
mysql-表属性、sql语言应用、索引、执行计划
###mysql 自带帮助使用
mysql> help create database;
Name: 'CREATE DATABASE'
Description:
Syntax:
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
}
CREATE DATABASE creates a database with the given name. To use this
statement, you need the CREATE privilege for the database. CREATE
SCHEMA is a synonym for CREATE DATABASE.
URL: https://dev.mysql.com/doc/refman/5.7/en/create-database.html
mysql> show charset; ##查看数据库支持的字符集
mysql> select @@port;## 查询当前服务端口号
+--------+
| @@port |
+--------+
| 3307 |
+--------+
1 row in set (0.00 sec)
mysql> select @@port\G; #格式化显示,竖式存储
*************************** 1. row ***************************
@@port: 3307
1 row in set (0.00 sec)
表属性
存储引擎:engine =innodb
字符集:charset =utf8mb4,建议使用utf8mb4
utf8 中文占三个字节长度
Utf8mb4 中文 四个字节长度,支持存储特殊的拼音,比如uwu和U,支持emoji表情
列的属性
主键:primary key(PK) 必须唯一且非空,数字列或无关列,自增长的列适合做主键,聚集索引列;
主键是一种约束,也是一种索引类型,在一张表上只能有一个主键,可以是联合主键
非空:Not null 非空列,必填项,尽量设置not null,避免不走索引,建议配合默认值一起使用
默认值:default ,数字列默认值使用0 ,字符串使用null或nil
唯一:unique 不能重复
自增:auto_increment:针对数字列,可以自定义起始值和步幅
无符号:unsigned:针对数字列,比如负数的产生
注释:comment 描述列
sql语言应用
DDL:数据定义语言,建库、删库,表操作
mysql> create database wtl charset utf8mb4; #建库语句,指定字符集,8.0前字符集为拉丁文(latin1)瑞典
Query OK, 1 row affected (0.00 sec)
mysql> show create database wtl; #查看数据库建库语句
+----------+-----------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------+
| wtl | CREATE DATABASE `wtl` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ |
+----------+-----------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> alter database wtl1 charset utf8mb4;#数据库字符集修改
mysql> drop database wtl1; #数据库删除
#数据库名称修改方法
1、Navicat连接直接修改
2、备份原数据库,新建数据库然后还原
3、通过修改表名称,间接实现数据库名称修改
create database new_db;
rename table old_db.tb to new_db.tb;
drop database old_db;
/*表新建
AUTO_INCREMENT 自增,CHARACTER SET 字符集,UNSIGNED NULL 无符号,enum 枚举,
ROW_FORMAT = Dynamic 行格式,动态,ENGINE = InnoDB 存储引擎
*/
CREATE TABLE `mysql`.`test` (
`id` int NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '姓名',
