
信息搜集系统设计方案
一、前言
本文是在学习完《高级软件工程》中《软件科学基础概论》这一章节后完成的,具体分析的案例是我在学校的工程实践项目————基于Python的智能信息搜集和数据分析系统设计及实现,该系统旨在帮助企业或者有需求的个人用户搜集大宗商品的数据信息。
二、软件架构风格
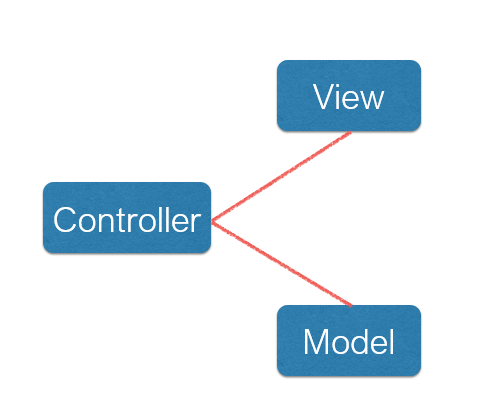
本项目采用MVC架构(模型-视图-控制器结构),其中Model模型层代表系统存取数据的对象及其数据模型,我们的数据搜集系统的模型主要包含用户模型、商品模型等;View视图层代表模型包含的数据的表达方式,一般表达为可视化的界面接口,我们的系统会实现数据展示的前端来实现数据的表达;Controller控制层作用于模型和视图上,控制数据流向模型对象,并在数据变化时更新视图,我们的爬虫实现以及数据分析模块都属于控制层,完成我们对数据的爬取与处理。
三、设计模式
采用设计模式的目的就是为了软件的重用,因此采用关注点分离的思想,区分软件中变化的部分和不变的部分,在不变的部分使用设计模式,以提高软件的重用性和可维护性。
此项目采用模板方法模式和策略模式。为了安全的考虑,我们在权限控制模块采取代理模式,进行用户审计,防止用户进行越权访问;采用外观模式,进一步简化浏览器的业务逻辑;采用适配器模式,来适应普通用户和管理者接口的不适配。
四、视图及目录结构
1、分解试图
分解是构建软件架构模型的关键步骤,分解视图也是描述软件架构模型的关键视图,一般分解视图呈现为较为明晰的分解结构(breakdown structure)特点。分解视图用软件模块勾划出系统结构,往往会通过不同抽象层级的软件模块形成层次化的结构。而在分解视图中,往往又包含子系统、包、库、组件、类等要素。
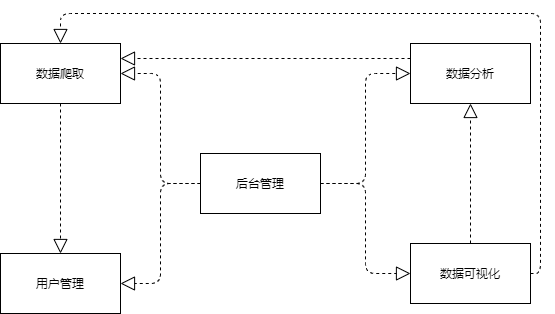
在本次工程实践项目中,智能信息搜集系统可以分解成如下模块:

2、依赖试图
依赖视图展现了软件模块之间的依赖关系。比如一个软件模块A调用了另一个软件模块B,那么我们说软件模块A直接依赖软件模块B。如果一个软件模块依赖另一个软件模块产生的数据,那么这两个软件模块也具有一定的依赖关系。依赖视图在项目计划中有比较典型的应用。比如它能帮助我们找到没有依赖关系的软件模块或子系统,以便独立开发和测试,同时进一步根据依赖关系确定开发和测试软件模块的先后次序。依赖视图在项目的变更和维护中也很有价值,比如它能有效帮助我们理清一个软件模块的变更对其他软件模块带来影响范围。
根据分解试图中的系统,我们可以把模块之间的关系,抽象出下面的依赖视图,其中“数据分析”模块依赖于“数据爬”模块提供的数据,“数据可视化”模块不仅能展示基本爬取到的大宗商品信息的数据,还能够展现出这些数据的分析结果,“数据爬取”还依赖于管理员或者用户的选择,只有这些人的选取商品信息的操作,系统才能够反馈出相应的爬取结果。
3、泛化视图
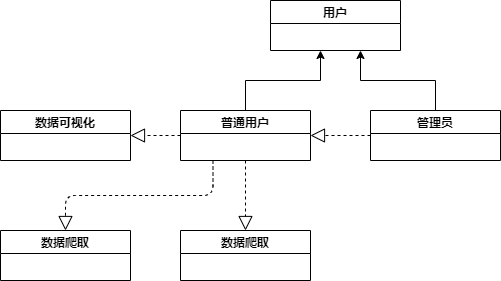
