

flink系列-6、Time & Window
一、Time & Watermark
1.1、Flink 支持的三种 time
- DataStream 有大量基于 time 的 operator
- Flink支持三种 time:
- EventTime
- IngestTime
- ProcessingTime
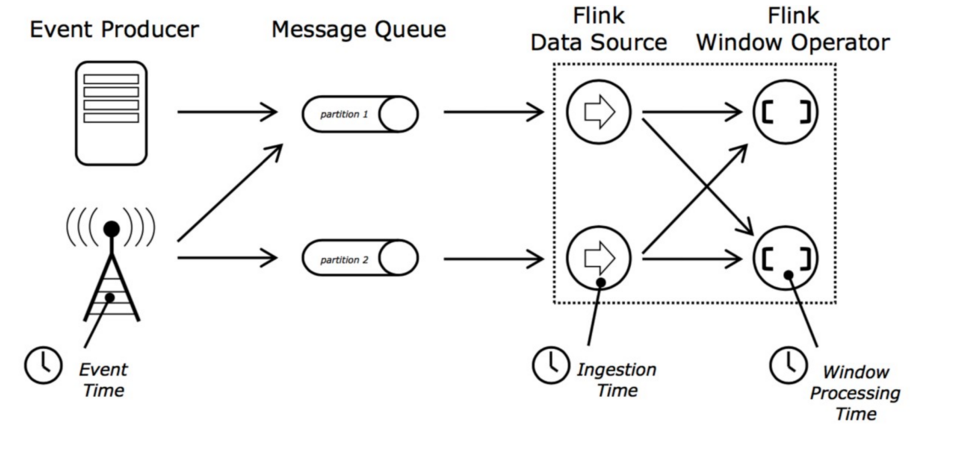
1、三个时间的比较
- EventTime
- 事件生成时的时间,在进入 Flink 之前就已经存在,可以从 event 的字段中抽取
- 必须指定 watermarks 的生成方式
- 优势:确定性,乱序、延时、或者数据重复等情况,都能给出正确的结果
- 弱点:处理无序事件时性能和延迟受到影响
- IngestTime
- 事件进入 flink 的时间,即在 source 里获取的当前系统的时间,后续操作统一使用该时间
- 不需要指定 watermarks 的生成方式(自动生成)
- 弱点:不能处理无序事件和延迟数据
- ProcessingTime
- 执行操作的机器的当前系统时间(每个算子都不一样)
- 不需要流和机器之间的协调
- 优势:最佳的性能和最低的延迟
- 弱点:不确定性 ,容易受到各种因素影像(event 产生的速度、到达 flink 的速度、在算子之间传输速度等),压根就不管顺序和延迟
- 比较
- 性能: ProcessingTime> IngestTime> EventTime
- 延迟: ProcessingTime< IngestTime< EventTime
- 确定性: EventTime> IngestTime> ProcessingTim
2、设置Time的类型
val env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
不设置 Time 类型时,默认就是 processingTime

1.2、Watermarks
实时系统中,由于各种原因造成的延时,造成某些消息发到 flink 的时间延时于事件产生的时间。如果基于 event time 构建 window,但是对于 late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了。这个特别的机制,就是 watermark 。
在上面的时间类型中我们知道,Flink 中的时间:
- EventTime 每条数据都携带时间戳;
- ProcessingTime 数据不携带任何时间戳的信息;
- IngestionTime 和 EventTime 类似,不同的是 Flink 会使用系统时间作为时间戳绑定到每条数据,可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。
- 所以,我们在处理消息乱序的情况时,会用 EventTime 和 WaterMark 进行配合使用。
