


RandomForest的out of bag estimate 及Feature selection 具体作法
一、Out of bag estimate(OOB)
1、OOB sample number
RF是bagging的一种,在做有放回的bootstrap时,由抽样随机性可得到(其中1/e可由高数中的洛必达法则得到):
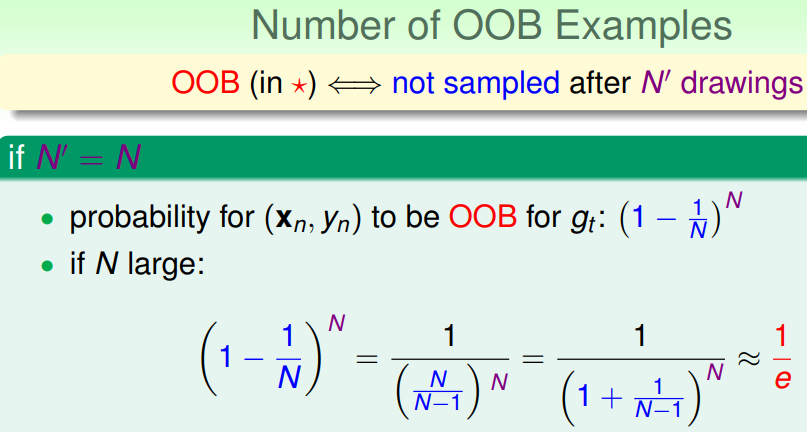
RF中每次抽样N个样本训练每一棵decision tree(gt),对于此棵树gt,原始的数据集中将有近1/e(33.3%)的样本未参与其训练;因此可以使用这部分数据对此棵树gt进行validation。(下图中红色星号表示此样本未参与某棵决策树gt训练)

2、OOB如何做validation
RF是通过多个基学习器进行组合得到整体的性能,即基学习器性能不高但经过组合却仍可能得到高性能(三个臭皮匠,赛过诸葛亮);因此,对于RF,应当是对整体的性能进行validation,而不是依次对单个基学习器进行validation。那么,如何对一个训练好的RF进行validation呢?
具体作法:
(1)对于数据集中每一个样本(xi, yi),将所有未使用该样本(xi, yi)进行训练得到的决策树筛选出来得到几个包含部分决策树的子模型集合M;
(2)然后在样本(xi, yi)上,使用模型集合M进行误差计算,即得到使用样本(xi, yi)进行validation的结果;(此步骤与使用留一法进行validation相似)
(3)重复步骤(2),依次计算在剩余的样本中使用每个样本进行validation的结果;
(4)对所有样本进行validation的结果进行求和取平均,作为RF模型最终的validation的结果。
具体表达式如下图:

特点:不需要额外划分一部分的validation set,RF可以做self-validation
![]()
二、RF如何做Feature Selection
1、由于在有限的样本数目下,用大量的特征来设计分类器计算开销太大而且分类性能差。因此,选取出对于建立模型性能较好的特征能够减少复杂度和工作量。

2、优缺点
优点:
(1)得到更简单的假设空间和更高效率的预测;
(2)在某种程度上相当于移除了部分噪声,更不容易overfitting,提高了模型的泛化性能;
(3)提高了模型的可解释性;
缺点:
(1)特征选择的工作需要花费较大的计算量(特征之间的交互关系,导致特征组合计算爆炸);
(2)如果选择的特征是错误的,那么也可能导致overfitting;
(3)如果选择的特征是错误的,那么会导致模型的可解释性错误;

3、Feature selection by importance (为解决特征组合爆炸问题,不考虑特征之间的交互关系,而是考虑给每个特征进行重要性打分)
(1) 如何衡量一个特征的好坏
出发点:如果某个特征是重要的,那么当在此特征的数据分布式引入一定的噪声,那么用仅对此特征进行变化之后的数据进行RF训练,模型的性能应当会有较大的变化(较明显地变差);反之,如果某个特征是不重要的,则重新训练后的模型性能变化不大。
要进行特征选择,得有一个对特征好坏的度量,RF对于特征好坏的度量是基于:
A. 对每一颗决策树,选择相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为errOOB1.
B. 随机对袋外数据OOB所有样本的特征X加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2。
C. 假设森林中有N棵树,则特征X的重要性 importance=∑(errOOB2-errOOB1)/N。这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即errOOB2上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
(2)特征选择过程
A. 计算每个特征的重要性,并按降序排序
B. 确定要剔除的比例,依据特征重要性剔除相应比例的特征,得到一个新的特征集
C. 用新的特征集重复上述过程,直到剩下m个特征(m为提前设定的值)
D. 根据上述过程中得到的各个特征集和特征集对应的袋外误差率,选择袋外误差率最低的特征集
4、 RF在实际计算特征重要性的处理tricks
(1)对于计算某个特征的重要性时,RF不采用直接修改所有样本在该特征的值或在该特征上引入噪声的方法;而是采用permutation(洗牌)的方法,例如总共有5个样本,某个特征Xi在所有样本上的取值情况为集合A=(0,1,2,3,4),则permutation的作法是将集合A进行重洗,然后再随机重新分配给每一个样本再特征Xi上的值。(就好像是52个人每人手里拿了一张牌,permutation就好比是个裁判,把52张牌收集起来重新洗乱后再分给52个人)

(2)RF如何做permutation
原始的permutation是需要在训练数据上做的,并且每次需要重新训练一个模型,即![]()
RF则使用OOB的那部分数据上进行permutation,然后计算每一个特征的重要性。
优点:不需要在原始数据上做permutation,因而也不需要重新训练模型;训练完一个RF模型后,即可使用该模型来计算特征重要性。

(3)RF做特征选择概括

5、如何选择RF中树的棵树
(1)大部分的理论都推荐使用树的棵树越多,性能越好。(使用越多的树,能够使得模型更加稳定)

(2)一些启发式的思路
A. 如果整个随机过程太不稳定,可能需要很多树;
B. 如果加减一棵树,模型的性能的表现不稳定,则可能多加树的棵树效果更好。

参考资料:
1. https://blog.csdn.net/liangjun_feng/article/details/80152796
2. 《机器学习技法》视频资料

 浙公网安备 33010602011771号
浙公网安备 33010602011771号