第四次作业
一.用图与自己的话,简要描述Hadoop起源与发展阶段。
1.Hadoop的起源:Hadoop是Apache Lucene创始人 Doug Cutting 创建的。最早起源于Nutch,它是Lucene的子项目。
2.Hadoop的发展历程:Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop最初只与网页索引有关,迅速发展成为分析大数据的领先平台。目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估的软件。
二.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
1.名称节点(NameNode)的主要功能:名称节点负责管理分布式文件系统的命名空间,管理数据节点和文件块的映射,客户端的访问请求,保存了两个核心的数据结构,即FsImage和EditLog。
2.第二名称节点(SecondaryNameNode)的主要功能:HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上,一般不和NameNode运行在同一结点上。
3.数据节点(DateNode)的主要功能:数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调 度来进行数据的存储和检 索,并且向名称节点定期发送自己所存储的块的列表。每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
相互关系:
① .第二名称节点会定期和名称节点通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件 edit.new上来,这个操作是瞬间完成,上层 写日志的函数完全感觉不到差别。
② .第二名称节点通过HTTP GET方式从名称节点上获取到FsImage和 EditLog文件,并下载到本地的相应目录下 。
④ .第二名称节点执行完(3 )操作之后,会通过post方式将新的 FsImage文件发送到名称节点上。
