

高并发下缓存失效问题--缓存穿透、雪崩、击穿
缓存穿透:
指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的null写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义
风险:
利用不存在的数据进行攻击,数据库瞬时压力增大,最终导致崩溃
解决:
-
null结果缓存,并加入短暂过期时间
实现null结果缓存,可以使用Spring CaChe:
# 是否缓存空值 ===> 防止缓存穿透
spring.cache.redis.cache-null-values=true
-
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,查询不存在的数据会被这个 bitmap 拦截掉,从而避免了对 DB 的查询压力
布隆过滤器的原理:当一个元素被加入集合时,通过K个哈希函数将这个元素映射成一个位数组中的K个点,把它们置为1。查询时,将元素通过哈希函数映射之后会得到k个点,如果这些点有任何一个0,则被检元素一定不在,直接返回;如果都是1,则查询元素很可能存在,就会去查询Redis和数据库。
布隆过滤器一般用于在大数据量的集合中判定某元素是否存在。
缓存雪崩:
缓存雪崩是指在我们设置缓存时key采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。
解决:
-
原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
可使用Spring Cache实现:
# 毫秒
spring.cache.redis.time-to-live=3600000 -
加锁排队可以起到缓冲的作用,防止大量的请求同时操作数据库,但它的缺点是增加了系统的响应
时间,降低了系统的吞吐量,牺牲了一部分用户体验。当缓存未查询到时,对要请求的 key 进行加锁,只允许一个线程去数据库中查,其他线程等候排队。
-
设置二级缓存。二级缓存指的是除了 Redis 本身的缓存,再设置一层缓存,当 Redis 失效之后,先去查询二级缓存。例如可以设置一个本地缓存,在 Redis 缓存失效的时候先去查询本地缓存而非查询数据库。
缓存击穿:
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落到db,我们称为缓存击穿。
解决:
-
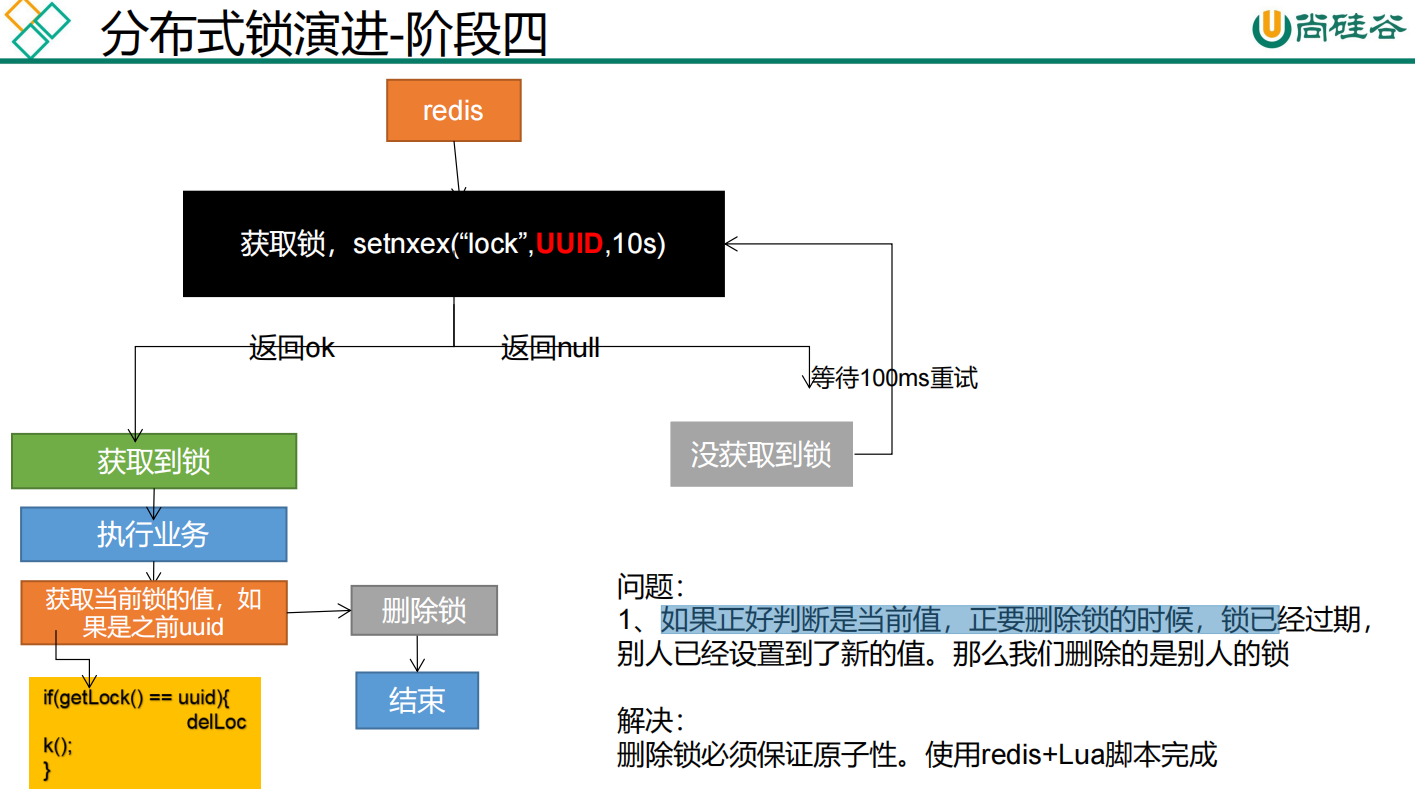
加互斥锁。在并发的多个请求中,只有第一个请求线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程将数据写入缓存后,直接走缓存。可以使用Redis分布式锁实现,
![]()
![]()
![]()
![]()
![]()
![]()
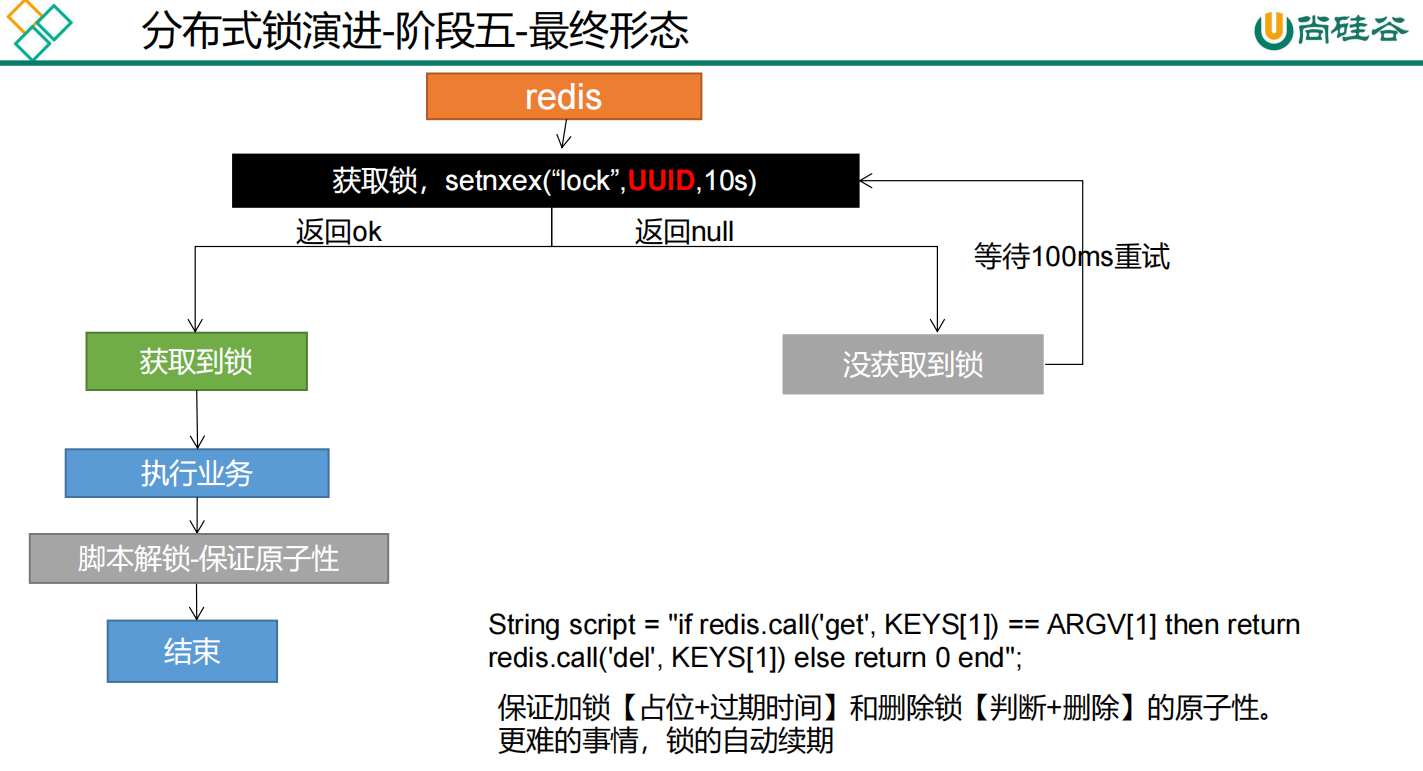
两个保证:
-
占分布式锁时,设置过期时间,必须和加锁===>>>是原子操作
-
删除锁时,获取值对比+对比成功删除 = 原子操作 lua脚本解锁
使用【redis+Lua脚本】来实现
代码如下:
-
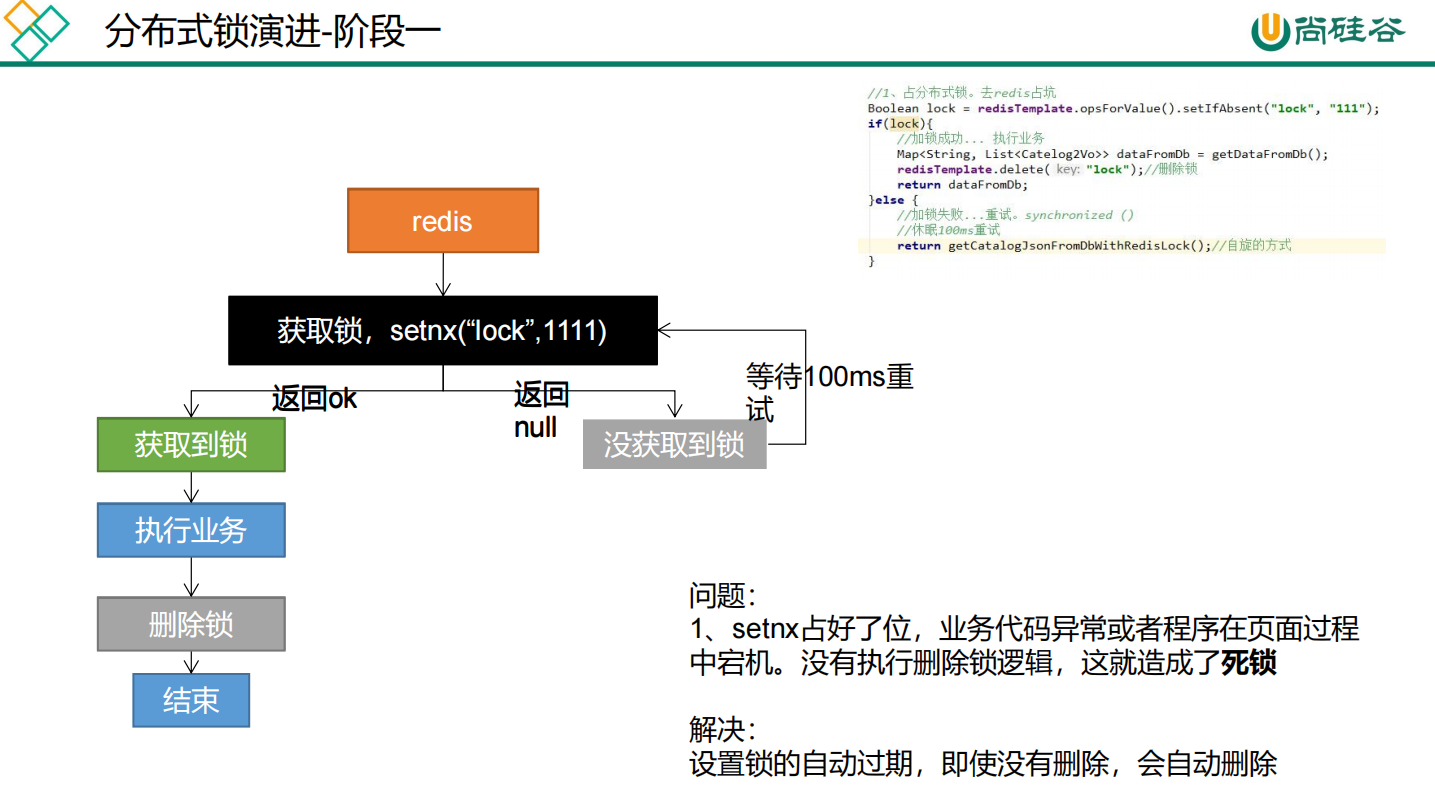
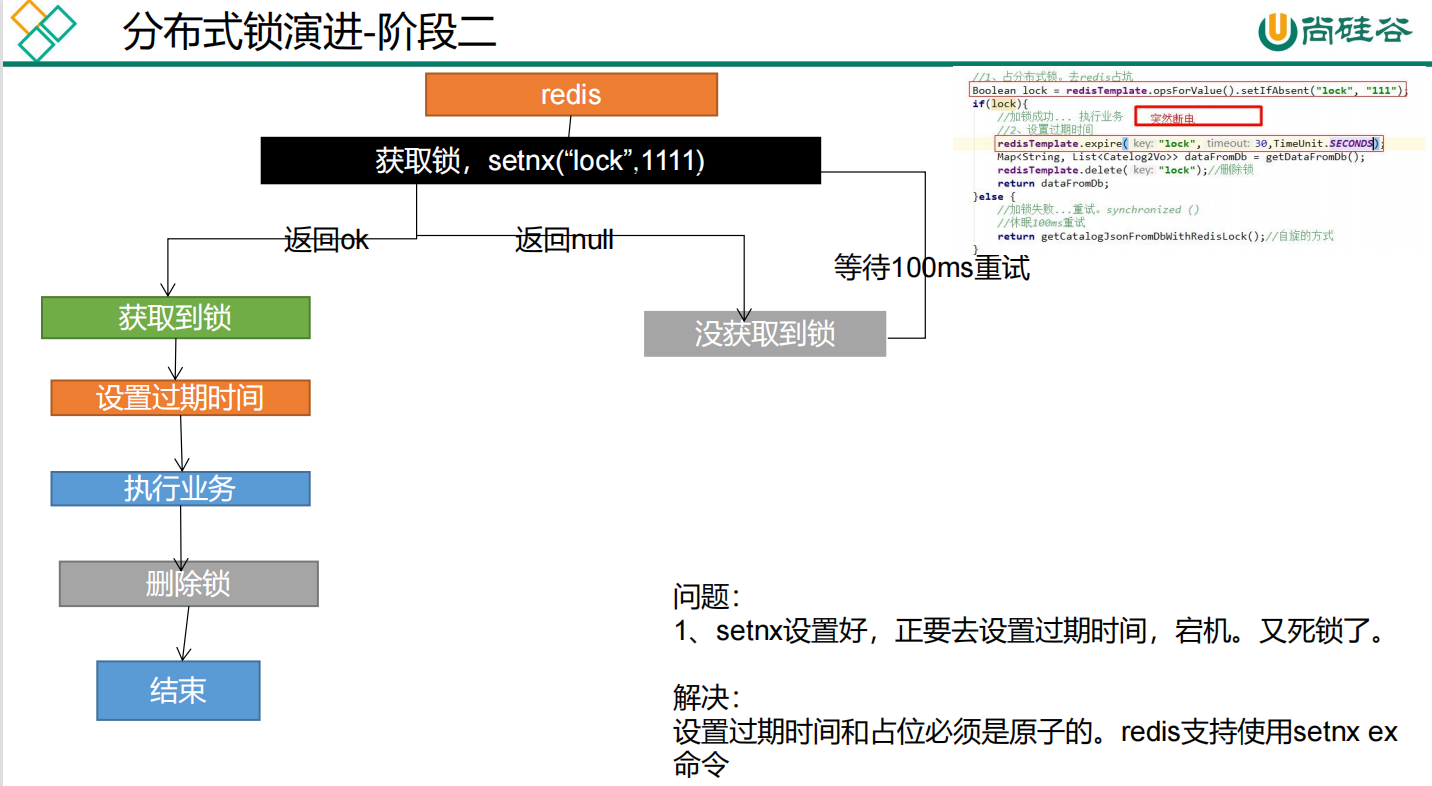
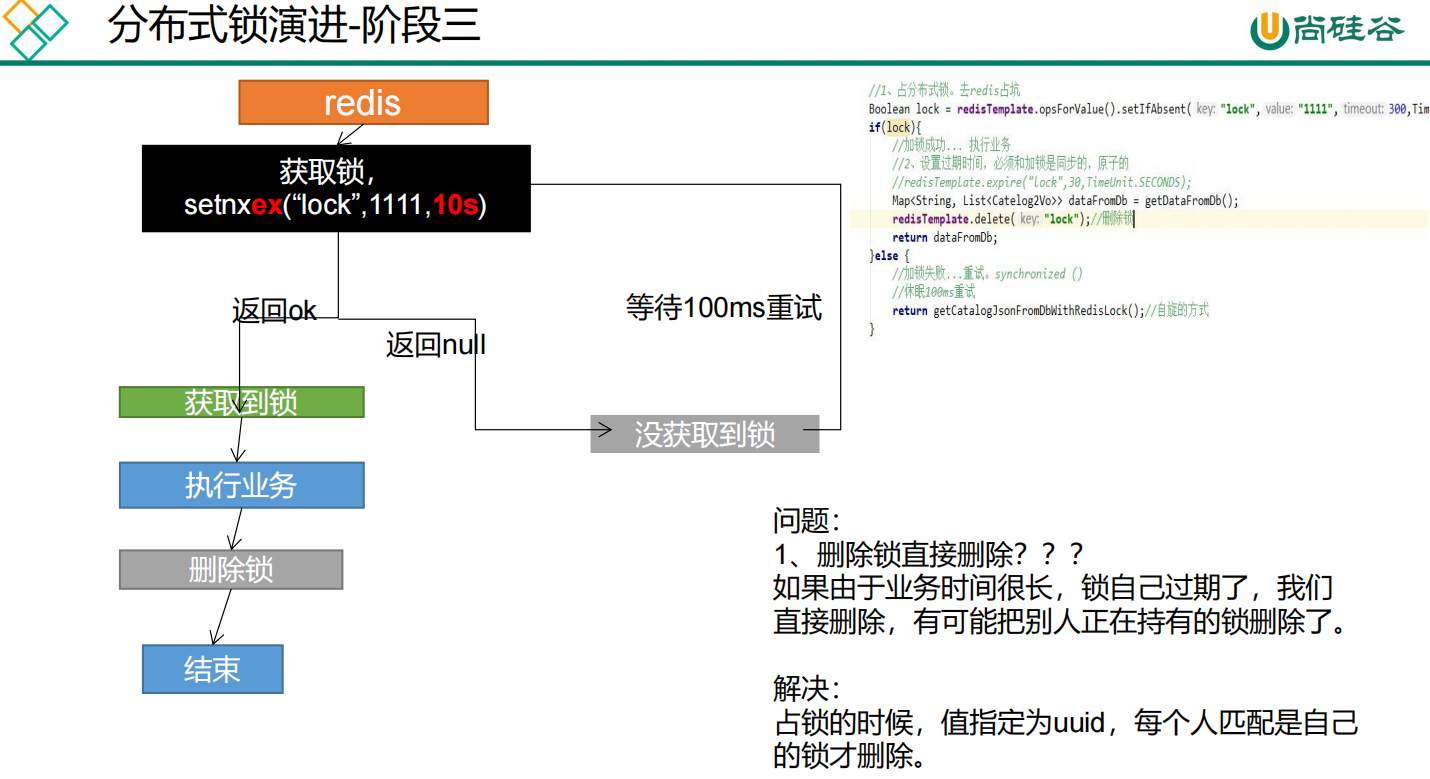
