激活函数(Activation functions)
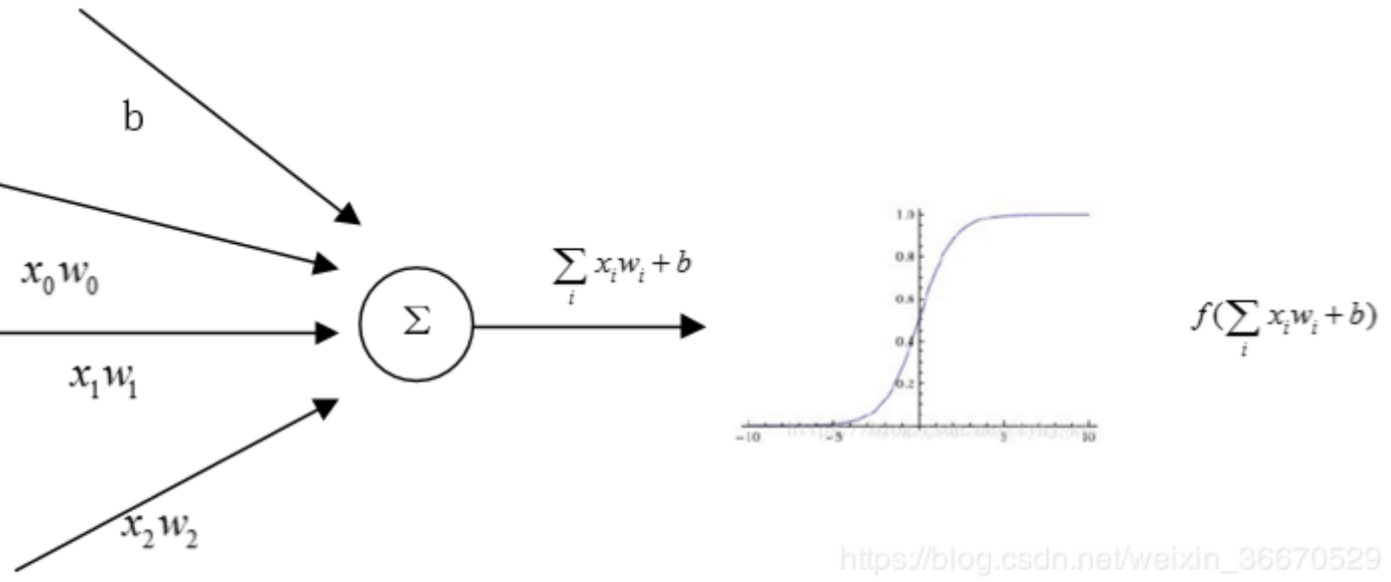
一层神经网络的数学形式很简单,可以看成是一个线性运算再加上一个激活函数,那么激活函数的作用是什么?
答:激活函数的作用是加入非线性因素,提高神经网络对模型的表达能力,解决线性模型不能解决的问题。举个例子:将一层神经网络用作分类器,正样本就让激活函数激活变大,负样本让激活函数激活变小,最终实现对正负样本的划分。
二、常见的激活函数及其优缺点
①、Sigmoid函数
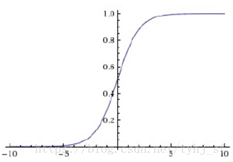
$f\left ( z \right )=\frac{1}{1+e^{-z}}$
特点:能将实数输入转化到0~1之间的输出,即越大的负数输出为0,越大的正数输出为1,故具有很好的解释性。常用于二分类问题
缺点:①、Sigmoid函数会造成梯度消失。如上图,在sigmoid函数靠近正/负无穷时,梯度会变成0。梯度下降法是通过学习率乘上梯度来更新参数,因此如果梯度接近0,那么参数将无法更新,造成模型不会收敛。并且使用sigmoid函数时,初始化权重不能太大,否则否则线性运算后经激活函数,大多神经院还是没有办法更新参数,所以权重初始化在[0,1]。
②、sigmoid输出不是以0为均值的,那么下一层网络的输入是非0均值,如果输入到下一个神经元的全是正的,这会导致梯度全是正的,更新参数后也永远是正梯度。比如$f\left ( x \right )=w^{T}x+b$,这时候$\bigtriangledown f\left ( w \right )=x$,如果x是均值为0的数据,那么梯度就会有正有负。
②、Tanh函数
$tanh\left ( x \right )=2sigmoid\left ( 2x \right )-1$,Tanh函数是Sigmoid函数的变形
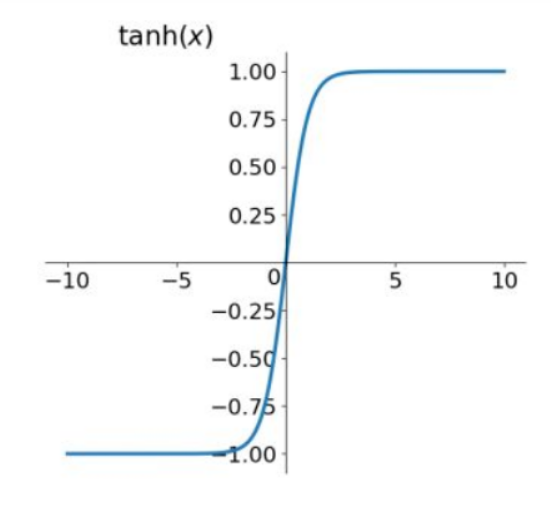
从图上可以看出,它将输入的数据转化为-1~1之间,均值变成了0,解决了sigmoid的第二个问题,因此tanh函数比sigmoid函数更好,但是仍存在梯度消失的问题。
③、ReLU函数
ReLU(Rectified linear uint)修正线性单元
表达式为:$relu\left ( z \right )=max\left ( 0,z \right )$
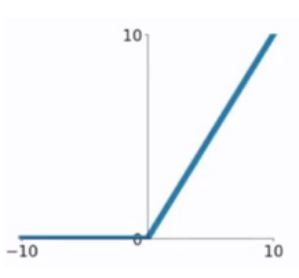
优点: ①、ReLU不会出现梯度弥散的现象,因为ReLU函数大于0时,梯度为常数。
②、ReLU函数只需要一个门限值,计算方法比较简单;并且它极大地加速随机梯度下降法的收敛速度。
缺点:ReLU函数进入负半区时,输出为0,梯度为0。会产生神经元不学习的现象,即Dead Neuron。
④、Leaky ReLU(带泄露单元的ReLU)
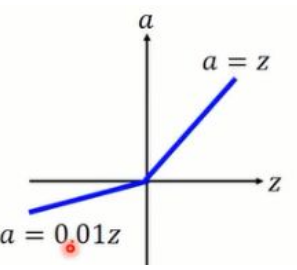
表达式:$f\left ( z \right )=I\left ( x<0 \right )\left ( ax \right )+I\left ( x\geq 0 \right )\left ( x \right )$
优点:解决了ReLU激活函数训练比较脆弱(神经元坏死)的缺点。但是实际中还是ReLU使用的多一点。
作者:Ryanjie
出处:http://www.cnblogs.com/ryanjan/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号