Course 2 - 改善深层神经网络 - 优化算法(Batch、Mini-Batch、Momentum、RMSprop、Adam)
声明:本文参考https://blog.csdn.net/u013733326/article/details/79907419和吴恩达老师的授课内容
一、实验的目的:使用优化的梯度下降算法,所以需要做一下几件事:
- 分割数据集(mini-batch)
- 优化梯度下降算法:
- 不使用任何优化算法:Batch Gradient Descent(批梯度下降法)
- Mini-Batch Gradient Descent(小批量梯度下降法)
- SGD(Stochastic gradient descent)(随机梯度下降法)
- Gradient Descent with Momentum(动量梯度下降算法)
- RMSprop
- Adam Gradient Descent
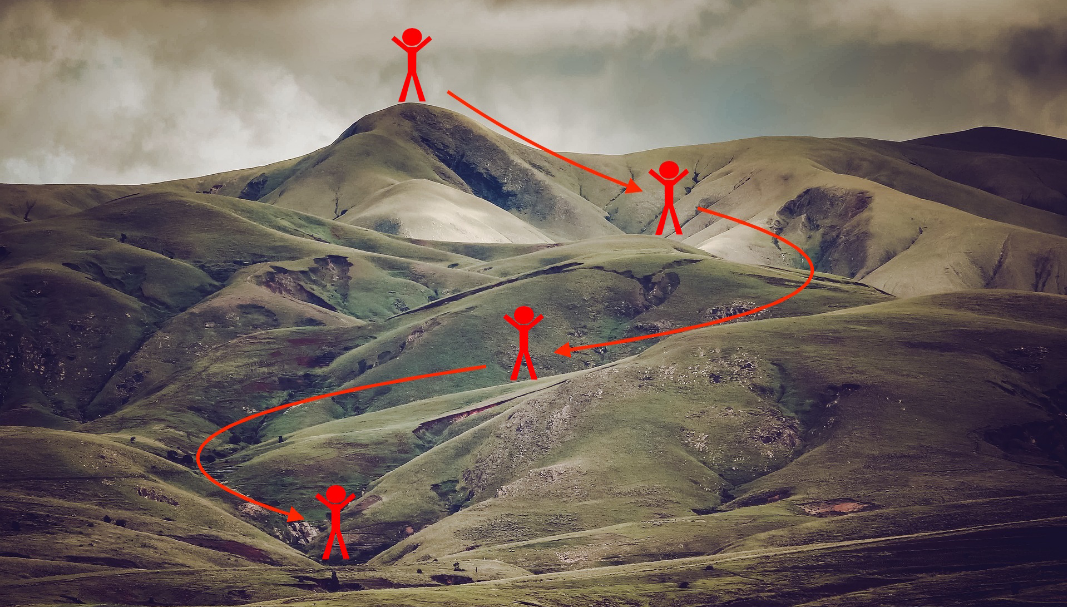
把丘陵的海拔想象成损失函数,最小化损失函数就像找到丘陵的最低点。在训练的每一步中,都会按照梯度方向(下山最快的方向)更新参数,使损失函数减小,最后尽可能地到达最低点。如上图所示即为最快的下山路径。
二、实验内容
1、没有任何优化的梯度下降法(GD),也叫作批梯度下降法,即一次梯度下降都遍历所有的训练集。参数更新的公式如下:
$$W^{\left [ l \right ]}=W^{\left [ l \right ]}-\alpha dW^{\left [ l \right ]}\quad\quad\left ( 1 \right )$$
$$b^{\left [ l \right ]}=b^{\left [ l \right ]}-\alpha db^{\left [ l \right ]}\quad\quad\left ( 1 \right )$$
注:$\alpha$是学习率、$l$是当前的层数。批梯度下降法时,你必须处理整个训练集,然后才能进行一次梯度下降法。
2、$Mini-batch$小批量梯度下降法,他既不是选择全部的数据来学习,也不是选择一个样本来学习,而是把所有的数据集分成一块一块来学习。如下图

与批梯度下降法不同的是,mini-batchme每次同时处理的单个的mini-batch $X^{\left \{ t \right \}}、Y^{\left \{ t \right \}}$,而不是全部的训练集X、Y。

