数仓项目常见问题汇总
数仓项目常见问题汇总
Hive常见错误总结
一、启动hive,执行sql插入数据时出现 error 30041
Error while processing statement: FAILED: Execution Error, return code 30041 from org.apache.hadoop.hive.ql.exec.spark.SparkTask.
日志文件:提示找不见main方法
原因:spark环境变量没有配
解决办法:配置spark的环境变量
二、启动hive,执行sql插入数据时提示类和方法找不见
Job failed with java.lang.ClassNotFoundException: org.apache.spark.AccumulatorParam
FAILED: Execution Error, return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime.
日志文件: status.SparkJobMonitor: Job failed with java.lang.ClassNotFoundException: org.apache.spark.AccumulatorParam
原因:hive和spark的兼容性问题
解决方案:
在hive 安装目录的lib下查看spark-core的版本
将lib删除,将符合版本的hive安装包中的lib文件添加进来,这样不影响元数据库(记得在lib中添加mysql驱动)
三、HDFS上的文件名的定义(默认为时间戳)出错
原因:flume中的时间拦截器Maxwell输出的数据中的ts字段时间戳单位为秒,Flume HDFSSink要求单位为毫秒
解决办法:将通过Maxwell输出的数据的时间拦截器中的时间的值转换为毫秒
四、启动Hiveserver2客户端多次执行sql之后提示堆内存满了
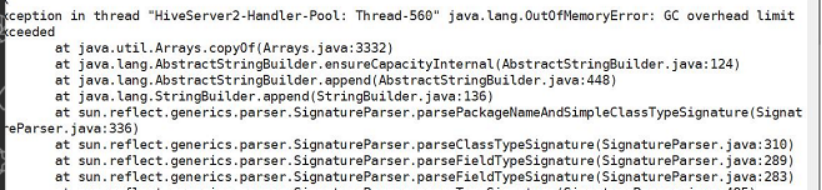
启动hiveserver2,通过jps -ml 查看hiveserver2的进程号,使用jinfo -flag MaxHeapSize +hiveserver2的进程号,查看MaxHeapSize的值是否为默认值(256M)
原因:Hive默认的MaxHeapSize:XX:MaxHeapSize=268435456(256M),比较小
解决办法:
修改hive-env.xml文件中的 HADOOP_HEAPSIZE值(根据自己的内存增大值)为:
#The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048
五、hiveserver2启动慢
原因:缺少tez导致重复连接60s

解决方案:找到hive-default.xml.template文件中的hive.server2.sleep.interval.between.start.attempts配置,修改时间为2秒并复制到hive-site.xml文件中
<property>
<name>hive.server2.sleep.interval.between.start.attempts</name>
<value>60s</value>
<description>
Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is
msec if not specified. The time should be in between 0 msec (inclusive) and 9223372036854775807 msec (inclusive).
Amount of time to sleep between HiveServer2 start attempts. Primarily meant for tests
</description>
</property>
六、向Hive数据库导入数据时,出现FAILED: SemanticException [Error 10096]: Dynamic partition strict mode requires at least one static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict
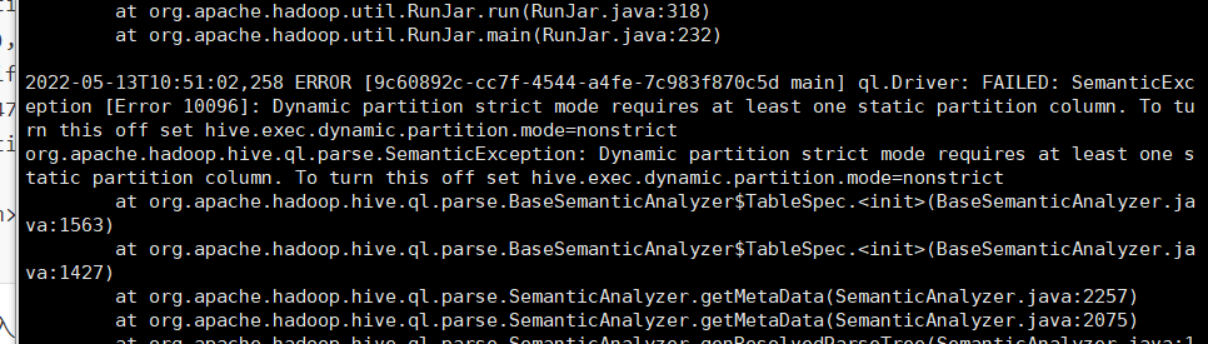
原因:动态分区时,hive默认是严格模式的,不允许动态分区的数据插入
解决方案:
方案一:在hive中执行:set hive.exec.dynamic.partition.mode=nonstrict,只对本次会话有效
方案二:在hive的安装目录conf下的hive-site.xml中加入:
<property> <name>hive.exec.dynamic.partition.mode</name> <value>nonstrict</value></property>
六、navicat执行sql出现异常
[Err] 1055 - Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column 'information_schema.PROFILING.SEQ' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
原因:
在MySQL5.7之后,sql_mode中默认存在ONLY_FULL_GROUP_BY,SQL语句未通过ONLY_FULL_GROUP_BY语义检查所以报错。
解决方案:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号