水印的出现是为了解决实时计算中的数据乱序问题,它的本质是 DataStream 中一个带有时间戳的元素。如果 Flink 系统中出现了一个 WaterMark T,那么就意味着 EventTime < T 的数据都已经到达,窗口的结束时间和 T 相同的那个窗口被触发进行计算了。
也就是说:水印是 Flink 判断迟到数据的标准,同时也是窗口触发的标记。
在程序并行度大于 1 的情况下,会有多个流产生水印和窗口,这时候 Flink 会选取时间戳最小的水印。
可以考虑一个这样的例子:某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A 用户在 11:02 对 App 进行操作,B 用户在 11:03 操作了 App,但是 A 用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到 B 用户 11:03 的消息,然后再接受到 A 用户 11:02 的消息,消息乱序了。那我们怎么保证基于 event-time 的窗口在销毁的时候,已经处理完了所有的数据呢?这就是 watermark 的功能所在。watermark 会携带一个单调递增的时间戳 t,watermark(t) 表示所有时间戳不大于 t 的数据都已经到来了,未来不会再来,因此可以放心的触发和销毁窗口了。
1、Watermark 传播
-
watermark 以广播的形式在算子之间进行传播。比如说上游的算子,它连接了三个下游的任务,它会把自己当前的收到的 watermark 以广播的形式传到下游。
-
如果在程序里面收到了一个 Long.MAX_VALUE 这个数值的 watermark,就表示对应的那一条流的一个部分不会再有数据发过来了,它相当于就是一个终止的一个标志。
-
对于单流而言,一个原则是:单输入取其大,多输入取小。
有序流中Watermarks
- 在某些情况下,基于 Event Time 的数据流是有续的
- 在有序流中,watermark 就是一个简单的周期性标记。
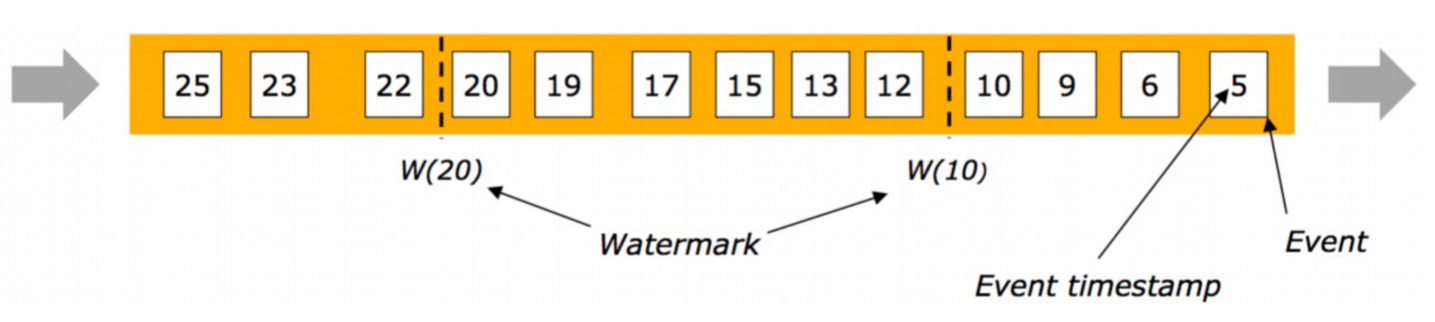
乱序流中 Watermarks
- 在更多场景下,基于 Event Time 的数据流是无续的
- 在无序流中,watermark 至关重要,它告诉 operator 比 watermark 更早(更老/时间戳更小)的事件已经到达, operator 可以将内部事件时间提前到 watermark 的时间戳(可以触发window计算)
![]()

并行流中的 Watermarks
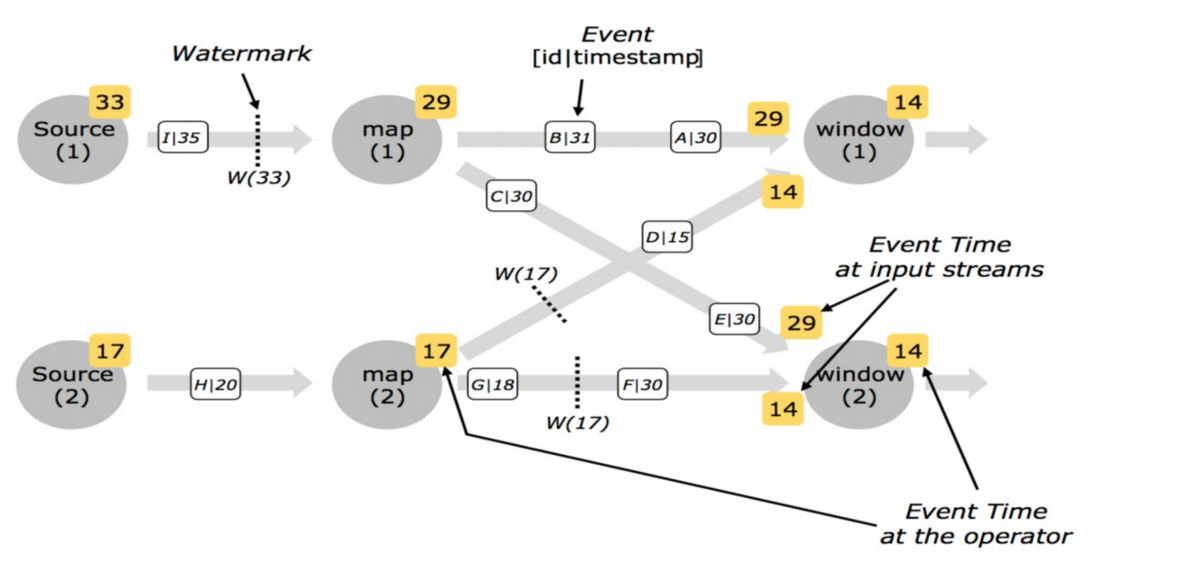
- 通常情况下, watermark 在 source 函数中生成,但是也可以在 source 后任何阶段,如果指定多次后面会覆盖前面的值。 source 的每个 sub task 独立生成水印
- watermark 通过 operator 时会推进 operators 处的当前 event time,同时 operators 会为下游生成一个新的 watermark