⑤ 名称节点将从第二名称节点接收到的新的 FsImage替换旧的FsImage文件,同时将 edit.new替换EditLog文件,通过这个过程 EditLog就变小了。
三、分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
1、客户端与HDFS
2、客户端读
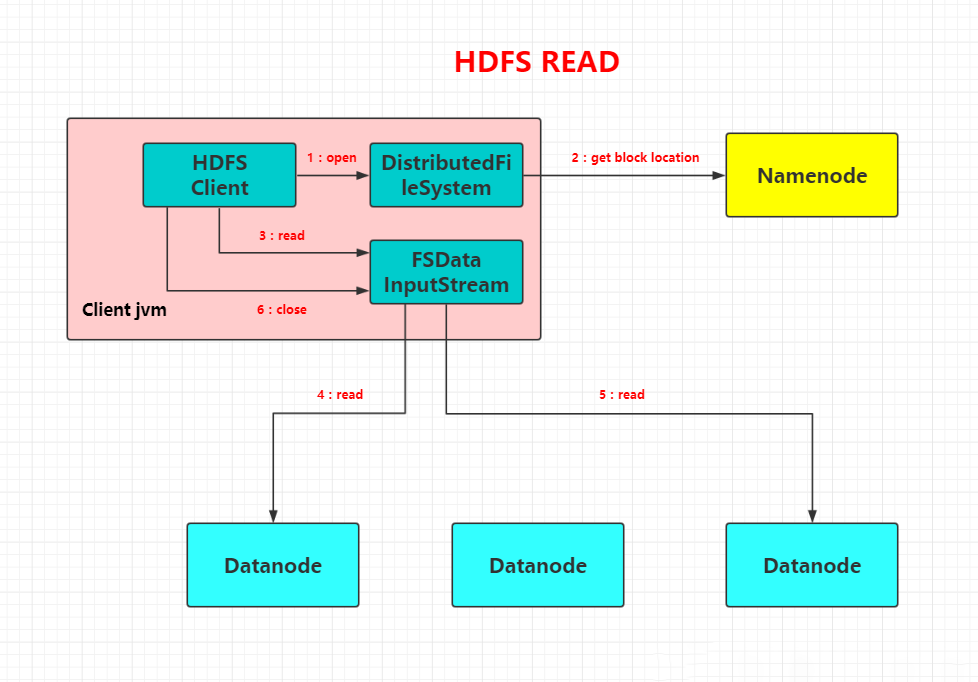
客户端向NameNode发出写文件请求。
检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
client端按128MB的块切分文件。
client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
每个DataNode写完一个块后,会返回确认信息。
写完数据,关闭输输出流。
发送完成信号给NameNode
3、客户端写
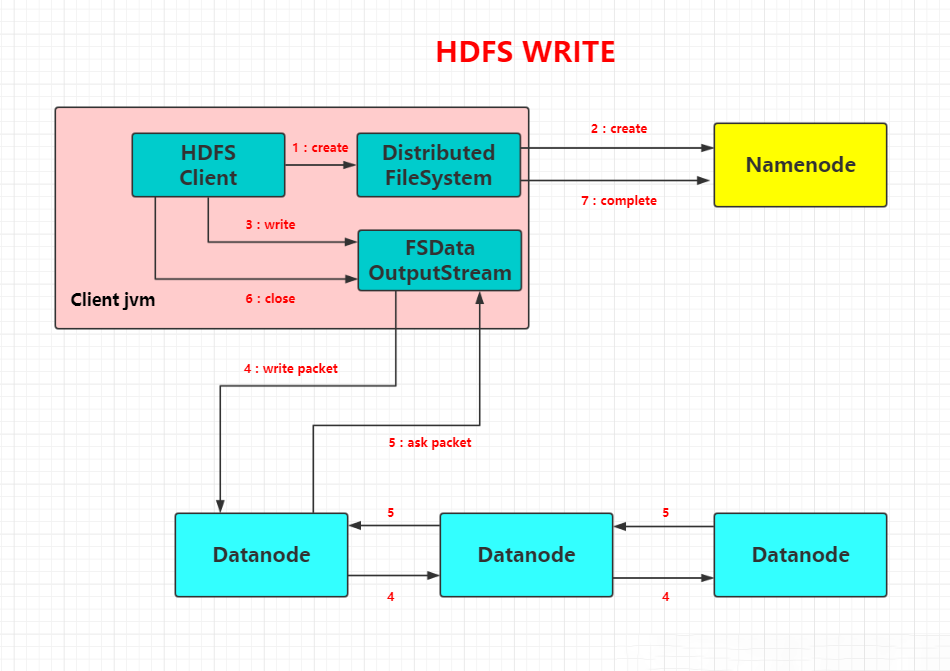
client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
就近挑选一台datanode服务器,请求建立输入流 。
DataNode向输入流中中写数据,以packet为单位来校验。
关闭输入流
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能。
- Zookeeper协同的功能.
- Client客户端的请求流程
- 四者之间的相系关系
- 与HDFS的关联

(1)Master主服务器的功能
管理用户对Table表的增、删、改、查操作;
管理HRegion服务器的负载均衡,调整HRegion分布;
(2)Region服务器的功能
HRegion部分由很多的HRegion组成,存储的是实际的数据。每一个HRegion又由很多的Store组成,每一个Store存储的实际上是一个列簇(ColumnFamily)下的数据。
(3)Zookeeper协同的功能
zookeeper是hbase集群的"协调器"。由于zookeeper的轻量级特性,因此我们可以将多个hbase集群共用一个zookeeper集群,以节约大量的服务器.
