
Lora微调
Lora微调
LoRA原理
LoRA,即LLMs的低秩适应,是参数高效微调最常用的方法。
LoRA的本质就是用更少的训练参数来近似LLM全参数微调所得的增量参数,从而达到使用更少显存占用的高效微调。
LoRA的核心思想是,在冻结预训练模型权重后,将可训练的低秩分解矩阵注入到Transformer架构的每一层中,从而大大减少了在下游任务重的可训练参数量。
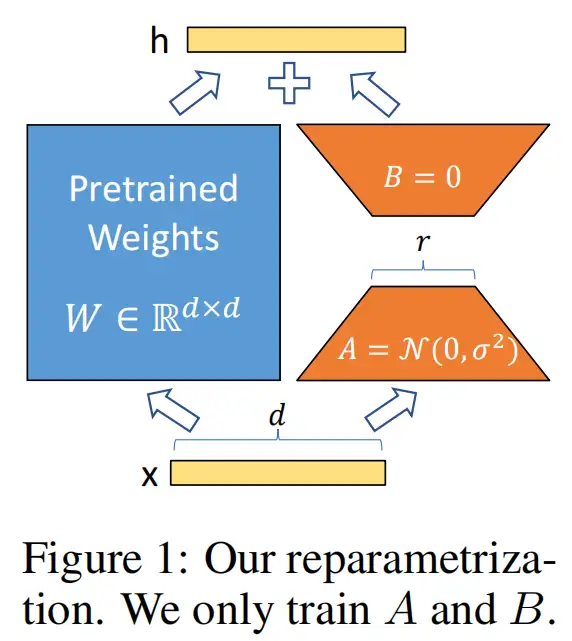
在推理时,对于使用LoRA的模型来说,可直接将原预训练模型权重与训练好的LoRA权重合并,因此在推理时不存在额外开销。
LoRA实现
假设模型在任务适配过程中权重的改变量是低秩的,因此提出低秩自适应方法。
LoRA允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
LoRA思想
- 在原始PLM(Pre-trained Language Model) 旁增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。
- 训练的时候固定PLM的参数,只训练降维矩阵A和升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。
- 用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
假设要在下游任务微调一个预训练语言模型,则需要更新预训练模型参数,公式表示为:
\begin{equation}
W_0 + \Delta W
\end{equation}
\(W_0\)是预训练模型初始化的参数,\(\Delta W\) 就是需要更新的参数。如果是全参数微调,则它的参数量\(=W_0\)。从这里看出要全参数微调大语言模型,代价是非常高的。
对于LoRA来说,只需要微调\(\Delta W\)。

在推理工程中,LoRA也几乎未引入额外的inference latency,只需要计算\(W = W_0 + \Delta W\)即可。
LoRA与Transformer的结合也很简单,仅在QKV Attention的计算中增加一个旁路。
其他微调
2019年 Houlsby N 等人提出的 Adapter Tuning,2021年微软提出的 LORA,斯坦福提出的 Prefix-Tuning,谷歌提出的 Prompt Tuning,2022年清华提出的 P-tuning v2。
Adapter Tuning 增加了模型层数,引入了额外的推理延迟
Prefix-Tuning 难于训练,且预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能
P-tuning v2 很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差
参考文献:
https://zhuanlan.zhihu.com/p/1919768716272436728
https://www.cnblogs.com/justLittleStar/p/18242820

 浙公网安备 33010602011771号
浙公网安备 33010602011771号