

Yolo系列简单汇总一(yolov1至yolov5)
Yolo系列简单汇总二(yolox yolo6 yolo7)见:https://www.cnblogs.com/xiaxuexiaoab/p/16643821.html
一、YoloV1
pdf: https://arxiv.org/pdf/1506.02640.pdf
code: https://pjreddie.com/darknet/yolo/ https://github.com/abeardear/pytorch-YOLO-v1
参考链接:https://zhuanlan.zhihu.com/p/183261974
1.1 基本思想
目标检测可以采用滑窗,然后加分类器来判断是否是需要检测的目标,yolo把分类问题变成回归问题,将图片分成SxS个网络,如果object的中心落在网格A中,则网络A就负责预测这个object,
每个网格预测B个box(x, y, w, h, confidence)和C个类别,所以输出维度为
其中confidence计算如下:

每个网格预测的class信息和bounding box预测的confidence信息相乘,就得到每个bounding box预测某一类的confidence:

得到每个box的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果
1.2 网络结构
参考GoogLeNet

1.3 损失函数

1.4 不足
1.YOLOv1采用了7x7的网格划分模式,每个网格只能预测两个同类别的目标框,那么就无法预测密集场景下的目标位置,如:拥挤人群;
2.YOLOv1的网格划分方式会影响每个目标的边界定位准确度,因为目标一般是跨网格区域的,如果目标只有一小部分在某个网格,那么可能就会被忽略;
3.NMS本身漏洞,NMS会将相邻的目标框去重
4.固定分辨率,由于YOLOv1中存在全连接层,所以输入的分辨率必须固定
二、YoloV2
pdf: https://arxiv.org/pdf/1612.08242.pdf
code: https://pjreddie.com/darknet/yolo/ https://github.com/longcw/yolo2-pytorch
参考链接: https://zhuanlan.zhihu.com/p/47575929
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。
2.1 Better
-
BN层
在所有的卷积层都加入了BN(局部正则化),有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果。准确率提高了2% mAP,在加入BN之后,移除了dropout。 -
High Resolution Classifier
输入图片由yoloV1的224×224调整至448×448,准确率提高了4% mAP。 -
Anchor Boxes
借鉴Faster RCNN的做法,YOLOV2也尝试采用anchor,在每个grid预先设定一组不同大小和宽高比的边框,来覆盖整个图像的不同位置和多种尺度。 -
先验框采用聚类方法获得
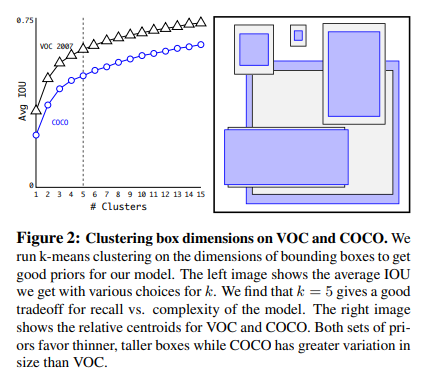
-
边框位置约束
YOLO v1直接预测x,y,w,h,范围比较大, 因此训练早期不容易稳定,YOLOV2预测偏移量并将预测框的中心约束在特定的grid网格内

其中\(b_x,b_y,b_w,b_h\)是最终预测边框的中心和宽高, \(c_x,c_y\)是当前网格左上角到图像左上角的距离(要先将网格大小归一化), \(p_w,p_h\)是先验框的宽和高。 \(\sigma\)是sigmoid函数。 \(t_x,t_y,t_w,t_h\)是要学习的参数,分别用于预测边框的中心和宽高。参考上图,由于\(\sigma\)函数将\(t_x,t_y\)约束在(0,1)范围内,所以根据上面的计算公式,预测边框的蓝色中心点被约束在蓝色背景的网格内,约束边框位置使得模型更容易学习,且预测更为稳定。注意YoloV2在位置上不使用Anchor框,宽高上使用Anchor框 -
passthrough
YOLOV2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是2626512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。
引用自 https://zhuanlan.zhihu.com/p/47575929

-
多尺度训练
为了让网络能适应不同分辨率的输入,在训练过程中,每个10个batches会随机选择一种分辨率输入,即利用图像插值对图像进行放缩,由于训练速度的要求以及分辨率必须是32倍数,所以训练过程中选择的分辨率分别为:320, 352, ..., 608。
2.2 Faster
-
网络结构
YOLOV2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构。DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约1/5,以保证更快的运算速度。