`age` tinyint UNSIGNED NULL DEFAULT 0 COMMENT '年龄',
`gender` enum('B','G','N') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '性别',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
/*
建表规范:
1、库、表名称建议小写,Windows不区分大小写,Linux严格区分大小写
2、不能以数字或英文特殊符号开头,早期版本支持
3、不能使用mysql关键字
*/
### 修改表
alter table test add telnum char(11) not null unique comment '手机号'; ###新增列
alter table test add qq varchar(255) not null unique comment 'qq' after name ;#在指定列后面新增列,after 列名放在最后
alter table test add sid varchar(255) not null unique comment 'sid' first name ;#首列前新增列
alter table test drop telnum;##删除列
alter table test modify name varchar(128) not null;#modify修改数据类型会覆盖该列之前的属性
alter table test change gender gg char(1) not null default 'n';#修改列名和字符类型及属性
###查看建表语句
mysql> show create table user;
###查看表的列信息
mysql> desc user;
### 创建一个相同表结构空表
mysql> create table user_bak like user;
#查下一个表在哪个用户下
SELECT table_name, table_schema FROM information_schema.TABLES WHERE table_name = 'test'
###online-ddl:pt-osc
1、创建一个和源表一样表结构的新表
2、在新表执行DDL语句(空表嘛,所以。。。)
3、在源表创建三个触发器分别对应insert、update、delete操作
4、从源表拷贝数据到新表,拷贝过程中源表通过触发器把新的DML操作更新到新表中
5、rename源表到old表中,把新表rename为源表,默认最后删除源表
#sql函数
mysql> select now();#查当前时间
mysql> select sysdate();#查数据库系统时间
mysql> select database();#查当前数据库
mysql> select version();#查询版本号
sql语句
###sql执行顺序
select 开始 ----->
from 子句----->
where 子句----->
group by 子句----->
having 子句----->
order by----->
limit #limit M,N 跳过M行,显示N行
###group by 和聚合函数
###常用聚合函数:AVG()平均值 count()统计行 sum()合计 max()最大 min()最小 group_concat() 列转行
select countrycode,group_concat(district) from city group by countrycode;#列转行
having 是在where结果后再次过滤,不走索引会
mysql> select * from jobs limit 3;#显示前三行
mysql> select * from jobs limit 5,5;#跳过前五行,再显示五行
mysql> select * from jobs limit 5 offset 3;#显示5行,偏移3行,相当于显示第4-8行
information_schema
mysql> use information_schema ##数据库启动时mysql自动生成的库
Reading table information for completion of table and column names #读取表信息以完成表和列名
