分析一套源代码的代码规范和风格并讨论如何改进优化代码
分析一套源代码的代码规范和风格并讨论如何改进优化代码
笔者工程实践课题是:基于语音识别的智能聊天机器人设计。本题目需要先研究机器学习的基本方法,用TeansorFlow机器学习库,通过Python构建一个基于LSTM循环神经网络的语音识别器。
故此,笔者将选取Tensorflow源码进行分析,分析其在源代码目录结构、文件名/类名/函数名/变量名等命名、接口定义规范和单元测试组织形式等方面的做法和特点。笔者工程实践尚处于前期调研阶段,故此本篇Tensorflow源码分析将结合网络博客如CSDN等进行参考。主要用Python及C++实现
一、Tensorflow源码结构
TensorFlow源码基本也是按照框架分层来组织文件的。如下:

其中core为tf的核心,它的源码结构如下:

以上目录结构比较清晰,规范。
二、Tensorflow源码展示分析
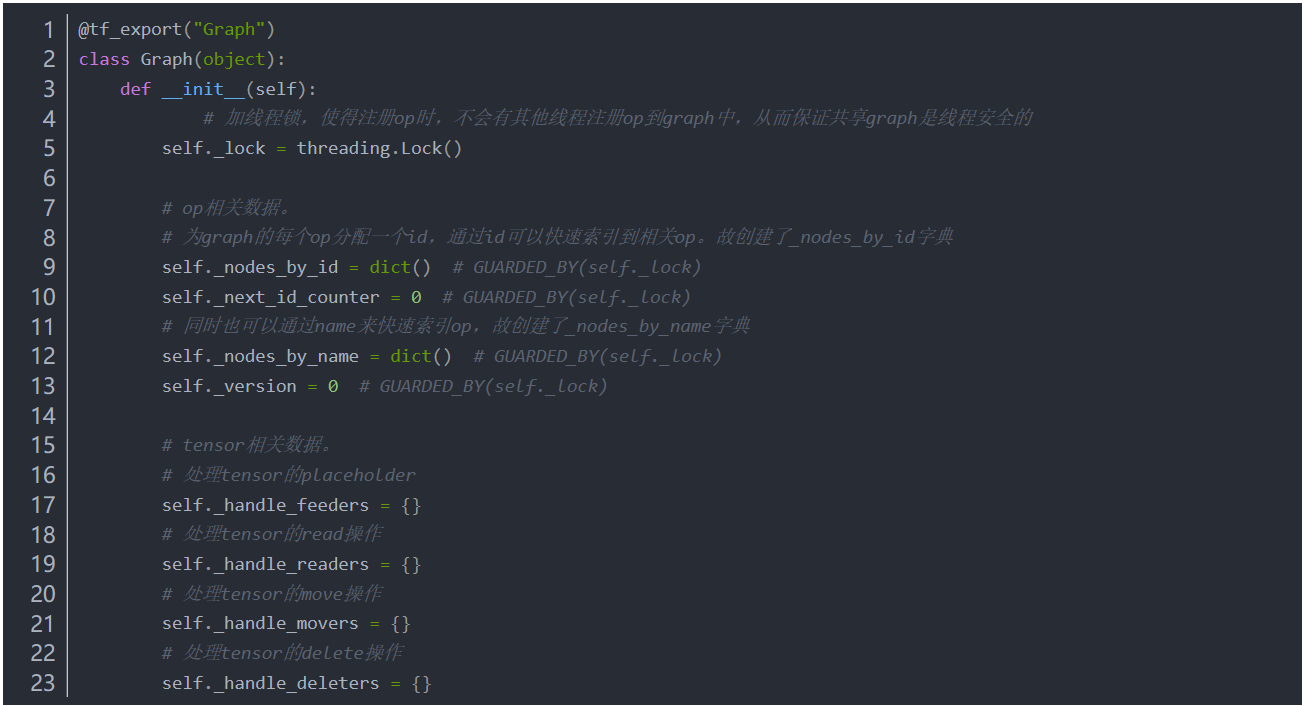
前端Graph数据结构
理解一个对象,先从它的数据结构开始。我们先来看Python前端中,Graph的数据结构。Graph主要的成员变量是Operation和Tensor。Operation是Graph的节点,它代表了运算算子。Tensor是Graph的边,它代表了运算数据。
GraphKeys 图分组
每个Operation节点都有一个特定的标签,从而实现节点的分类。相同标签的节点归为一类,放到同一个Collection中。标签是一个唯一的GraphKey,GraphKey被定义在类GraphKeys中,如下:

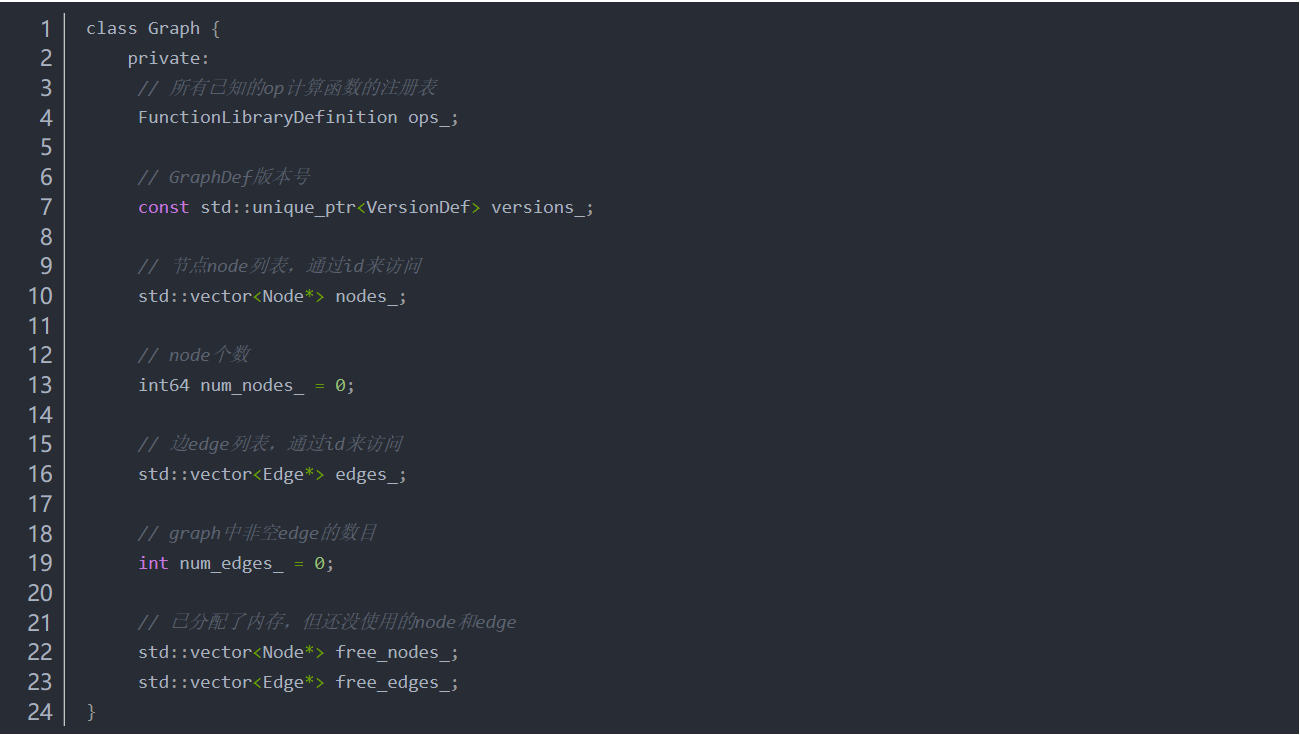
后端Graph数据结构
先来看graph.h文件中的Graph类的定义,只看关键代码
总结同类编程语言或项目在代码规范和风格的一般要求
排版要求:程序块缩进、程序块之间空行、操作符前后空格等
注释:要提供有效的注释
变量、常量注释:对于所有有物理含义的变量、常量,如果其命名不是充分自注释的,在声明时都必须加以注释,说明其物理含义。变量、常量、宏的注释应放在其上方相邻位置或右方。
命名风格保持一致:自己特有的命名风格,要自始至终保持一致,不可来回变化。说明:个人的命名风格,在符合所在项目组或产品组的命名规则的前提下,才可使用。(即命名规则中没有规定到的地方才可有个人命名风格)。对于变量命名,禁止取单个字符(如i、j、k...),建议除了要有具体含义外,还能表明其变量类型、数据类型等,但i、j、k作局部循环变量是允许的。
接口定义规范:在同一软件产品内,应规划好接口部分标识符(变量、结构、函数及常量)的命名,防止编译、链接时产生冲突。
可读性:注意运算符的优先级,避免直接用数字作为标识符等
变量:不使用无必要的公共变量,防止局部变量于公共变量同名,防止多个模块公用公共变量
函数:明确函数功能,精确实现函数设计;在同一项目组应明确规定对接口函数参数的合法性检查应由函数的调用者负责还是由接口函数本身负责,缺省是由函数调用者负责;一个函数仅完成一个功能;函数规模尽量控制在200行内;函数命名应准确描述函数功能
可测性:单元测试,编程的同时要为单元测试选择恰当的测试点,并仔细构造测试代码、测试用例,同时给出明确的注释说明。测试代码部分应作为(模块中的)一个子模块,以方便测试代码在模块中的安装与拆卸(通过调测开关);集成测试:在进行集成测试/系统联调之前,要构造好测试环境、测试项目及测试用例,同时仔细分析并优化测试用例,以提高测试效率。
本文参考:
代码规范 https://blog.csdn.net/qq_28195781/article/details/47273707
Tensorflow源码解析https://blog.csdn.net/u013510838/article/details/84103503