(4)Client客户端的请求流程
Client请求Zookeeper确定meta表所在的RegionServer所在的地址,接着根据Rowkey找到数据所归属的RegionServer;用户提交put或delete请求时HbaseClient会将put或delete请求添加到本地buffer中,符合一定条件会通过异步批量提交服务器处理。
(5)与HDFS的关联
HDFS是GFS的一种实现,他的完整名字是分布式文件系统,类似于FAT32,NTFS,是一种文件格式,是底层的,Hadoop HDFS为HBase提供了高可靠性的底层存储支持。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统
5.理解并描述Hbase表与Region与HDFS的关系。
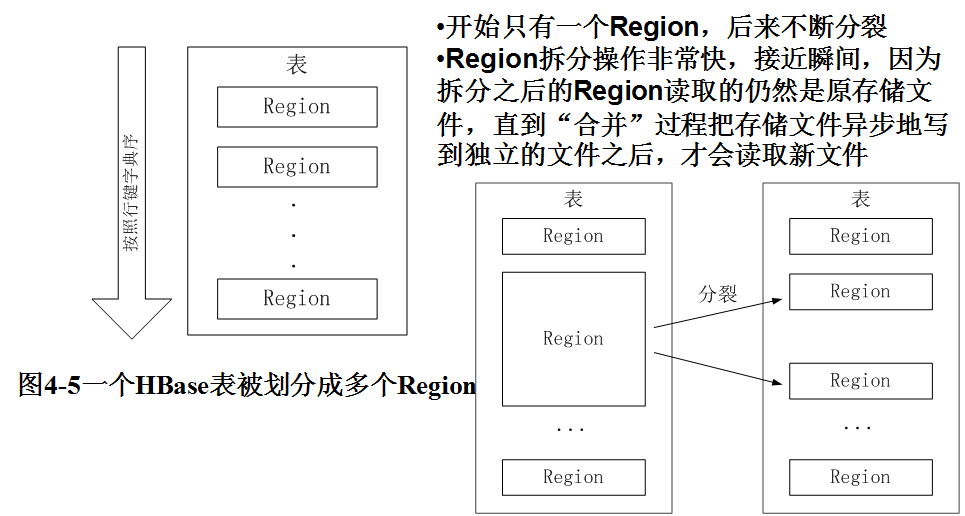
Hbase表与Region:
Hbase表与HDFS:
HDFS是Hadoop分布式文件系统。
HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。
Hbase是Hadoop database即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
6.理解并描述Hbase的三级寻址。
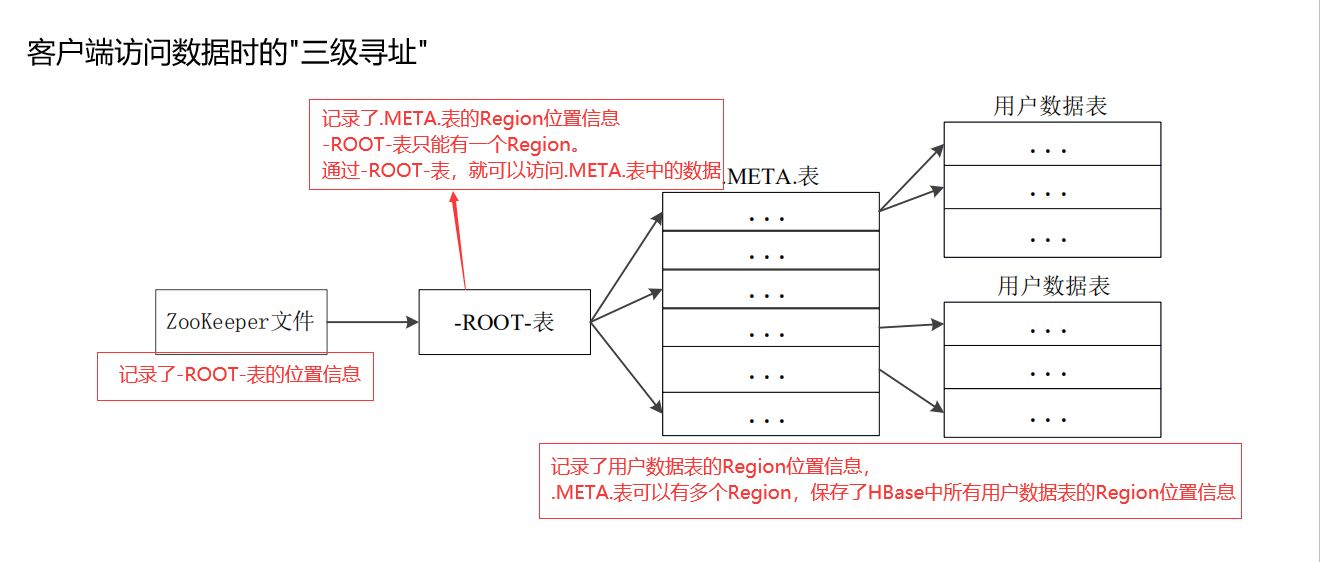
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数)
一个-ROOT-表最多只能有一个Region,也就是最多只能有128MB,按照每行(一个映射条目)占用1KB内存计算,128MB空间可以容纳128MB/1KB=217行,也就是说,一个-ROOT-表可以寻址个.META.表的Region。同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是128MB/1KB=217。最终,三层结构可以保存的Region数目是(128MB/1KB) × (128MB/1KB) = 234个Region
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
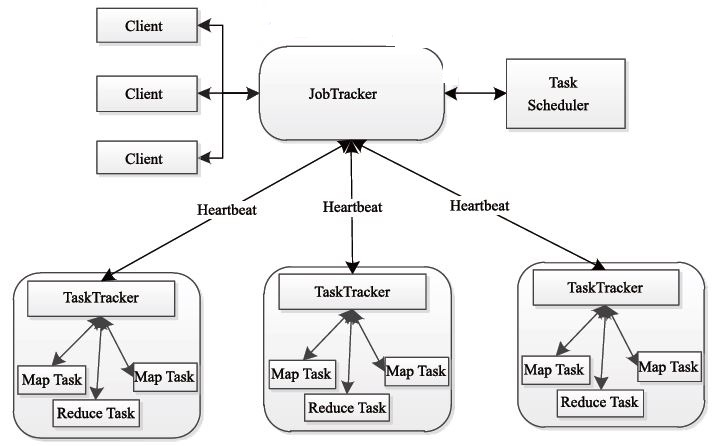
MapReduce包括四个组成部分,分别为Client、JobTracker、TaskTracker和Task,下面我们具体介绍这四个组成部分。
1)Client client
每一个 Job 都会在用户端通过 Client 类将应用程序以及配置參数 Configuration 打包成 JAR 文件存储在 HDFS,并把路径提交到 JobTracker 的 master 服务,然后由 master 创建每一个 Task(即 MapTask 和 ReduceTask) 将它们分发到各个 TaskTracker 服务中去执行。