- 多输入 operator(union、 keyBy) 的当前 event time 是其输入流 event time 的最小值
1.3、迟到的数据
- 上面的 watermark 能够应对乱序的数据,但是真实世界中没法得到一个完美的 watermark 数值,要么没法获取到,要么耗费太大。
- 因此实际工作中会使用近似 watermark,生成 watermark(t) 之后,还有较小的概率接受到时间戳 t 之前的数据,在 Flink 中将这些数据定义为 “late elements”。
- 同样可以在 window 中指定是允许延迟的最大时间(默认为 0),可以使用下面的代码进行设置:
![]()
- 设置 `allowedLateness` 之后,迟来的数据同样可以触发窗口,进行输出,利用 Flink的 side output 机制,我们可以获取到这些迟到的数据,使用方式如下:
![]()
- 需要注意的是,设置了 allowedLateness 之后,迟到的数据也可能触发窗口,对于Session window 来说,可能会对窗口进行合并,产生预期外的行为。


1.4、生成 Timestamp 和 Watermark
1、在 SourceFunction 中产生
- 相当于把整个的 timestamp 分配和 watermark 生成的逻辑放在流处理应用的源头。
- 自定义 source 实现 SourceFunction 接口或者继承 RichParallelSourceFunction 。
- 通过 collectWithTimestamp 方法发送一条数据,其中第一个参数是发送的数据,第二个参数就是这个数据所对应的时间戳;
- 也可以调用 emitWatermark 方法去产生一条 watermark,表示接下来不会再有时间戳小于等于这个数值记录。
![]()

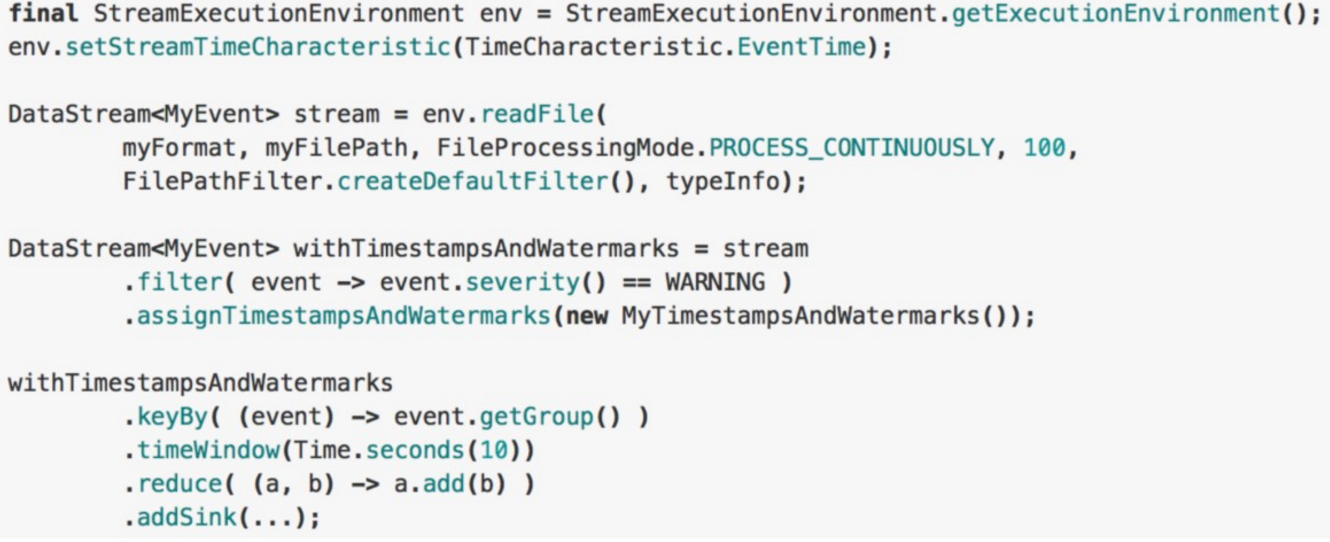
2、使用 DataStream API 的时候指定
- 调用 DataStream.assignTimestampsAndWatermarks 这个方法,能够接收不同的 timestamp 和 watermark 的生成器。
- 一般在 datasource 后调用 assignTimestampsAndWatermarks,也可以在第一个基于 event time 的 operator 之前指定(例如 window operator) 。
![]()
- assignTimestampsAndWatermarks
- 含义:提取记录中的时间戳作为 Event time,主要在 window 操作中发挥作用,不设置默认就是 ProcessingTime 。
- 限制:只有基于 event time 构建 window 时才起作用 。
- 使用场景:当你需要使用 event time 来创建 window 时,用来指定如何获取 event 的时间戳。
3、总体上而言生成器可以分为两类:第一类是定期生成器;第二类是根据一些在流处理数据流中遇到的一些特殊记录生成的。
