
向量变分自动编码器(VQ-VAE)
Oord等人的这篇论文提出了使用离散潜在嵌入进行变分自动编码的想法。提出的模型成为向量量化变分自动编码器
基本思想
VAE由3部分组成:
1.一个编码器网络,参数化潜在的后验\(q(z|x)\)
2.先验分布\(p(z)\)
3.输入数据分布为\(p(x|z)\)的解码器
通常我们假设先验和后验呈对角方差正态分布。然后使用编码器来预测后验的均值和方差。
然而,作者使用离散潜在变量(而不是连续正态分布)。后验分布和先验分布是分类的,从这些分布中抽取的样本索引表。换句话说:
1.编码器对分类分布进行建模,从中进行采样以获得整数值
2.这些整数值用于索引嵌入字典
3.然后将索引值传递给解码器
为什么要这样做?
许多重要的现实世界对象都是离散的。例如,在图像中,我们可能有“猫”、“汽车”等类别,并且在这些类别之间进行插值可能没有意义。离散表示也更容易建模。因为每个类别都有一个值,而如果我们有一个连续的潜在空间,那么我们将需要规范化这个密度函数并学习不同变量之间的依赖关系,这可能非常复杂。
此外,作者声称他们的模型不会遭受后塌陷的影响,而后塌陷是一个普遍困扰VAE并妨碍使用复杂解码器的问题。
架构
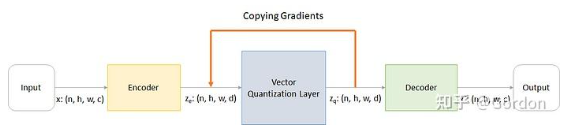
通过以下步骤解释工作原理:
1.编码器接收图像\(x:(n,h,w,c)\)并给出输出\(z_e:(n,h,w,d)\)
2.矢量量化层采用\(z_e\)并根据距离从字典中选择嵌入并输出\(z_q\)
3.解码器消耗\(z_q\)并输出\(x'\)尝试重新创建输入\(x\)
矢量量化层
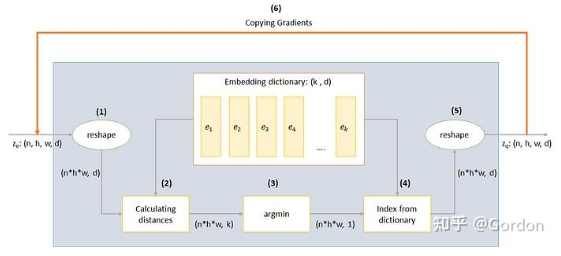
VQ层的工作通过上图中编码的六个步骤来解释:
1.reshape:除了最后一维之外的所有维度都合并为一,这样我们就有\(n*h*w\)个向量,每个向量的维度为\(d\)
2.计算距离:对于每个\(n*h*w\)向量,我们计算与嵌入字典的\(k\)个向量中的每个向量的距离,以获得形状为\((n*h*w,k)\)的矩阵
3.argmin:为每个\(n*h*w\)向量,我们从字典中找到最接近的\(k\)个向量的索引
4.字典索引:为每个\(n*h*w\)向量索引字典中最接近的向量
5.reshape:转换回形状\((n,h,w,d)\)
6.幅值梯度:如果您跟进到现在,您会意识到不可能通过反向传播来训练该架构,因为梯度不会流过argmin。因此,我们尝试通过将梯度从\(z_q\)复制回\(z_e\)来近似。通过这种方式,我们实际上并没有最小化损失函数,但仍然能够将一些信息传回进行训练。
损失函数
总损失实际上油三个部分组成:
1.重建损失:优化解码器和编码器
reconstruction_loss = -log( p(x|z_q) )
2.代码本损失:由于梯度绕过嵌入,我们使用字典学习算法,该算法使用L2误差将嵌入向量\(e_i\)移向编码器输出:
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
// sg 表示停止梯度运算符,意味着没有梯度 stop gradient
3.commitment量化损失:由于嵌入空间的体积是无量纲的,如果嵌入\(e_i\)的训练速度不如编码器参数那么快,那么它可以任意增长,因此我们添加了承诺损失以确保编码器承诺嵌入
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
// β 是一个超参数,控制我们想要衡量的Commitment损失与其他组件相比的多少
Tips
z_vq包含的信息:
- 输入信号的压缩表达:表示输入的主要模式或语义信息
- 空间或时间上的高阶特征:编码了输入信号的结构性和规律性(如频率、形状等)
- 与输入一一对应:即使是量化了,zvq仍然保持和原始输入有较强的结构对应性
可以理解为zvq提供了输入样本的身份信息或语义标签
代码
结论
从这篇论文中我们可以学习到两个主要思想:
1.如何训练离散潜在嵌入及其重要性
2.如何在不可微函数的情况下近似梯度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号