
spark 机器学习 ALS原理(一)
1.线性回归模型
线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归。当你使用它时,你首先假设输出变量(相应变量、因变量、标签)和预测变量(自变量、解释变量、特征)之间存在的线性关系。
(自变量是指:研究者主动操纵,而引起因变量发生变化的因素或条件,因此自变量被看作是因变量的原因。
因变量是指:在函数关系式中,某个量会随一个(或几个)变动的量的变动而变动。)
线性模型可能使用于类似下面的问题:比如你正在研究一个公司的销售额和该公司在广告上的投入之间的关系,或者某人在社交网站上的好友数量和他每天在该社交网站上花费的时间之间的关系。
理解线性回归一个切入点是先确定那条直线,我们知道,通过斜率和截距就可以完全确定一条直线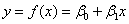
例子1:
假设 (用户数,利润值)
S={(x,y)=(1,25),(10,250),(100,2500)}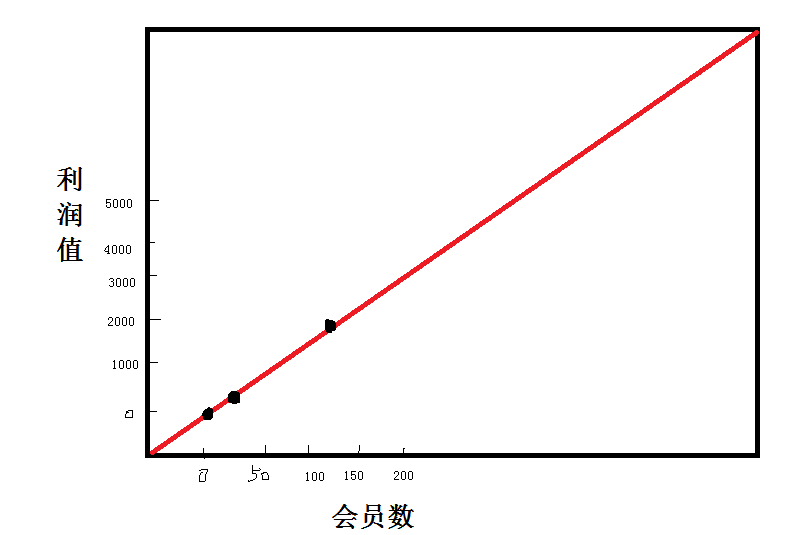
例子2:
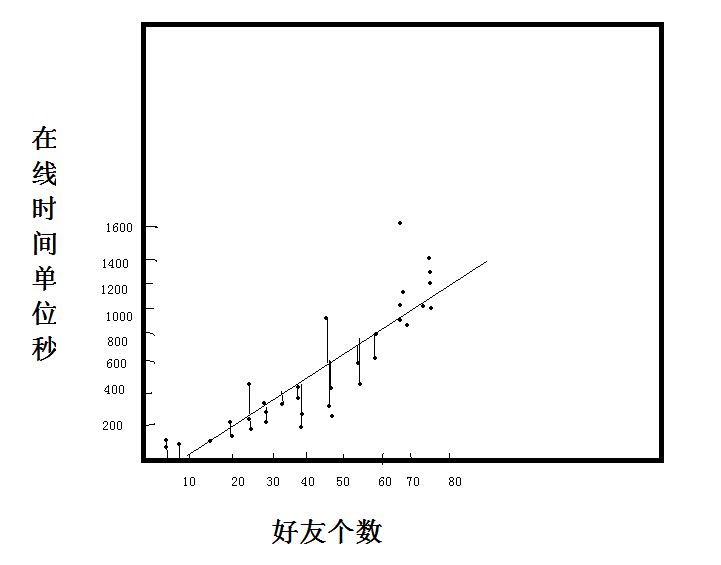
假设(好友数,在线时间)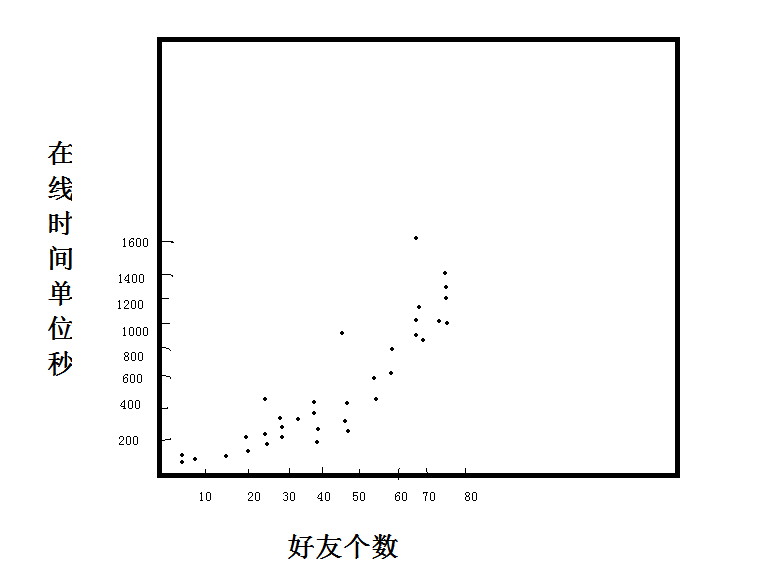
看到当前图片,很难一眼看出两个变量之间的关系了。
我们假设图中是线性关系,可以画出多条线。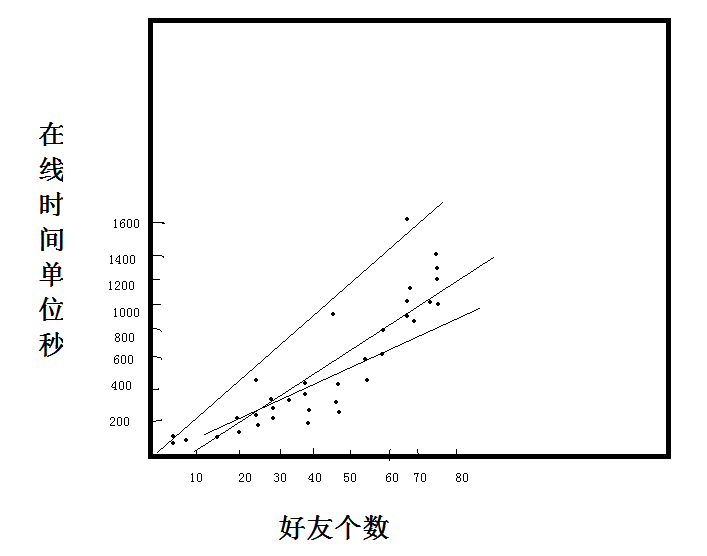
那么哪条线才是我们使用的最优线呢?这是一个拟合过程
2.spark ALS
ALS中文名作交替最小二乘法,就是在最小二乘法基础上的升级,在机器学习中,ALS特指使用最小二乘法求解的一个协同过滤算法,是协同过滤中的一种。ALS算法是2008年以来,用的比较多的协同过滤算法。从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF,因为它同时考虑了User和Item两个方面,即即可基于用户进行推荐又可基于物品
