
PointCLIP V2
PDF: https://arxiv.org/pdf/2211.11682
Code: https://github.com/yangyangyang127/PointCLIP_V2
一、大体内容
在研究背景部分提到,之前提出的PointCLIP 存在两大问题:稀疏投影导致 2D-3D 领域差距大(投影的深度图与真实图像差异显著);文本输入简单(无法充分描述 3D 形状,影响图文对齐)。PointCLIP V2 针对这两个问题从文本和视觉两部分进行改进。在视觉上,对投影图做了优化,使得投影的深度图更加清晰、连续;在文本上,借助GPT提取更多具有几何特征的文本,进而丰富文本特征。另外还把分类任务扩展到分割任务(全局特征通过上采样更改为密集特征)。
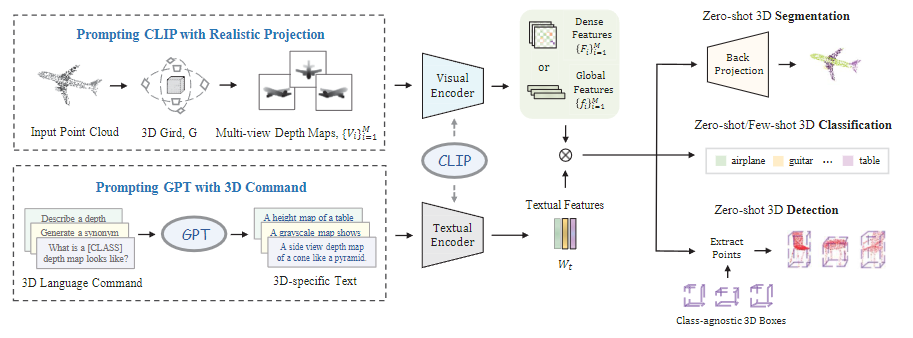
二、主要贡献
- 提出PointCLIP V2结合了CLIP 和 GPT-3,释放预训练知识在 3D 领域的潜力。
- 通过真实投影和 3D 导向提示词,有效缩小 2D、3D 与语言的领域差距。
- 分类任务扩展到分割和检测,支持零样本 / 少样本分类、零样本分割和检测。
- 零样本推理精度大幅提升。
三、相关细节
3.1 视觉端改进
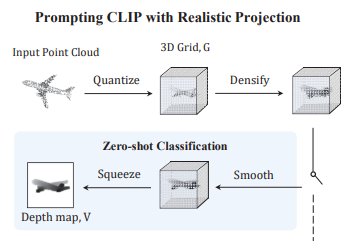
主要是针对深度图投影进行改进。 PointCLIP 的投影是稀疏的,只是将点云投影为稀疏分布的点,导致与 CLIP 预训练图像差异大,而PointCLIP V2 在视觉端提出了 “真实投影(Realistic Projection)”,包括量化(Quantize)、稠密化(Densify)、平滑(Smooth)、压缩(Squeeze)四个步骤,生成更接近真实图像的深度图。
-
量化(Quantize)
将 3D 点云投影到网格体素中,按深度值赋值(近处点遮挡远处点,保留最小深度)。 -
稠密化(Densify)
通过局部最小池化填充空体素,确保视觉连续性。 -
平滑(Smooth)
高斯滤波去除噪声,保留边缘和角落的锐度。 -
压缩(Squeeze)
压缩深度维度,生成 RGB 格式的深度图。
和pointCLIP对比,深度图更加清晰。

并且延时相差不大,但精度大幅提升。

3.2 文本端改进
考虑到PointCLIP 的文本输入简单,主要是 “a photo of a [CLASS]” 加上简单 3D类别 词汇,无法充分描述 3D 特征。PointCLIP V2 通过 GPT-3 生成富含 3D 语义的文本,使用四类 3D 导向指令(描述生成、问答、改写、词语成句),驱动 GPT-3 生成 3D 特定文本。