Periodic Watermarks
- 基于Timer
- ExecutionConfig.setAutoWatermarkInterval(msec) (默认是 200ms, 设置 watermarker 发送的周期)
- 实现AssignerWithPeriodicWatermarks 接口
Puncuated WaterMarks
- 基于某些事件触发 watermark 的生成和发送(由用户代码实现,例如遇到特殊元素)
- 实现 AssignerWithPuncuatedWatermarks 接口
二、Window
什么是windows,以及windows的作用
- Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流 处理和批处理。而窗口(window)就是从 Streaming 到 Batch 的一个桥 梁。Flink 提供了非常完善 的窗口机制,这是Flink 最大的亮点之一(其他的亮点包括消息乱序处理,和 checkpoint 机制)。
- Window是一种切割无限数据集为有限块并进行相应计算的处理手段(跟keyBy一样,也是一种分组手段,只不过同一event可能被分到多个组)
- 在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们 可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处 理,例如:在过去的1分钟内 有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的 数据,并对这个窗口内的数据进行计算。
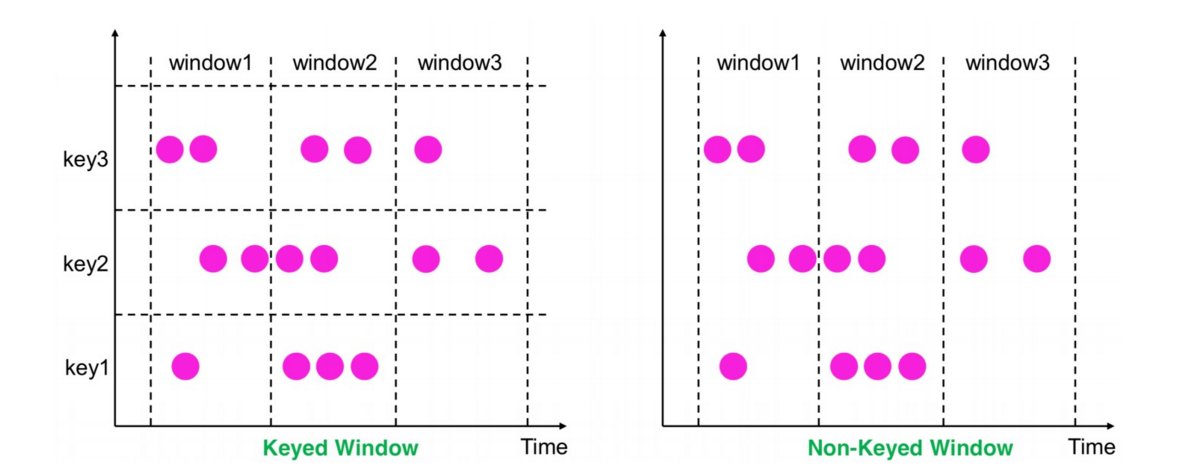
Window分类,分为Keyed Windows和Non-Keyed Windows,取决于是否使用了keyBy
- Keyed Windows(在已经按照key分组的基础上(KeyedStream),再构建多任务并行window)

- Non-Keyed Windows(在未分组的DataStream上构建单任务window,并行度是1,API都带All后缀)

WindowedStream & AllWindowedStream
- WindowedStream代表了根据key分组,并且基于WindowAssigner切分窗口的数据流。所以WindowedStream都是从KeyedStream衍生而来的。而在WindowedStream上 进行任何transformation也都将转变回DataStream。
val stream: DataStream[MyType] = ... val windowed: WindowedDataStream[MyType] = stream .keyBy("userId") .window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data 5 秒计算一次 val result: DataStream[ResultType] = windowed.reduce(myReducer)