-
网格大小变化
由7 * 7 变成 13 * 13,输出相应由【N * 7 * 7 * 30】 变为 [N * 13 * 13 * 125]。
30 = 2 * 5 + 20 (B * 5 + C)
125 = 5 * 5 + 5 * 20 5个Anchor box
2.2 Stronger
识别的对象更多,YOLO2于是根据WordNet,将ImageNet和COCO中的名词对象一起构建了一个WordTree,以physical object为根节点,各名词依据相互间的关系构建树枝、树叶,节点间的连接表达了对象概念之间的蕴含关系(上位/下位关系)

2.4 损失函数
引用知乎用户:https://zhuanlan.zhihu.com/p/47575929

2.5 不足
- 小目标仍然是个问题
- 引入Anchor box带来正负样本不均衡问题
三、YoloV3
pdf: https://arxiv.org/pdf/1804.02767.pdf
code: https://github.com/ultralytics/yolov3
参考链接: https://zhuanlan.zhihu.com/p/183781646
在yolov2的基础上持续改进,这里引用知乎用户江大白的一张网络结构图
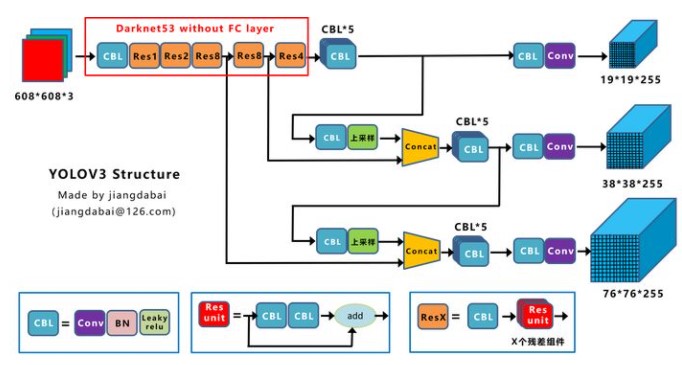
3.1 backBone
由yolov2的DarkNet19变成DarkNet53, 引入残差结构并加深网络
3.2 多尺度头
利用不同尺度的特征图进行预测,解决部分小目标问题
3.3 AnchorBox采用绝对大小
忽略掉与GT_BOX的IOU>0.5但不是最大的anchor box, 减少样本不均衡的情况
正样本:与GT的IOU最大的框。
负样本:与GT的IOU<0.5 的框。
忽略的样本:与GT的IOU>0.5 但不是最大的框。
使用 tx 和ty (而不是 bx 和by )来计算损失。
3.4 损失函数
引用自知乎用户([科技猛兽](https://www.zhihu.com/people/wang-jia-hao-53-3))

四、YoloV4
在yolov3的基础上进一步优化
pdf: https://arxiv.org/pdf/2004.10934.pdf
code: https://github.com/Tianxiaomo/pytorch-YOLOv4
参考链接:https://zhuanlan.zhihu.com/p/143747206 https://zhuanlan.zhihu.com/p/183781646

