补充知识
递归函数
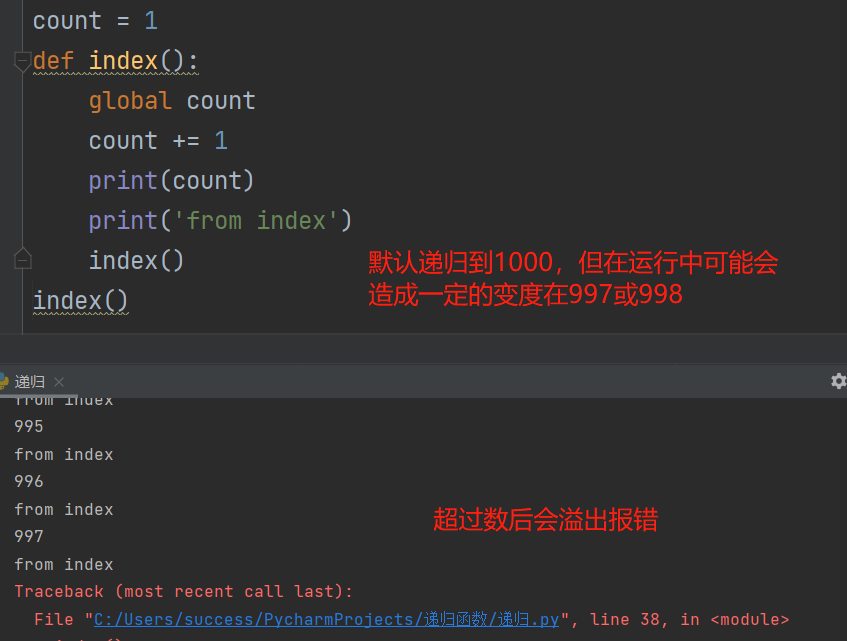
定义:在函数运行中,直接或间接调用了自身的函数。
( 官网表示:默认的最大递归数为1000,可使用sys.getrecursionlimit查看 )
ps: 如果想修改递归数可使用sys.setrecursionlimit(修改的次数) 进行修改
注:需要先使用 import sys 安装sys后才可操作。
递归:
1.递推
一层一层往下推导(每次递推后复杂程度相较于上次会有所下降)
2.回溯
依据最后得结论推导出最初需要的答案
(递归一定要有结束条件)
# 伪代码:可能无法运行,但可表达逻辑
# age(5) = age(4) + 2
# age(4) = age(3) + 2
# age(3) = age(2) + 2
# age(2) = age(1) + 2
# age(1) = 18 0
# 由(1)的岁数推出(5)的岁数
def get_name(n):
if n == 1:
return 18
return get_name(n - 1) + 2
print(get_name(5))
算法之二分法
算法:就是解决问题的高效方法
二分法:入门最简单的级别
使用条件:数据必须是有序的
(一般将数据一分为二后,从最后一个开始对比,不成功再将二分之一的数据再次分为二等分再比较直至找出)
l = [23, 56, 76, 87, 98, 123, 445, 657, 887, 954, 988]
# 找出445
# plan 1 :使用for循环
for i in l:
if i == 445:
print('找到了')
else:
continue
# plan2: 使用二分法
def my_plan(target_num, l):
if len(l) == 0: # 找不到后则退出
print('抱歉,没有该数据')
return
middle_index = len(l) // 2 # 先获取中间位置的索引值
# 判断是大是小
if target_num > l[middle_index]: # 说明寻找的元素可能在右侧
l_right = l[middle_index + 1:]
print(l_right)
my_plan(target_num, l_right)
elif target_num < l[middle_index]: # 说明寻找的元素可能在左侧
l_left = l[:middle_index]
print(l_left)
my_plan(target_num, l_left)
else:
print('找到了', target_num)
my_plan(445, l) # 在()内输入想寻找的数据即可
# 如果要查找的数据在开头,二分法则没有for循环效率快
三元表达式
当功能需求仅仅是二选一的情况下 推荐使用三元表达式
# 传统 比大小
def my_max(a, b):
if a > b:
return a
else:
return b
# 三元表达 比大小
def my_max(a, b):
return a if a > b else b
my_max(3,4)

""" 条件成立采用if前面的值,条件不成立采用else后的值 三元表达式尽量不要嵌套使用 """ res = '上课' if 10 > 2 else '下课' print(res) # 上课 res = '上课' if 2 > 6 else ('下课' if 6 > 5 else '放假') print(res) # 下课 # 小练习:电影是否收费 # 老办法 is_free = input('电影是否收费(y/n):').strip() if is_free == 'y': print('收费') else: print('免费') # 三元发 print('收费' if is_free == 'y' else '免费')
列表生成式
name_list = ['jason', 'jerry', 'lili', 'tony']
# 在每个名字后加上_max的后缀
# 传统法
# 1.定义一个空列表存放数据
new_list = []
# 2.for 循环老列表
for name in name_list:
# 3.生成新的名字
new_name = '%s_max' % name
# 4.添加至新列表
new_list.append(new_name)
print(new_list)
"""列表生成式"""
res = ['%s_max' % name for name in name_list]
print(res)

字典生成式
# 传统法
l1 = ['name', 'age', 'hobby']
l2 = ['jerry', 18, 'shopping']
new_dict = {}
for i in range(len(l1)): # 取出索引值
new_dict[l1[i]] = l2[i]
print(new_dict)
# 字典生成式
# 枚举
'''
enumerate(l1)
针对该方法使用for循环取值 每次会产生两个结果
第一个是从0开始的数字
第二个是被循环对象里面的元素
还可以通过start参数控制起始位置
'''
for i, j in enumerate(l2):
new_dict[l1[i]]=l2[i]
print(new_dict)
# 将Jason取出
name_list = ['jason', 'kevin', 'tony', 'jerry']
res = {i: j for i, j in enumerate(name_list) if j != 'jason'}
print(res)
# 取出对应的索引值
res1 = {i for i,j in enumerate(name_list)}
print(res1)

匿名函数
匿名函数:没有名字的函数
语法格式: lambda 形参:返回值
匿名函数一般不会单独使用,都是配合其他函数使用
print(lambda x:x**2)
def index():
pass
print(index)
print((lambda x: x ** 2)(2))
res = lambda x: x ** 2
print(res(2))
# 配合函数使用
# map() 映射
l = [1, 2, 3, 4, 5, 6, 7, 8, 9]
def index(n):
return n ** 2
print(list(map(lambda x: x ** 2, l)))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号