- 上述 WindowedStream 的样例代码在运行时会转换成如下的执行图:
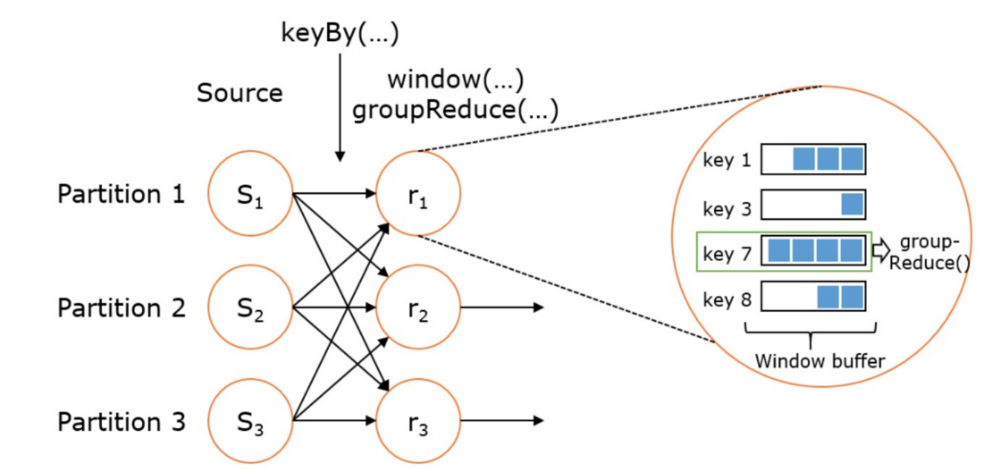
- Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中。当到达窗口发送的条件时,Flink 会对整个窗口中的数据进行处理(由Trigger控制)。Flink 在聚合类窗口 有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。
- 在key分组的流上进行窗口切分是比较常用的场景,也能够很好地并行化(不同的key上的窗口聚合可以分配到不同的task去处理)。不过有时候我们也需要在普通流上进 行窗口的操作,这就是 AllWindowedStream。AllWindowedStream是直接在DataStream上进行windowAll(...)操作。AllWindowedStream 的实现是基于 WindowedStream 的(Flink 1.1.x 开始)。Flink 不推荐使用AllWindowedStream,因为在普通流上进行窗口操作,就势必需要将所有分区的流都汇集到单个的Task中, 而这个单个的Task很显然就会成为整个Job的瓶颈。
Keyed Windows 对比 Non-Keyed Windows(以基于time的window为例)
Window的生命周期
- 创建:当属于该窗口的第一个元素到达时就会创建该窗口
- 销毁:当时间(event/process time)超过窗口的结束时间戳+用户指定的延迟时
- (allowedLateness()),窗口将被移除(仅限time-based window)
- 例如:对于一个每5分钟创建Tumbling Windows(即翻滚窗口)窗口,允许1分钟的时延,Flink将会在12:00到12:05这段时间内第一个元素到达时创建窗口,当 watermark超过12:06时,该窗口将被移除
- Trigger(触发器):指定了窗口函数在什么条件下可被触发,触发器还可以决定在创建和删除窗口之间的任何时间清除窗口的内容。在这种情况下,清除仅限于窗口中的元 素,而不是窗口元数据。这意味着新数据仍然可以添加到该窗口中。
- 例如:当窗口中的元素个数超过4个时“ 或者 ”当水印达到窗口的边界时“触发计算
- Evictor(驱逐者):将在触发器触发之后或者在函数被应用前后,清除窗口中的元素
- Window 的函数:函数里定义了应用于窗口(Window)内容的计算逻辑
窗口分配器(Window Assingers)
- Window Assinger是干啥的
- 当你决定stream是否keyby之后,window是没有构建的,你还需要指定一个window Assinger 用于定义元素如何分配到窗口中
- window Assinger如何指定?