You can turn off this feature to get a quicker startup with -A#您可以关闭此特性,以便使用-A更快地启动
information_schema下所有表表均为元数据,无法直接查询和修改,可以通过ddl进行修改,通过show和information_schema及desc来查看元数据;
show和desc 仅能查看当前库
information_schema 可以查看全局类统计
##information_schema.table介绍,找出重要列简单说明
TABLE_SCHEMA #表所在库
TABLE_NAME #表名
ENGINE #表存储引擎
TABLE_ROWS # 表的行数
AVG_ROW_LENGTH #表的平均长度,计算占用空间
INDEX_LENGTH #索引的平均长度,索引也占用空间
#范例
#查询整个数据库中所有的库/hr库对应的表名
mysql> select table_schema,table_name from tables;
mysql> select table_schema,table_name from tables where table_schema='hr';
#查询库名和表名并对表名进行列转行
mysql> select table_schema,group_concat(table_name) from tables group by table_schema;
#统计每个库每个表的个数
select table_schema,count(table_name) from tables group by table_schema;
#统计每个库的数据量/每张表的数据量
select sum(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024/1024 table_mb,TABLE_SCHEMA from tables GROUP BY TABLE_SCHEMA
select sum(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024/1024 table_mb,TABLE_name from tables GROUP BY TABLE_name ORDER BY 1 desc
##sql拼接
mysql> select concat(user,"@","'",host,"';") from mysql.user;#字符串拼接,不带引号取表数据
+--------------------------------+
| concat(user,"@","'",host,"';") |
+--------------------------------+
| mysql.session@'localhost'; |
##通过拼接实现部分数据库备份表语句mysqldump -uroot -p1 -P3307 -S /data/3307/mysql.sock mysql user >/tmp/mysql_user.sql;
SELECT
CONCAT( "mysqldump -uroot -p1 ", t.TABLE_SCHEMA, ' ', t.TABLE_NAME, "> /tmp/", t.TABLE_SCHEMA, "_", t.TABLE_NAME, ".sql;" )
FROM
information_schema.TABLES t
WHERE
t.TABLE_SCHEMA NOT IN (
'sys',
'information_schema',
'performance_schema')
show命令
show databases/tables #查看库/表语句
show create databases/tables#查看建库/表语句
show grants for root@'localhost' #查看用户权限信息
show charset #查看数据库所有字符集
show collation #查看校对规则
show full processlist #查看数据库连接
show status like '%%' #查看数据库状态
show variables like '%%' #查看数据库变量情况
show engines #查看所有支持的存储引擎
show engine innodb status\G; #查看所有innodb存储引擎状态
show binary logs #查看二进制日志情况
show binlog events in #查看二进制日志事件
