
[Kaggle参赛经验|数据分析|机器学习] American Express - Default Prediction比赛经历——预测信用卡违约概率
前几天邮箱收到kaggle比赛即将截止的通知,但是事多没去看。今天想到去看了下,发现已经截止了。
比分咬得很紧,第一名0.80977,而我0.80667已经是1000+了。
这场比赛证明了数据的重要性,在数据质量足够高、数据足够多的情况下,各种模型算法的并不会有差距,树模型跟深度学习网络各显神通。
最后一次提交还是一月前的事,如果能提前登录ensemble下公开notebook应该会有更好的结果~但还是记录一下吧,也学到了很多。
比赛介绍
链接-https://www.kaggle.com/competitions/amex-default-prediction/overview,简单说就是通过customer往期的大数据,预测不还信用卡的概率。
数据集很大,test_data.csv有32G, train_data.csv有16G。
- D_* = Delinquency variables
- S_* = Spend variables
- P_* = Payment variables
- B_* = Balance variables
- R_* = Risk variables
树模型(LGBM, XGBoost, Catboost ...)
这种比赛首先想到的就是树模型了,比赛前排好多用到了LGBM.
在数据集中,每个customer_id会有很多不同时间的记录,最多为13个月的记录;因此特征工程很重要。
一般的方法是,针对customer_id进行group_by,这样利用每一个customer_id组内的特征计算出一些统计量,作为该customer_id的特征。这些统计量包括mean, std, last, min, max...等等,生成1000+特征,最后也能得到不错的结果,LB 0.79+。但是这些的特征都没有利用上时间信息...并且lagging features(近期的特征)被认为更有作用,所以提升的关键点在于提取更多时间相关的特征。
下面是学习到的一些特征工程。
Meta features
Meta features挺有意思的~很多前排都用到了。
- 首先把target根据customer_id,同训练集merge起来~这样每一条数据,都会有对应customer_id一个target
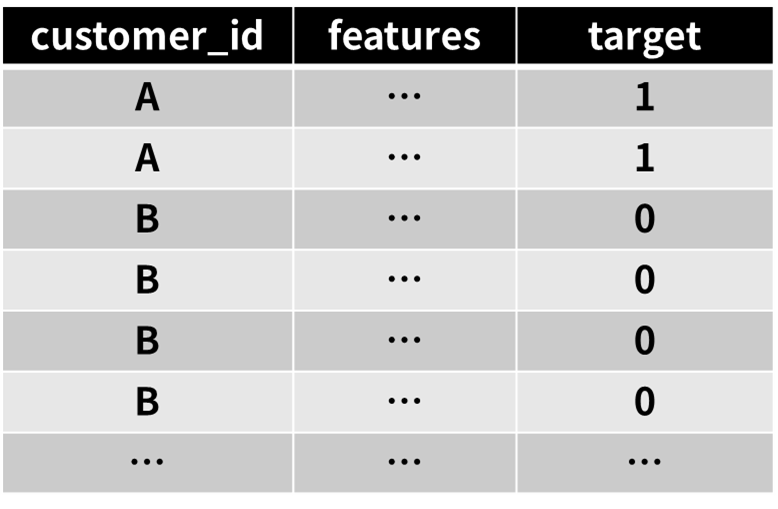
- 利用features做输入,target做输出,训练一个树模型,比如LGBM;这里要用k折交叉训练,做oof(out of fold)预测,得到每一条数据的预测值,作为meta features.
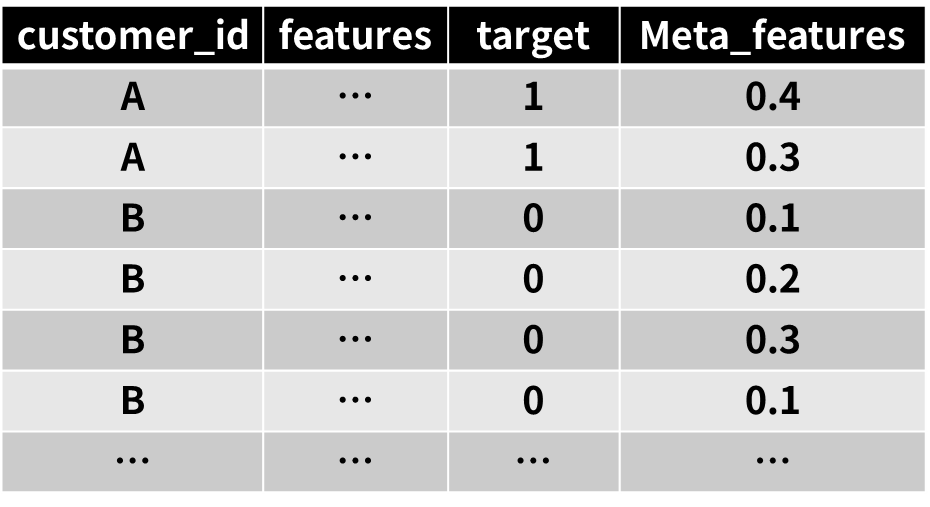
- meta features可以做mean,std,last等特殊工程,从而输入树模型;也可以直接用到深度学习模型中。
SequentialEncoder
这个是针对每一个特征fea,都用lgbm提取一个fea_seq出来。处理方式类似 Meta features, 不过利用了更多的时序信息~
具体代码有公开的notebook,但是没有注释😿。
- 对于某一特征,按时间rank后形成长度13的序列;
- 随后利用一些生成特征的手段(具体见generate_features)融合13个时段,生成更多特征。
- 最后lgbm训练并且进行k折oof,注意这里用到的特征只是根据一个特征生成的!
