediction)
}
scala> val testErr = labelAndPreds.filter(r => r._1 != r._2).count.toDouble / testData.count()
scala> println("Test Error = " + testErr)
// 测试数据评价训练好的分类器并计算错误率
scala> println("Learned classification forest model:\n" + model.toDebugString)
scala> model.save(sc, "myModelPath")
//持久化保存随机森林
scala> val sameModel = RandomForestModel.load(sc, "myModelPath")
//加载随机森林

 浙公网安备 33010602011771号
浙公网安备 33010602011771号