- Keyedstream:window(WindowAssigner)
- non-keyed streams:windowAll(WindowAssigner)
- window Assinger的作用:负责将每个传入的元素分配给一个或多个窗口
Window分类(Window Assinger类型)
- 有了window Assinger,才会创建出各种形式的window来覆盖我们所需的各种场景,所以不用 过多关注window本身的分类,关注window Assinger的分类即可
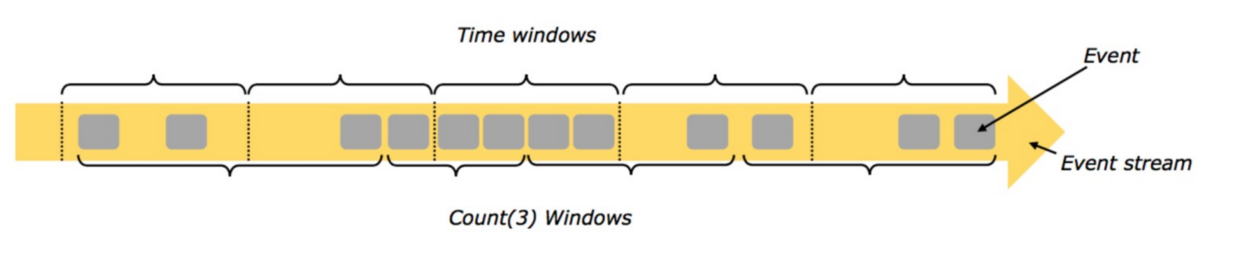
- Count-based window:根据元素个数对数据流进行分组切片
- Tumbling CountWindow
- Sliding CountWindow
- Time-based window :根据时间对数据流进行分组切片,设置方式window(start,end)
- Tumbling Window
- Sliding Window
- Session Window
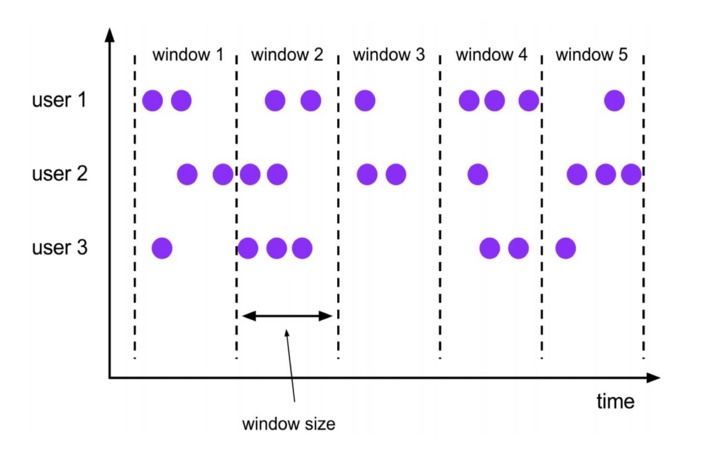
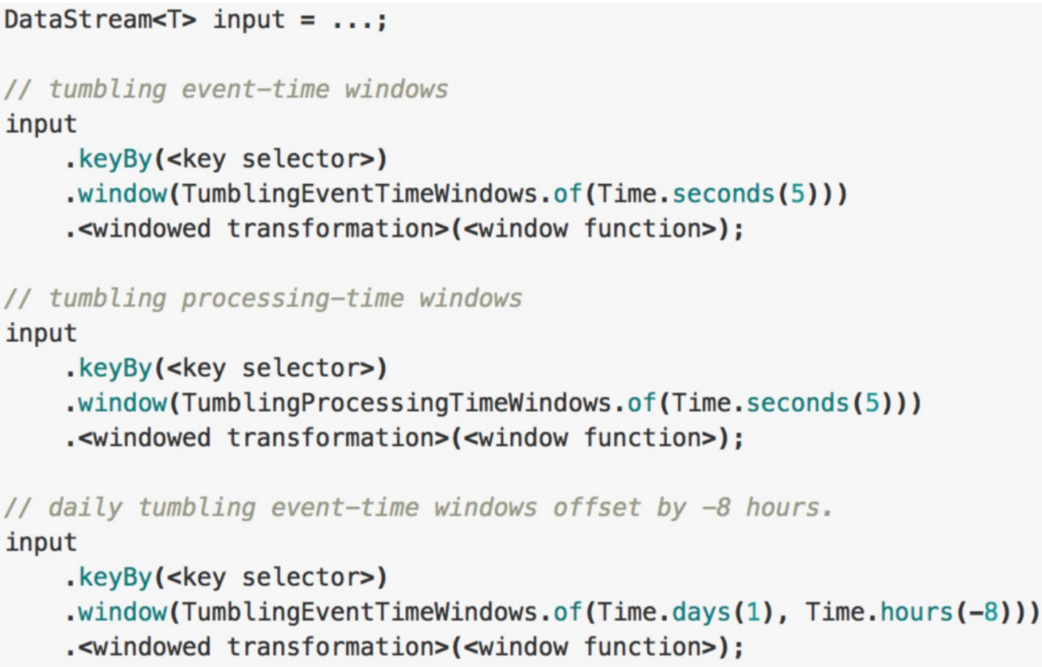