泛化视图展现了软件模块之间的一般化或具体化的关系,典型的例子就是面向对象分析和设计方法中类之间的继承关系。值得注意的是,采用对象组合替代继承关系,并不会改变类之间的泛化特征。因此泛化是指软件模块之间的一般化或具体化的关系,不能局限于继承概念的应用。
泛化视图有助于描述软件的抽象层次,从而便于软件的扩展和维护。比如通过对象组合或继承很容易形成新的软件模块与原有的软件架构兼容。
基于以上概念,我们可以从依赖视图中再次抽象出泛化视图,如下图所示:
4、执行视图
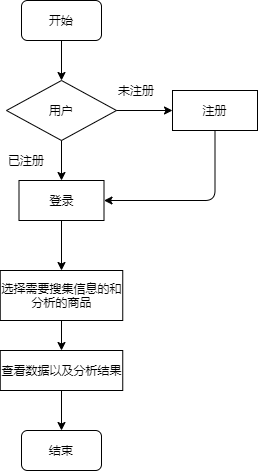
执行视图展示了系统运行时的时序结构特点,比如流程图、时序图等。执行视图中的每一个执行实体,一般称为组件(Component),都是不同于其他组件的执行实体。如果有相同或相似的执行实体那么就把它们合并成一个。
执行实体可以最终分解到软件的基本元素和软件的基本结构,因而与软件代码具有比较直接的映射关系。在设计与实现过程中,我们一般将执行视图转换为伪代码之后,再进一步转换为实现代码。
5、实现视图
实现视图是描述软件架构与源文件之间的映射关系。比如软件架构的静态结构以包图或设计类图的方式来描述,但是这些包和类都是在哪些目录的哪些源文件中具体实现的呢?一般我们通过目录和源文件的命名来对应软件架构中的包、类等静态结构单元,这样典型的实现视图就可以由软件项目的源文件目录树来呈现。
实现视图有助于码农在海量源代码文件中找到具体的某个软件单元的实现。实现视图与软件架构的静态结构之间映射关系越是对应的一致性高,越有利于软件的维护,因此实现视图是一种非常关键的架构视图。
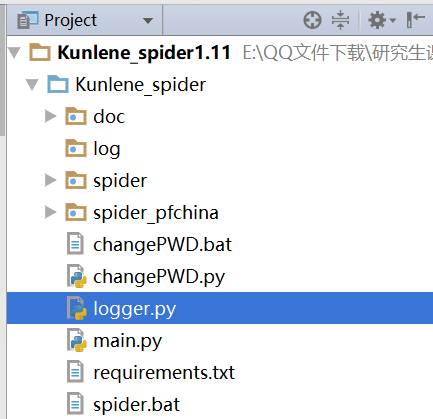
下面是我负责的部分(数据爬取)的项目文件目录,其中spider目录为爬取卓创资讯网的实现,spider_pfchina目录为爬取中国塑膜网的实现,changePWD为用户修改登录数据来源网站的密码,logger文件为打印日志,main为我们的启动爬虫的文件。
6、部署视图
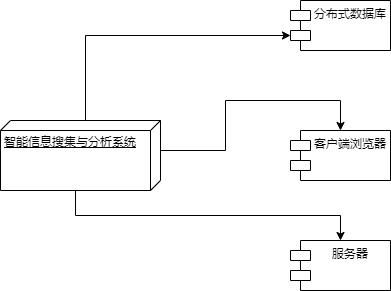
部署视图是将执行实体和计算机资源建立映射关系。这里的执行实体的粒度要与所部署的计算机资源相匹配,比如以进程作为执行实体那么对应的计算机资源就是主机,这时应该描述进程对应主机所组成的网络拓扑结构,这样可以清晰地呈现进程间的网络通信和部署环境的网络结构特点。当然也可以用细粒度的执行实体对应处理器、存储器等。
部署视图有助于设计人员分析一个设计的质量属性,比如软件处理网络高并发的能力、软件对处理器的计算需求等。
我们采用如下UML图来描述我们此次工程实践项目的部署试图:
7、工作分配视图
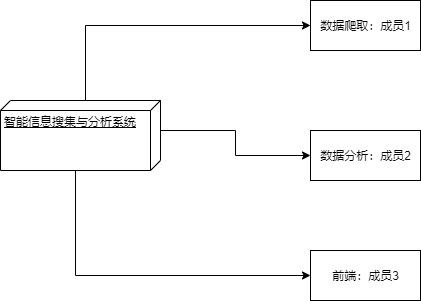
工作分配视图将系统分解成可独立完成的工作任务,以便分配给各项目团队和成员。工作分配视图有利于跟踪不同项目团队和成员的工作任务的进度,也有利于在个项目团队和成员之间合理地分配和调整项目资源,甚至在项目计划阶段工作分配视图对于进度规划、项目评估和经费预算都能起到有益的作用。
五、数据库设计
