

朴素贝叶斯
其实贝叶斯算法本质是某些特征取特定特征值的情况下,指定特征的概率是多少的算法:
P(feature_x=value_0| feature_1=value1, feature_2=value2, feature_3=value3);
算法的实现就是将刚才描述的条件式转化为指定特征为指定特征值的情况下,某个特征的取某个特征值的概率是多大
=>P(feature_1=value1 | feature_x=value_0) * P(feature_2=value2 | feature_x=value_0) * P(feature_3=value3|feature_x=value_0)*P(feature_x=value_0)
为什么要这么搞?因为" feature_1=value1, feature_2=value2, feature_3=value3"同时满足通常是一个小概率事件(同时还要满足feature_x=value_0就更是一个小概率事件),需要大量的样本,求得概率未必靠谱;但是贝叶斯公式则是基于相对简单的条件场景下计算概率,比如P(feature_1=value1 | feature_x=value_0),这个条件概率计算要简单的多,数据也更好收集,因为基础条件只有一个:feature_x=value_0;所以,贝叶斯公式本质其实就是将条件概率的小概率计算转换为求可靠地相对大概率的概率计算。
而且,贝叶斯在多分类场景下其实不需要计算准确的概率,只要能够求得分子的值做比较就可以了(因为分母都一样)
另外一个场景就是P(B|C)是后验概率,完全不知道,但是我们知道先验概率(P(C|B),P(B));但是其实你想一下我们拿到了特征数据(参见上一段)进行处理其实目标就是求出先验概率,处理之后就是这个场景。
但是无论是哪种场景(牛逼人场景,还是阳性和犯病案例亦或者是次品率问题),其实本质来讲都是在描述首先聚焦一个小分类,或者说具备某个特征值的分类,然后对其中的样本进行归类;那么如果再拿出来一个样本,在全局范围内的属于哪个小分类的概念是多大?
首先我们拿阳性和癌症的例子,首先我们聚焦小分类,患癌症以及正常人,我们知道了在癌症里面阳性和阴性的比例,阴性和阳性本身就是两个样本集合,我们还知道全局来讲癌症这个小分类所占的比例,OK,那么现在拿出来一个样本,特征"阴阳性"的值为"阳性",那么这个样本是癌症的概率是多少?本质就是分析特征值做分类划分的问题;
然后我们再来看一下次品率的问题:
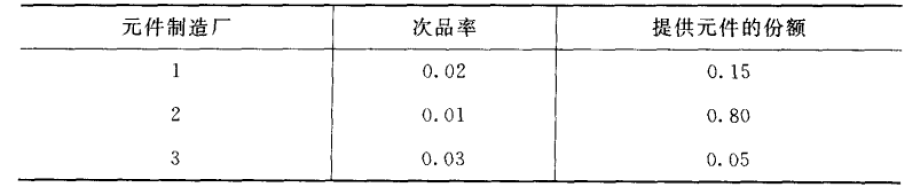
首先聚焦小范围分类,按照特征"制造厂"来进行划分,然后再制造厂范围内按照特征"质量"划分为次品和正常品两个样本集合;那么我们现在拿出来一个样本,"质量"的特征值是"次品",那么是各个制造厂的概率是多大?可以采用贝叶斯来进行解决(当然其实不需要计算出P(A)的准确值)。

最后我们来看一下i100和i500的例子:
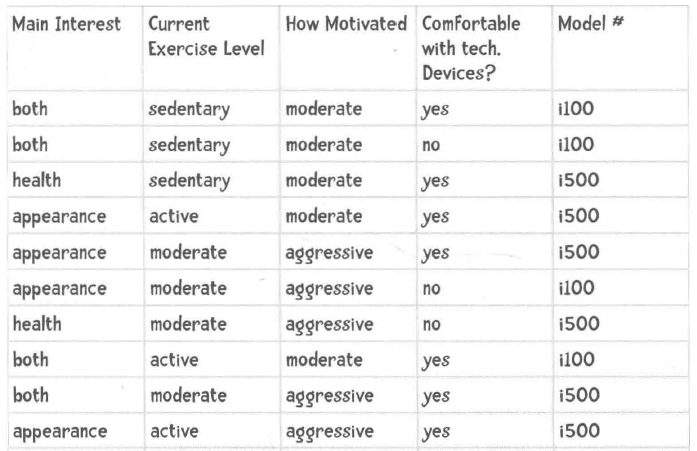
我们首先按照特征值"model"来进行划分(因为最终要判断某个样本属于i100/i500的概率),这次我们按照j几个特定的特征值feature_1(Main Interest),feature_2(Current Exercise Level),feature_3(How Motivated),feature_4(Comfortable with tech. Device)来进行划分分类(求出每个特征的概率),拿出来一个样本(人),具备了一些特征值,那么这个人买i100和i500的概率谁比较大?这个就是我们在最上面提到的方案:
P(model=i100/i500| f1=value1, f2=value2, f3=value3,f4=value4) = P(feature_1=value1 | feature_x=value_0) * P(feature_2=value2 | feature_x=value_0) * P(feature_3=value3|feature_x=value_0)*P(feature_x=value_0)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号