Tumbling Windows(翻滚窗口)
- 定义:将数据依据固定的窗口长度对数据进行切片
- 特点:
- 时间对齐
- 窗口长度固定
- event无重叠
- 适用场景:计算各个时间段的指标
Tumbling Windows的使用
- 对齐方式:默认是aligned with epoch(整点、整分、整秒等),可以通过offset参数改变对齐方式
Sliding Windows(滑动窗口)
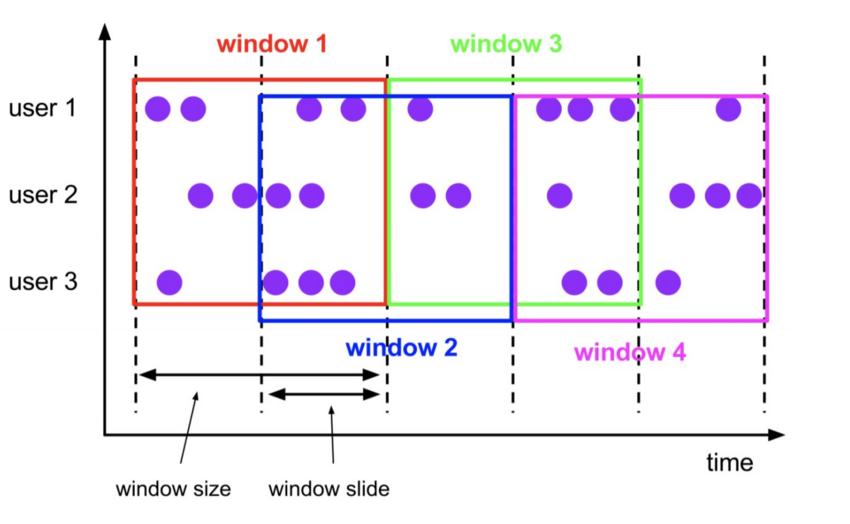
- 定义:是固定窗口的更广义的一种形式。滑动窗口由固定的窗口长度和滑动间隔组成
- 特点:
- 时间对齐
- 窗口长度固定
- event有重叠
- 适用场景:每5分钟求统计一小时的数据
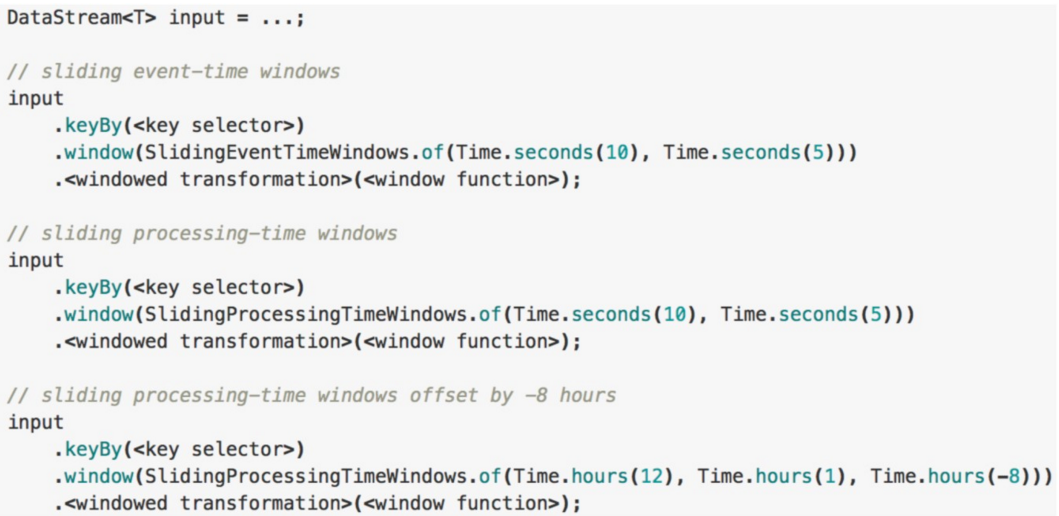
Sliding Windows的使用
-
对齐方式:默认是aligned with epoch(整点、整分、整秒等),可以通过offset参数改变对齐方式
Session Windows(事件窗口)
- 定义:类似于web应用 的session,即一段时间没有接受到新数据就会生成新的窗口(固定gap/gap fun)