show relaylog events in #查看relay日志事件
show slave status #查看从库状态
show master status #查看数据库binlog位置
索引
###压力测试数据准备
create table t100w (id int,num int,k1 char(2),k2 char(4),dt TIMESTAMP) charset utf8mb4 collate utf8mb4_bin;
mysql> delimiter //
CREATE PROCEDURE rand_data(in num int)
BEGIN
DECLARE str char(62) DEFAULT 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
DECLARE str2 char(2);
DECLARE str4 char(4);
DECLARE i int DEFAULT 0;
while i<num DO
set str2=CONCAT(SUBSTRING(str,1+FLOOR(RAND()*61),1),SUBSTRING(str,1+FLOOR(RAND()*61),1));
set str4=CONCAT(SUBSTRING(str,1+FLOOR(RAND()*61),2),SUBSTRING(str,1+FLOOR(RAND()*61),2));
set i=i+1;
INSERT into t100w VALUES(i,FLOOR(rand()*num),str2,str4,now());
end WHILE ;
END;
//
delimiter ;
mysql> call rand_data(1000000);
#压力测试语句
[root@db01 tmp]# mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' query="select * from test.t100w where k2='TUuv'" engine=innodb --number-of-queries=2000 -uroot -p1 --verbose
/*
mysqlslap #mysql自带的压力测试工具
--defaults-file=/etc/my.cnf
--concurrency=100 # 100个并发
--iteration=1 #重复次数
--create-schema='test' query="select * from test.t100w where k2='TUuv'" #连接的库和执行的语句
engine=innodb
--number-of-queries=2000 #一共运行2000次
-uroot -p1 --verbose #用户名密码
会统计出执行2000次后总计耗时
*/
索引种类
B树索引
Hash索引
R树
Full text
GIS
B树索引
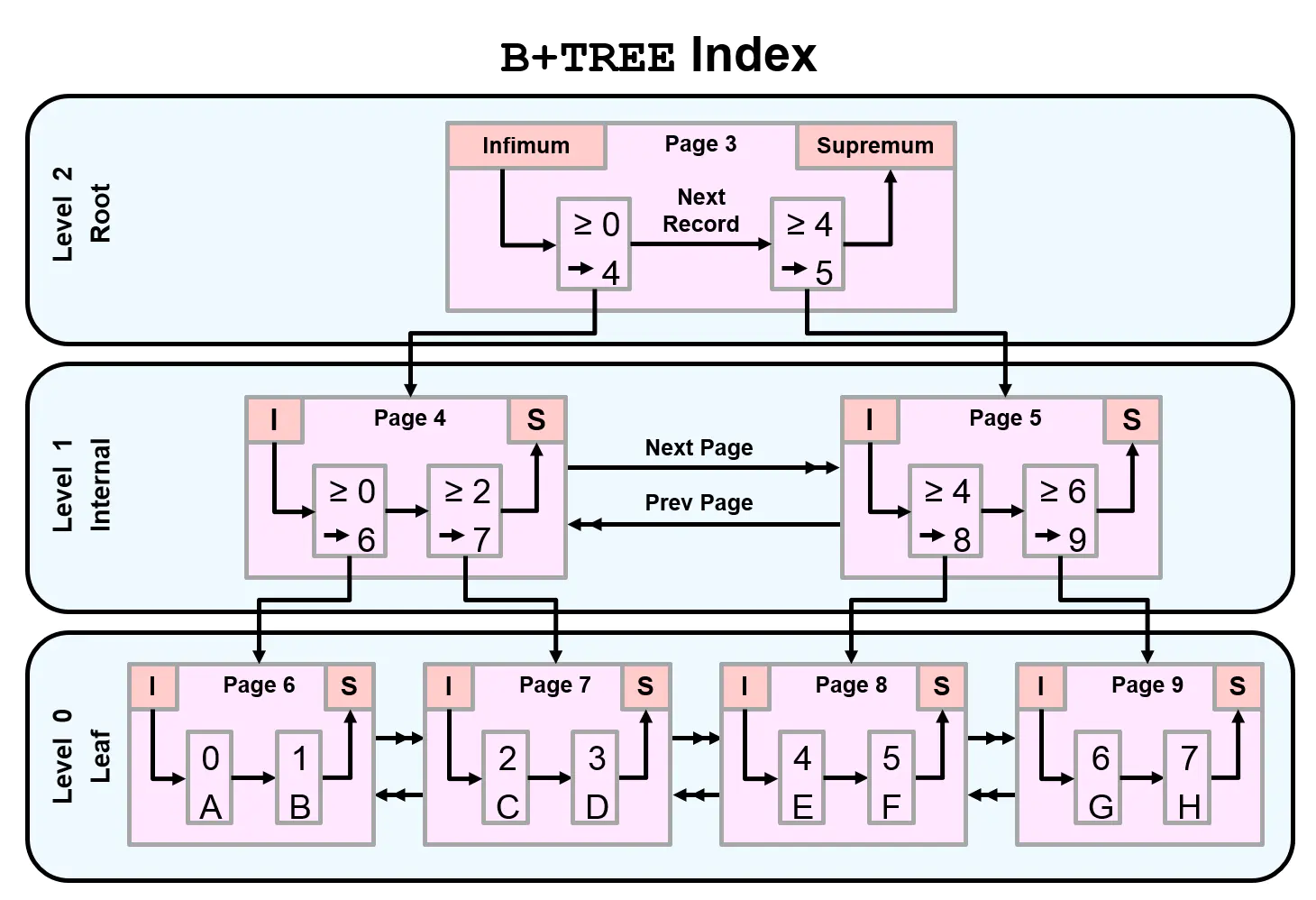
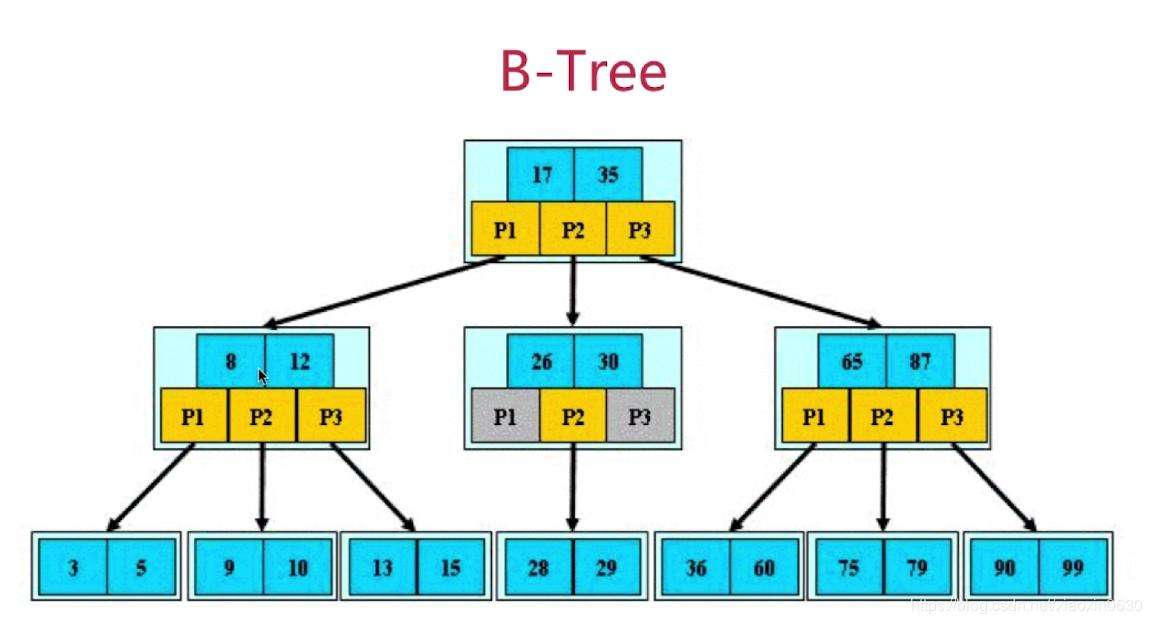
b-tree:平衡多路查找树,将数据分为三级,本层层最小值作为上层的标识,比如要查找18则首先判断18大于5且小与28,然后判断18大于10小与20,最后在下一节点内找到18,根据索引再去查找数据
b+tree:基于b-tree优化,在底层新增了一个键值,存储相邻节点的索引信息,如果所查找的数值在前后页则可以直接通过标识跳转,不需要再重新走判断, 在范围查询方面提供了更好的性能(> < >= <= like)
b*tree:在b+的基础上给第二层增加了标识,通能雷同
mysql目前默认使用b*tree索引算法
辅助索引(S)怎么构建b树结构
(1). 索引是基于表中,列(索引键)的值生成的B树结构
(2). 首先提取此列所有的值,进行自动排序
(3). 将排好序的值,均匀的分布到索引树的叶子节点中(16K)
(4). 然后生成此索引键值所对应得后端数据页的指针
(5). 生成枝节点和根节点,根据数据量级和索引键长度,生成合适的索引树高度
id name age gender
select * from t1 where id=10;
问题: 基于索引键做where查询,对于id列是顺序IO,但是对于其他列的查询,可能是随机IO.
聚集索引
(1)表中设置了主键,主键列就会自动被作为聚集索引.
(2)如果没有主键,会选择唯一键作为聚集索引.
