
无监督领域自适应
无监督领域自适应(UDA)
任务描述:
现有两个数据集
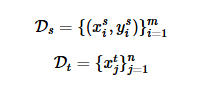
任务是利用源域中已有的知识(标签信息)去学习目标域的样本类别。
直观感受

如现在有两堆数据,一堆事真实的动物照片,一堆是手绘动物的照片。两个数据集的风格明显不一样,他们的分布也是明显存在偏差的。如果我们直接在真实的动物照片上训练一个分类器,然后直接用在手绘动物的照片分类上,性能必然是比较差的。
每个领域都有自己特有的知识,而这些特有的知识对其他领域反而是一种干扰
在UDA任务中,我们需要寻找一种“共有特征”。如在上面的照片中,对于真实的猴子和手绘的猴子,我们需要提炼出胡子的共有特征,如脸庞的形状,毛发的颜色等,摒弃一些领域自己特有的特征,如图片的背景,构图差异等。
假设我们现在有一个特征抽取器\(f:x \to Z\),可以抽取出“共有特征”,则根据这个\(f\),我们可以构建出两个新的数据集:
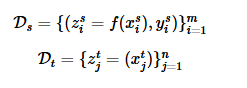
\(D_s\)相当于我们的训练集,而\(D_t\)就是我们的测试集。我们在训练集\(D_s\)上直接训练一个分类器,然后用分类器对\(D_t\)进行分类任务,即可完成UDA任务。
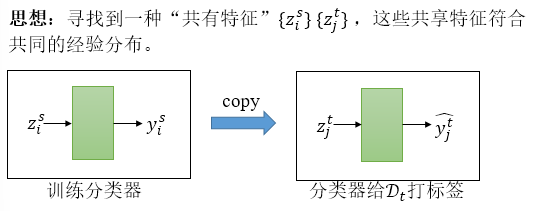
我们把“共有特征”称作“领域不变特征”。
下面我们回顾一下一个重要的工具叫做最大均值差异,利用它就可以抽取领域不变特征。
MMD
MMD用于检验两堆数据是否来源于同一分布,
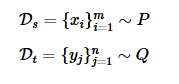
MMD用于检验\(P=Q\)
MMD的经验公式为:
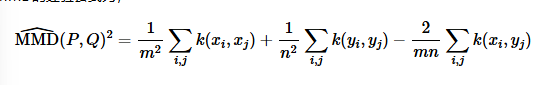

 浙公网安备 33010602011771号
浙公网安备 33010602011771号