比较Batch和Mini-batch:使用Batch梯度下降,一次遍历训练集只能让你做一次梯度下降;而使用Mini-batch梯度下降法,一次遍历训练集,能让你做$\frac{m}{batch-size}=\frac{500 0000}{1000}=5000$次梯度下降。那么对于大量的训练集,Mini-batch梯度下降法比Batch梯度下降法运行得更快。

这里区别一下iteration和epoch
Mini-batch梯度下降时,不一定每次迭代都朝着全局最优方向,但是整体上是朝着最优的方向。mini_batch出现震荡是因为每次迭代时,都在训练不同的mini-batch,得到的梯度是并不是全局最优的,这对于该批次最优。或许$X^{\left \{ 1 \right \}}$和$Y^{\left \{ 1 \right \}}$是比较容易计算的Mini-batch,成本会低一些,但是$X^{\left \{ 2 \right \}}$和$Y^{\left \{ 1 \right \}}$是比较难运算的Mini-batch,成本会高一些,这样一来就会出现摆动,但是$cost$整体是下降的。
m表示训练集的大小,当m=batch_size时,就是批梯度下降;m=1时为,随机梯度下降法(SGD),每个样本都是独立的mini_batch。

SGD每次只对一个样本进行梯度下降,故随机梯度下降法是有很多噪声的,他永远不会收敛到全局最小值,而是会在最小值附近波动。如下图蓝色为批梯度下降法,紫色为SGD,绿色为mini_batch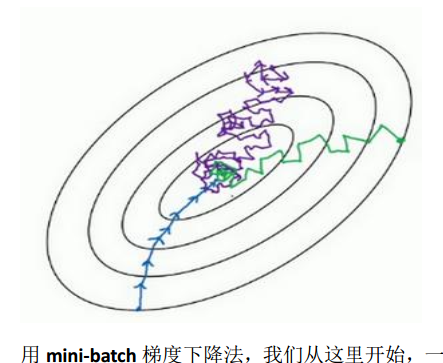
- SGD:相较于批梯度下降法,SGD学习的速度快,但是SGD永远不会收敛,而是在最小值附近波动;并且一次只训练一个样本,会丢失向量化带来的加速(吴恩达视频中讲的)。
- 批梯度下降法:训练样本巨大时,迭代耗时太长。
- mini_battch:效果介于上述两者之间,虽然也不会总朝最小值靠近,但是他比SGD更靠近最小值。
二、Momentum(动量梯度下降法)
首先了解一下指数加权平均数:
$v_{t}=\beta v_{t-1}+\left ( 1-\beta \right )\Theta _{t}$
在估测初期,为了防止刚开始的估测值值不准,需要偏差修正:$$v_{t}=\frac{v_{t}}{1-\beta ^{t}}$$
当t变大时:$$t\rightarrow \infty\quad lim\left ( v_{t}\right )=\frac{v_{t}}{1-\beta ^{t}}=v_{t}$$

第100天的数据,即当日数据是前100天所有数据的加权和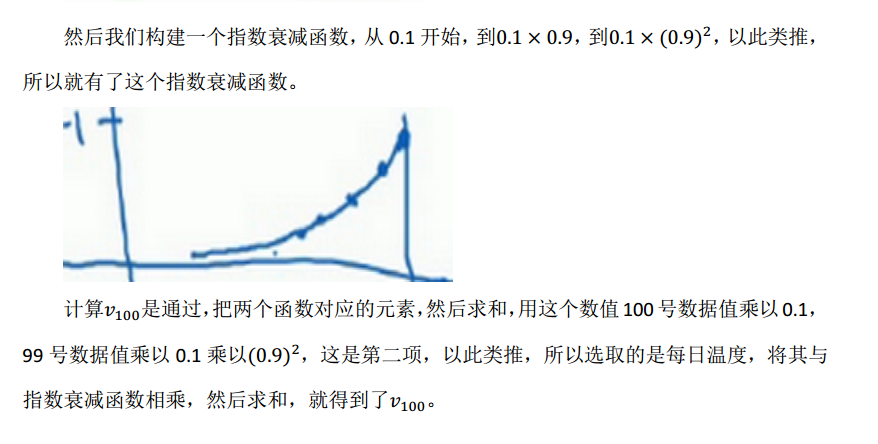
指数加权平均数由此得来,第100天的数据大约平均了$\frac{1}{\beta -1}=10$天的数据,因为越往后,权重越小可以忽略。优点是,指数加权平均数因为平均了几天的数据,故数据的波动会更小,变得平坦。
动量梯度下降法如下:

动量梯度下降法的有点:每次参数的更新不仅依赖当前样本,也依赖历史样本,他们存在指数权重,这样可以减少梯度下降时的振荡,大体方向不变,从而保证了效率和正确的收敛。
物理解释(来自吴恩达视频课)
第一种解释:
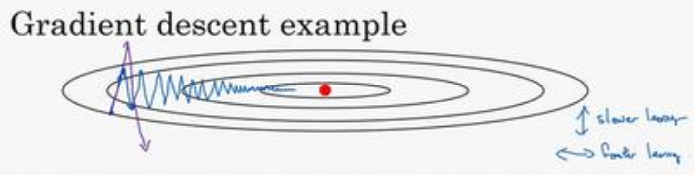
使用动量的梯度下降法,上图中纵轴上的摆动平均值接近于零(正负相互抵消);但是在横轴方向,所有梯度在横轴上的投影指向相同,因此横轴方向的平均值仍然很大
综上,使用了动量的梯度下降法,纵轴方向摆动减小,横轴方向运动更快。
第二中解释:
想像你有一个碗,一开始微分项给这个球一个加速度,球向山下滚,$\beta < 1$,表现出一些摩擦力。但是不像梯度下降法,每一步都独立与之前的步骤,下一步不仅取决于当前的梯度(加速度),还取决于动量(速度)$V_{dw}=\beta V_{dw}+\left ( 1-\beta \right )dw$,是二者的加权,第一项是速度的加权,第二项是加速度的加权。
三、RMSprop
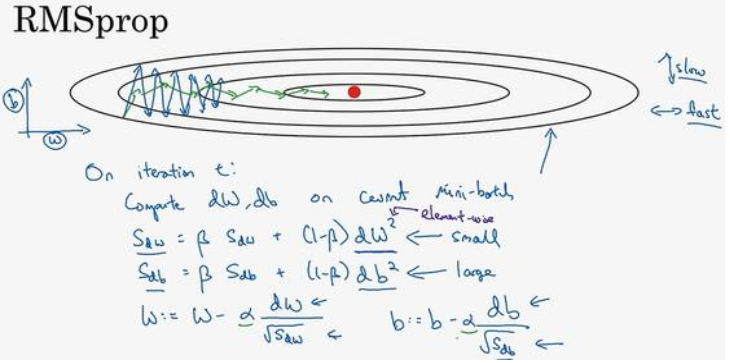
假设纵轴方向是b,横轴方向是W(只是为了解释方便,你也可以反过来)。我们希望的是纵轴方向上,减小摆动;而横轴方向上,学习速度加快。
观察上图,纵轴方向要比横轴方向大,所以db大,dW小;Sdb会大,Sdw会小。这样,纵轴上的更新被一个较大的数相除,水平上的更新被一个较小的相除,结果就能消除摆动(如图中的绿线),纵轴方向上摆动减小,横轴上继续推进。
四、Adam 算法
Adam算法就是将Momentum和RMSprop结合起来


$\varepsilon $是为了放置除零。这里用了指数加权平均数,要进行偏差修正。有的超参数根据经验可以用$\beta _{1}=0.9$,$\beta _{2}=0.999$,$\varepsilon = 10^{-8}$。
作者:Ryanjie
出处:http://www.cnblogs.com/ryanjan/
本文版权归作者和博客园所有,欢迎转载。转载请在留言板处留言给我,且在文章标明原文链接,谢谢!
如果您觉得本篇博文对您有所收获,觉得我还算用心,请点击右下角的 [推荐],谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号