(3)聚集索引必须在建表时才有意义,一般是表的无关列(ID)
(1) 在建表时,设置了主键列(ID)
(2) 在将来录入数据时,就会按照ID列的顺序存储到磁盘上.(我们又称之为聚集索引组织表)
(3) 将排好序的整行数据,生成叶子节点.可以理解为,磁盘的数据页就是叶子节点
聚集索引和辅助索引构成区别
聚集索引只能有一个,非空唯一,一般时主键
辅助索引,可以有多个,时配合聚集索引使用的
聚集索引叶子节点,就是磁盘的数据行存储的数据页
MySQL是根据聚集索引,组织存储数据,数据存储时就是按照聚集索引的顺序进行存储数据
辅助索引,只会提取索引键值,进行自动排序生成B树结构
辅助索引分类
单列辅助索引
联合多列辅助索引(覆盖索引)
唯一索引
关于索引树高度受什么影响
1、数据行较多,可以分表
2、索引列字符长度,使用前缀索引
3、char varchar,避免类型不合理
4、enum 优化索引高度,能用则用
索引管理
#索引创建
mysql> alter table t100w add index idx_k2(k2);
###索引查看
mysql> desc t100w;#desc直接跟表名就行,key:mul辅助索引、pri:主键、唯一主键 uni 唯一索引
+-------+-----------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-----------+------+-----+-------------------+-----------------------------+
| id | int(11) | YES | | NULL | |
| num | int(11) | YES | | NULL | |
| k1 | char(2) | YES | | NULL | |
| k2 | char(4) | YES | MUL | NULL | |
| dt | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------+-----------+------+-----+-------------------+-----------------------------+
5 rows in set (0.00 sec)
mysql> show index from t100w\G;#查询索引详细信息
*************************** 1. row ***************************
Table: t100w
Non_unique: 1
Key_name: idx_k2
Seq_in_index: 1
Column_name: k2
Collation: A
Cardinality: 3665
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
1 row in set (0.00 sec)
mysql> alter table t100w add index idx_k1(k1(1));#创建前缀索引,数字是从左到右几位
mysql> alter table city add index idx_co_po(countrycode,population);#联合索引
mysql> alter table t100w drop index idx_k1;#根据索引名称删除索引即可
索引建立原则
为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。那么索引设计原则又是怎样的?
1、 建表时一定要有主键,一般是个无关列,id或uuid等
#选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
优化方案:
(1) 如果非得使用重复值较多的列作为查询条件(例如:男女),可以将表逻辑拆分
(2) 可以将此列和其他的查询类,做联和索引
select count(*) from world.city;
select count(distinct countrycode) from world.city;
select count(distinct countrycode,population ) from world.city;
###为经常需要where 、ORDER BY、GROUP BY,join on等操作的字段建立索引
###如果索引字段值比较长,尽量使用前缀索引
### 限制索引的数目
索引的数目不是越多越好。可能会产生的问题:
(1) 每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
(2) 修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
(3) 优化器的负担会很重,有可能会影响到优化器的选择.
#percona-toolkit中有个工具,专门分析索引是否有用
### 删除不再使用或者很少使用的索引
pt-duplicate-key-checker
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
### 大表加索引,要在业务不繁忙期间操作
### 尽量少在经常更新值的列上建索引
不走索引的情况
1、没有查询条件,或者查询条件没有建立索引
2、查询结果集是原表中的大部分数据,应该是25%以上。
3、索引本身失效,统计数据不真实,索引会自行维护,如果表内容变更频繁就会出现索引失效
4、查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
5、隐式转换导致索引失效.这一点应当引起重视,在值不加单引号时可能会出发隐式转换
6、<> ,not in 不走索引(辅助索引情况下)
7、like "%_" 百分号在最前面不走
关于联合索引
where a group by b order by c ;建立索引顺序应该是abc
where a and b and c:都是等值的情况下,5.5版本后优化器会调整索引顺序,将唯一值多的列放在最左侧;在包含不等值的情况下将等值的写在左侧,不等值的写后面;
执行计划
##执行计划简介:上线新语句前对语句性能进行评估预警,出现性能问题时分析合理的解决思路
#获取sql执行计划
desc select * from t100w where id=1;
mysql> explain select * from t100w where id=1\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE #查询类型
table: t100w #查询表名
partitions: NULL
type: ALL #索引应用类型或级别
possible_keys: NULL #可能会使用到的索引
key: NULL #实际使用的索引
key_len: NULL #联合索引有关的,索引长度,覆盖越多越好
ref: NULL
rows: 955044 #查询行数,越少越好
filtered: 10.00 #过滤的信息
Extra: Using where #额外的信息
###Extra: Using filesort,索引默认会排序,如果使用了索引还是用排序就会出现重复操作
##执行计划分析
type: #索引应用类型或级别,按照顺序由下往上,越下性能越好
ALL:全表扫描,不走索引(没建索引、索引没命中),*、<>(辅助索引)、like'%%'、not in 都不走索引,后面%会走索引
index:全索引扫描,查询索引列的数据
range:索引范围扫描,< > >= <= like ' %'可以走range,in和or不走
ref:辅助索引等值查询
eq_req:在多表连接查询时on的条件列是唯一索引或主键索引
const\system:主键或唯一键等值查询
null:查不到数据时

 浙公网安备 33010602011771号
浙公网安备 33010602011771号