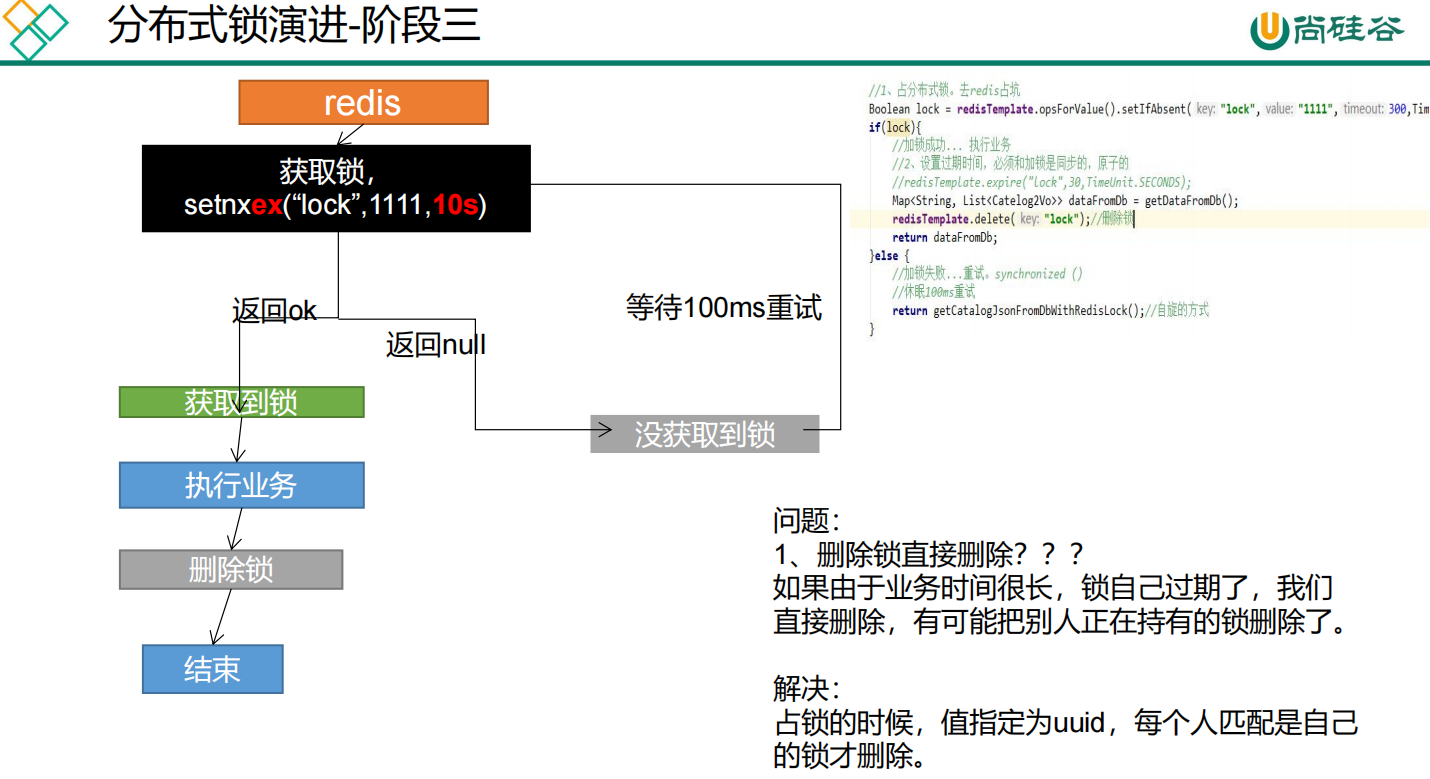
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedisLock() {
// 占分布式锁 设置过期时间,必须和加锁是同步的,是原子操作
String uuid = UUID.randomUUID().toString();
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
if (lock) {
System.out.println("获取分布式锁成功。。。。。。。。。");
Map<String, List<Catelog2Vo>> dataFromDb;
try {
dataFromDb = getDataFromDb();
} finally {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
//删除锁 获取值对比+对比成功删除 必须是原子操作 使用:lua脚本解锁
Long lock1 = stringRedisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);