4.1 Yolov4的五个基本组件
CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。

CBL:由Conv+Bn+Leaky_relu激活函数三者组成。

Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。

CSPX:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
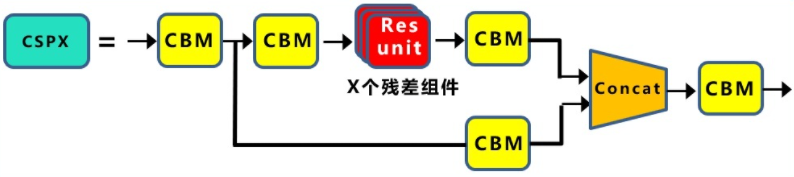
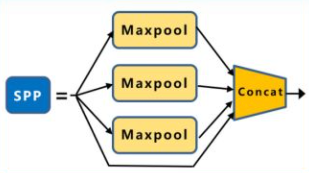
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
4.2 输入端优化
- 数据增强
CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。其优点如下:
丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
减少GPU:Mosaic增强训练时可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
4.3 BackBone优化
-
CSP
借鉴(CSPNet)[https://arxiv.org/pdf/1911.11929.pdf],引入CSP结构,即骨架网络采用CSPDarkNet。其优点如下:
增强CNN的学习能力,使得在轻量化的同时保持准确性。
降低计算瓶颈。
降低内存成本 。 -
Mish激活函数
Yolov4的Backbone中都使用了Mish激活函数,而后面的网络则还是使用leaky_relu函数。 -
Dropblock
yolov4采用Dropblock,对网络的正则化过程进行了全面的升级改进,可进一步减少过拟合情况。
Dropblock的研究者与Cutout进行对比验证时,发现有几个优点:
Dropblock的效果优于Cutout。
Cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上。
Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和Cutout相比都有更精细的改进。
4.4 Neck优化
-
SPP
采用SPP模块的方式,比单纯的使用k*k最大池化的方式,更有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征。 -
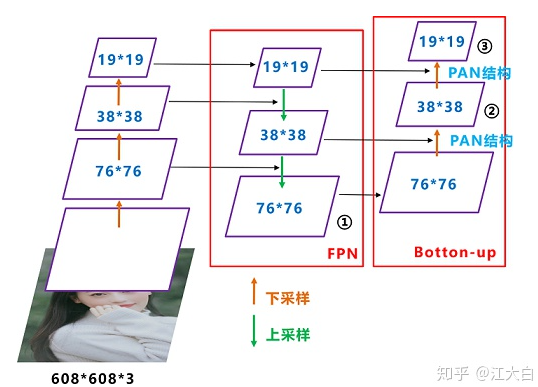
FPN + PAN
FPN+PAN借鉴的是18年CVPR的PANet,进一步提高特征提取的能力。
 ,
,
注意点是原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat(route)操作,特征图融合后的尺寸发生了变化
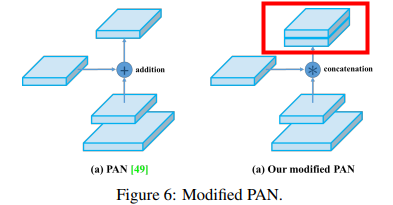
4.5 其他优化
-
多个Anchor负责GT_Box
相比于yolov3一个anchor负责一个GT, yolov4依据Iou大于一定阈值的anchor都负责该GT,在Anchor box数量不变的情况下,进一步减少正负样本均衡问题。 -
grid边界
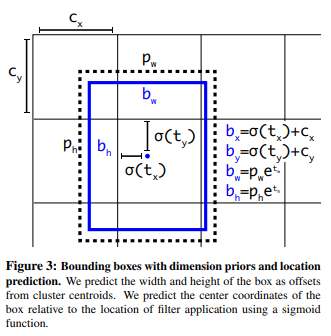
在yolov3中预测值是\(t_x, t_y, t_w, t_h\),会通过上图中公式进行转换为\(b_x, b_y, b_w, b_h\),按理说\(b_x, b_y\)能达到grid的任意位置,但由于sigmod激活函数的取值范围是\((0,1)\),所以加入一个略大于1的系数\(\alpha\)计算\(b_x, b_y\)
- Loss
训练采用CIou_Loss代替位置预测部分的MSE_Loss
预测时nms变为DIOU_nms, Iou loss发展流程可见下方内容。
4.6 IOU Loss发展流程
Iou_Loss(不能反应距离,无交集时没有梯度返回) ==> GIouLoss(引入两个框的最小包围框,解决距离问题,但训练存在发散情况) ==> DIouLoss(引入和GT中心点欧式距离,以及外围包围框的对角线距离) ==> CIoutLoss(加入惩罚项,彻底解决框包含的问题)
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
五、YoloV5
在前面系列基础上继续优化,代码先开源,开源后发现里面很多trick已经被发表,就没有发论文了(只能吃帽子了 hhh)。
code: https://github.com/ultralytics/yolov5
参考链接: https://zhuanlan.zhihu.com/p/172121380
5.1 输入端优化
-
Data Aug
Mosaic数据增强方法 -
自适应anchor
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框groundtruth进行比对,计算两者差距,再反向更新,迭代网络参数。
在Yolov3、Yolov4中,训练不同的数据集时,计算初始锚框的值是通过单独的程序运行的。但Yolov5在每次训练时,会自适应的计算不同训练集中的最佳锚框值。 -
自适应图片缩放
预测时,减少黑边填充,加快预测速度
如: 800 * 600 ==> 416 * 416
缩放后变成 416 * 320
流程
416 / 800 = 0.52 < 0.69 = 416 / 600,按小的比例0.52进行缩放得到 416 * 312
416 - 312 = 104, 差对32取余后为8, 312 + 8 = 320,这里取32,是因为Yolov5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余
5.2 BackBone优化
引入Fcous, Fcous + CSP + DarkNet
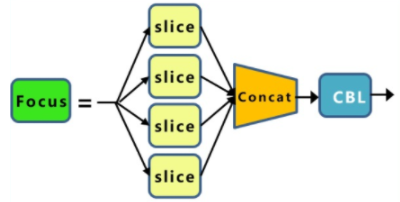
5.3 Neck
yolov4中的普通卷积替换为CSP2结构
5.4 提供不同大小版本
提供不同大小版本应对不同场景,由width和depth参数控制网络的宽度及深度。
Yolov5s、Yolov5m、Yolov5l、Yolov5x

 浙公网安备 33010602011771号
浙公网安备 33010602011771号