2)JobTracker
JobTracke负责资源监控和作业调度。
JobTracker 监控全部TaskTracker 与job的健康状况。一旦发现失败,就将相应的任务转移到其它节点。同一时候。JobTracker 会跟踪任务的执行进度、资源使用量等信息,并将这些信息告诉任务调度器,而调度器会在资源出现空暇时,选择合适的任务使用这些资源。在Hadoop 中,任务调度器是一个可插拔的模块。用户能够依据自己的须要设计相应的调度器。
3)TaskTracker
TaskTracker 会周期性地通过Heartbeat 将本节点上资源的使用情况和任务的执行进度汇报给JobTracker,同一时候接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等)。
TaskTracker 使用“slot”等量划分本节点上的资源量。
“slot”代表计算资源(CPU、内存等)。一个Task 获取到一个slot 后才有机会执行,而Hadoop 调度器的作用就是将各个TaskTracker 上的空暇slot 分配给Task 使用。slot 分为Map slot 和Reduce slot 两种。分别供Map Task 和Reduce Task 使用。TaskTracker 通过slot 数目(可配置參数)限定Task 的并发度。
4)Task
Task 分为Map Task 和Reduce Task 两种。均由TaskTracker 启动。HDFS 以固定大小的block 为基本单位存储数据。而对于MapReduce 而言,其处理单位是split。
Map Task 执行步骤例如以下图 所看到的:由该图可知。Map Task 先将相应的split 迭代解析成一个个key/value 对,依次调用用户 自己定义的map() 函数进行处理。终于将暂时结果存放到本地磁盘上, 当中暂时数据被分成若干个partition。每一个partition 将被一个Reduce Task 处理。
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。
Mapper类:
1.将MapTask传给我们的文本内容转成string
2.根据分隔符号将每一行的单词切分
3.将单词输出为 <单词,1> :<hello,1><spring,1><winter,1>......
Redecer类:
1.汇总key个数
2.输出key次数
Driver类:
1.获取job实例对象
2.通过反射指定程序的jar包的位置
3.关联我们创建的Mapper类和Meducer类
4.指定Mapper输出数据的kv类型
5指定我们Reducer最终输出数据的类型
6.指定输入文件的路径
7.指定输出结果的目录,如果存在可以删除掉

 浙公网安备 33010602011771号
浙公网安备 33010602011771号