}
//设置过期时间,必须和加锁是同步的,原子
//stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
//Map<String, List<Catelog2Vo>> dataFromDb = getDataFromDb();
// 删除锁 获取值对比+对比成功删除 = 原子操作 lua脚本解锁
/*String lockValue = stringRedisTemplate.opsForValue().get("lock");
if (uuid.equals(lockValue)) {
stringRedisTemplate.delete("lock");
}*/
return dataFromDb;
} else {
//加锁失败 重试
System.out.println("获取分布式锁失败。。。。。。。等待重试。。");
try {
Thread.sleep(200);
} catch (Exception e) {
}
return getCatalogJsonFromDbWithLocalLock();
}
}
也可以用Redisson分布式锁,Redisson内部提供了一个监控锁的看门狗,它的作用是在Redisson实例被关闭前,不断的延长锁的有效期(以防我们的请求执行时间超时)使这个锁一直有效,但一旦我们的服务器宕机,那么这个看门狗机制也就失效了,无人继续维持这个锁了,那么其在有效期到了之后就会失效。
redisson的lock具有如下特点:
阻塞式等待。默认的锁的时间是30s。
锁定的制动续期,如果业务超长,运行期间会自动给锁续上新的30s,无需担心业务时间长,锁自动被删除的问题。
加锁的业务只要能够运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除
知道这些redisson中的lock的性质后,我们就可以对缓存击穿问题刚才的解决方案【redis+Lua脚本】进行简化了,即不需要我们再模拟一个分布式锁(创建锁,加过期时间,怕过期了删错锁加uuid,怕判断后删除又碰巧判断后过期删错锁而使用lua脚本实现原子性),而是使用redisson直接生成一个lock锁就可以实现我们刚才的分布式锁解决击穿问题了。因为其会创建锁自己就会加默认30s过期时间,且不会出现任务执行过程中锁过期别的线程抢占到锁的问题,且任务执行完毕,即使我们不释放它因为有过期时间也会自动释放。
代码如下:
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithRedissonLock() {
// 占分布式锁
RLock lock = redisson.getLock("catalogJson-lock");
lock.lock();
Map<String, List<Catelog2Vo>> dataFromDb;
try {
dataFromDb = getDataFromDb();
} finally {
//解锁
lock.unlock();
}
return dataFromDb;
}
-
热点数据不过期。直接将缓存设置为不过期,然后由定时任务去异步加载数据,更新缓存。这种方式适用于比较极端的场景,例如流量特别特别大的场景,使用时需要考虑业务能接受数据不一致的时间,还有就是异常情况的处理,保证缓存可以定时刷新。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号