然后再进行下一个特征的处理,所以要训练N*k(N为特征数,k为k折)个lgbm模型。
最后呢,每个特征fea都由对应的fea_seq,从训练方式来看,这个fea_seq是13个时段特征的融合。
深度学习(CNN,transformer)
因为每一个customer_id对应一个2d数据,所以可以考虑用深度学习模型直接输入2D特征进行预测~
有个问题是并不是每个customer_id都有对应的13条数据,有的customer_id只有少于13个时间点的数据。
处理方式一般是用空值填充,也可以另外训练一个RNN网络来预测空值进行填补。
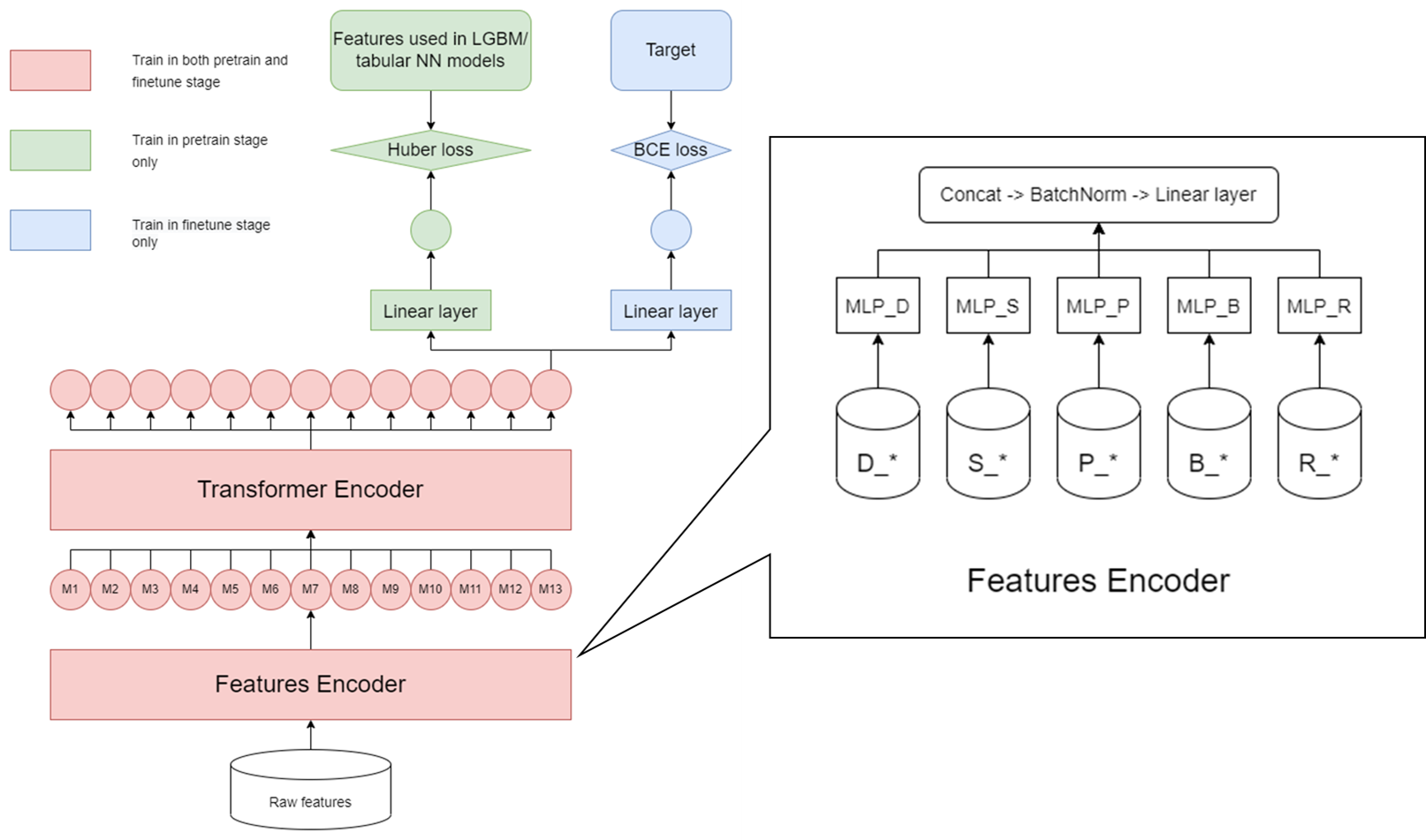
前排大佬分享了一个对transformer进行pretrain的方法。
先是pretrain,这里用不到,因此可以连同test data一起pretrian.
pretrain的输入是2D特征,label则是经过aggregate的features(mean, std, last, min, max...);一起计算huber loss.
然后再进行finetune,输入为2D特征,label则是target,这时候就能计算bce loss了。
网络结构图来自kaggle的post.注意features是分类别输入的,利用上了提供的类别信息,同时concat也保证了不同类别特征的融合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号