比如:
描述生成:如 “描述桌子的深度图”;
问答:如 “桌子的深度图有什么特征?”;
改写:同义句转换(如将 “灰度图” 改写为 “单色图”);
词语成句:用关键词(如 “桌子、深度图、平滑”)构建包含 3D 特征的句子。
这些文本富含 3D 几何和形状信息,显著增强 CLIP 的图文对齐能力,使文本特征与投影的深度图特征匹配更紧密。和PointCLIP相比提取的文本特征和视觉特征更加匹配。

3.3 任务扩展
在扩展任务方面,PointCLIP 主要支持零样本分类,而 PointCLIP V2 扩展到了少样本分类(将平滑操作改为可学习模块)、零样本部件分割(利用密集特征对齐)和零样本目标检测(结合 3DETR)。

分类任务和PointCLIP差不多
对于零样本部件分割,如下图所示提示词会有所变化,然后之前分类的全局特征通过上采样将特征图恢复到深度图原始尺寸,使每个像素都对应一个高维特征,为后续像素级(部件)预测提供基础。

零样本 3D 目标检测则基于预训练的 3DETR 作为区域提议网络,提取 3D 框内点云,通过 V2 进行零样本分类。
四、效果
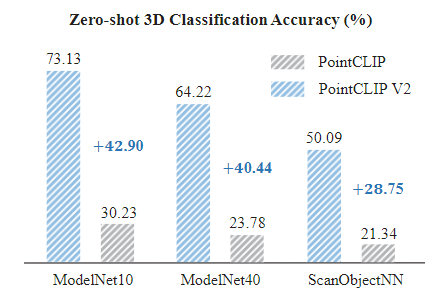
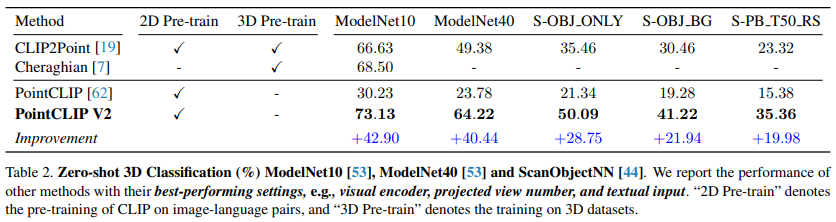
零样本 3D 分类
在 ModelNet10、ModelNet40、ScanObjectNN 三个数据集上,准确率较 PointCLIP 分别提升 42.90%、40.44%、28.75%,且显著优于 PointCLIP 等需 3D 预训练的方法。
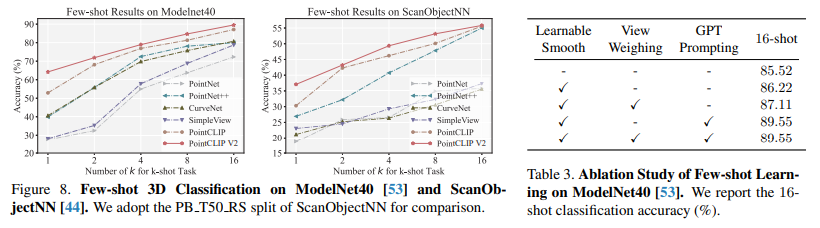
少样本 3D 分类
在 ModelNet40 和 ScanObjectNN 上,16-shot 准确率达 89.55%(ModelNet40),显著优于 PointCLIP 及传统 3D 网络(如 PointNet),1-shot 场景提升更明显(ModelNet40 上超 PointCLIP 12%)。
零样本 3D 部件分割
在 ShapeNetPart 数据集上,平均交并比(mIoU)达 49.5%,较 PointCLIP 提升 17.4%。


零样本 3D 目标检测
在 ScanNet V2 数据集上,mAP@25 达 18.97%(PointCLIP 为 6.00%),mAP@50 达 11.53%(PointCLIP 为 4.76%)。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号