- 特点:
- 时间无对齐
- event不重叠
- 没有固定开始和结束时间
- 适用场景:基于用户行为进行统计分析

Session Windows的使用
- Gap
- 固定gap
- 动态gap:实现SessionWindowTimeGapExtractor
- 特殊处理方式
- session window operator为每个到达的event创建一个新窗口,如果它们之间的距离比定义的间隔更近,则将窗口合并在一起
- 为了能够合并, session window operator需要合并触发器和合并窗口函数,例如ReduceFunction、 AggregateFunction或ProcessWindowFunction (FoldFunction 不能合并)

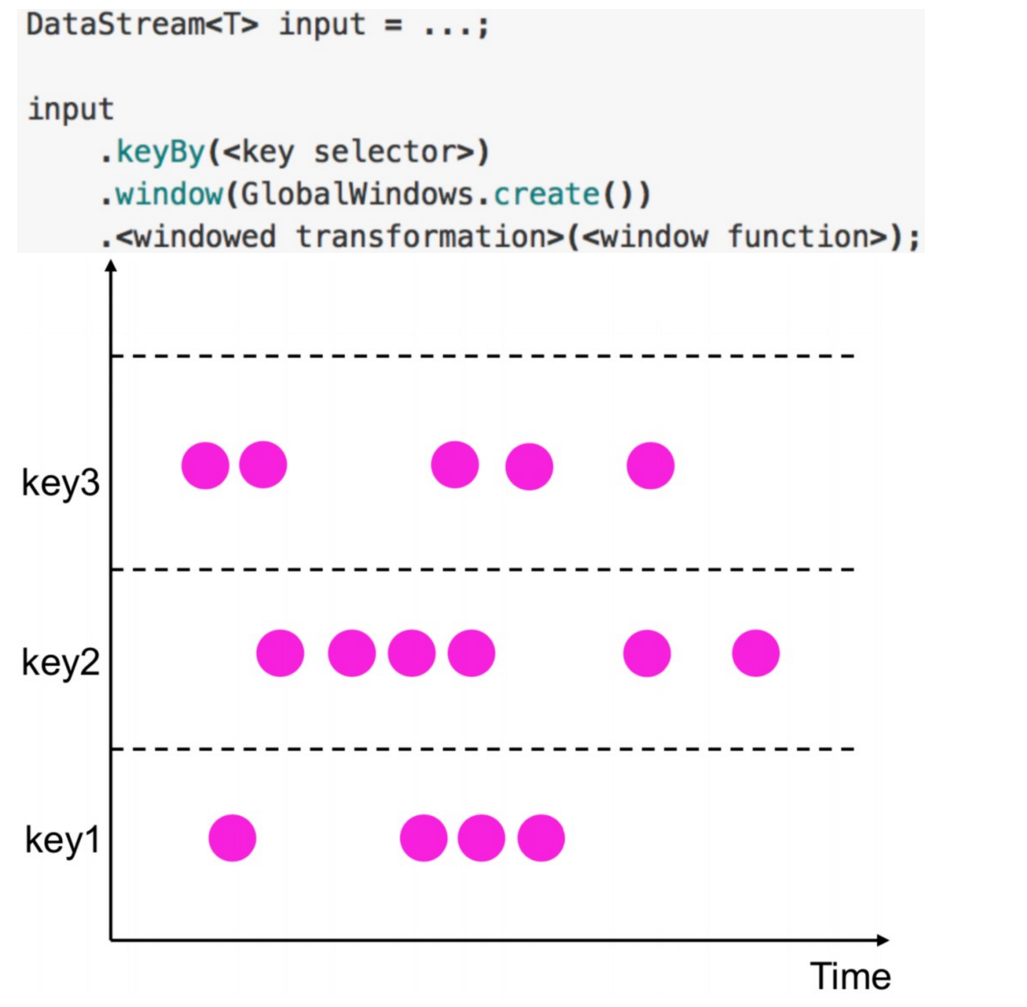
Global Windows
- 定义:有相同key的所有元素分配给相同的单个全局窗口
- 必须指定自定义触发器否则没有任何意义
- 注意:不要跟Non-keyed Window搞混,两个不同的角度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号