如下图所示,u表示用户,v表示商品,用户给商品打分,但是并不是每一个用户都会给每一种商品打分。比如用户u6就没有给商品v3打分,需要我们推断出来,这就是机器学习的任务。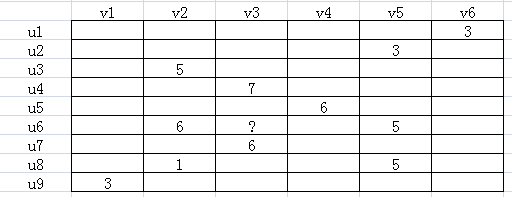
由于并不是每个用户给每种商品都打了分,可以假设ALS矩阵是低秩的,即一个m*n的矩阵,是由m*k和k*n两个矩阵相乘得到的,其中k<<m,n。
Am×n=Um×k×Vk×n
这种假设是合理的,因为用户和商品都包含了一些低维度的隐藏特征,比如我们只要知道某个人喜欢碳酸饮料,就可以推断出他喜欢百世可乐、可口可乐、芬达,而不需要明确指出他喜欢这三种饮料。这里的碳酸饮料就相当于一个隐藏特征。上面的公式中,Um×k表示用户对隐藏特征的偏好,Vk×n表示产品包含隐藏特征的程度。机器学习的任务就是求出Um×k和Vk×n。可知uiTvj是用户i对商品j的偏好,使用Frobenius范数来量化重构U和V产生的误差。由于矩阵中很多地方都是空白的,即用户没有对商品打分,对于这种情况我们就不用计算未知元了,只计算观察到的(用户,商品)集合R。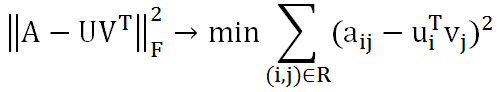
这样就将协同推荐问题转换成了一个优化问题。目标函数中U和V相互耦合,这就需要使用交替二乘算法。即先假设U的初始值U(0),这样就将问题转化成了一个最小二乘问题,可以根据U(0)可以计算出V(0),再根据V(0)计算出U(1),这样迭代下去,直到迭代了一定的次数,或者收敛为止。虽然不能保证收敛的全局最优解,但是影响不大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号