数据库采用当下流行的MongoDB,相比于我们平常接触得比较多的MySql而言,它是非关系数据库,MongoDB将数据存储为一个文档,据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。
根据之前对项目进行的数据建模和分析,大致可以得出此系统的三类表,对应三张表,这里我将相应的表结构设计出来:
1、用户信息表
用户信息表存放所有用户的账号和密码等重要信息,用于用户的注册和登录。
| 名称 | 数据类型 | 备注 |
|---|---|---|
| id | int | 用户id,主键 |
| name | string | 用户姓名 |
| password | string | 用户密码 |
| gender | string | 用户性别 |
| potrait | string | 用户头像 |
2、管理员信息表
后台管理人员的信息
| 名称 | 数据类型 | 备注 |
|---|---|---|
| id | int | 管理员id,主键 |
| name | string | 管理员姓名 |
| password | string | 管理员密码 |
| potrait | string | 管理员头像 |
3、大宗商品信息表
这里举其中一个大宗商品(上海石化F280T)的表结构为例子,其余的商品表结构与这个例子差别不大
| 名称 | 数据类型 | 备注 |
|---|---|---|
| id | int | 商品id,主键 |
| name | string | 商品名称 |
| market | string | 市场 |
| provider | string | 供应商 |
| minPrice | string | 最低价格 |
| maxPrice | string | 最高价格 |
| meanPrice | string | 平均价格 |
| priceType | string | 价格类型,例如元/千克 |
| date | datetime | 记录日期 |
六、软件系统运行环境和技术选型
本项目采用前后端分离的方式,基于python语言实现了一个智能信息搜集和数据分析系统,旨在帮助企业或者有需求的个人用户搜集大宗商品的数据信息。前端采用前端web技术以及Echarts可视化技术来完成数据的展示,数据分析部分采用pandas、numpy完成对数据的分析工作,爬虫部分采用scrapy框架完成对数据的爬取,数据存储使用更加灵活的MongoDB。
七、总结
我在学习完《软件科学基础概论》这部分章节后,对于一个软件系统的设计以及方案有了一个清楚的认知,未来不论是在课程设计项目还是在工作中为客户设计产品,通过对系统的架构、设计模式以及视图的描述和总结,能够帮助自己更好地理解业务逻辑,同时团队的交流也能够更加顺畅,毫无疑问,这些方法都是作为计算机专业学生的我们所必须要掌握的技能,总而言之,通过这门课程算是给我打开了一个全新的世界,在学校里不仅要能够解决学术问题,还要能够灵活地解决实际的工程问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号