LiteDB源码解析系列(3)索引原理详解
在这一章,我们将了解LiteDB里面几个基本数据结构包括索引结构和数据块结构,我也会试着说明前辈数据之巅在博客中遇到的问题,最后对比mysql进一步深入了解LiteDB的索引原理。
1.LiteDB的五种基本数据结构
在LiteDB的Structures中定义了五个基本数据结构,分别为PageAddress、CollectionIndex、DataBlock、IndexNode和IndexKey。他们各自说明如下:
1.1 PageAddress
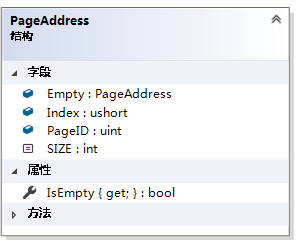
页地址,代表一个数据在页的位置。其中的PageID就是页的ID,Index是数据页或者索引页中字典的key值。根据页的ID和字典key值,就可以找到相应的IndexNode或者DataBlock。将PageID=uint.MaxValue和Index= ushort.MaxValue的页地址作为空页。
1.2 CollectionIndex
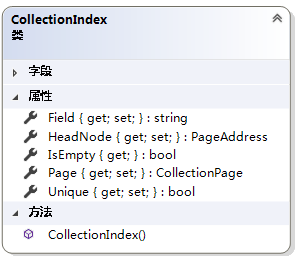
表索引,类似于mysql将表的字段设置为一个索引。属性Field表示存入的字段名称,属性Unique用于标识是否是非重复字段。
1.3 DataBlock
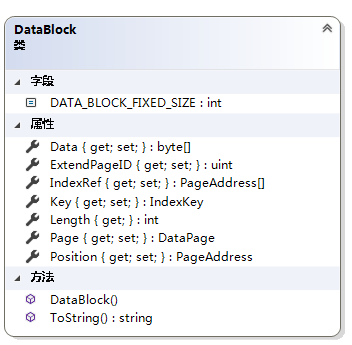
数据块,这个类中Position就是存放在DataPage中的字典索引,比如一个Customer{ID=1,Name=“Jim1”,age=100},将这条记录处理成byte数组也就是属性Data,将该数据块存进DataPage中的字典中,在放入字典的同时,将生成一个key值。DataPage的PageID和字典的key值就作为这个数据块的Position。
IndexRef是一个页地址数组,存储的是索引页的位置。ExtendPageID是指扩展页的ID。Key是这条记录的主键。
1.4 IndexKey

索引键值,这个结构体实现了IComparable接口,主要完成的作用就是将常见的数据类型比如int、byte、string、DateTime转换为统一一个数据类型,然后进行比较。
1.5 IndexNode
索引节点,用来存储一条记录的索引。索引节点之间用跳表来组成数据结构。
注意:属性Position是存放在IndexPage中的字典索引,而DataBlock是存放在DataPage页中字典索。属性Prev和Next分别是指向上一个和下一个节点的IndexPage页地址数组。

2. 举例说明
下面用一个示例来说明索引页、数据页和数据块之间的关系,我创建一个"customer"的表,字段为{“Id”,"Age","Name",},然后插入10记录:{Id=1,Age=1,Name="Jim_1"},{Id=2,Age=2,Name="Jim_2"}.....{Id=10,Age=10,Name="Jim_10"}。大家可以看一下当前的数据展示如下:

从上面可以清楚看到IndexPage里面的IndexNode是有序排列。我们学过排序算法肯定都知道,要想实现排序,必须有比较对象。所以Key就要实现一个IComparable接口,这样所有的IndexNode就可以通过他们的Key值进行排序。对IndexNode的增删改查是用跳表这种数据结构,后面有机会我会专门结合LiteDB讲一下跳表这种数据结构。同时要注意的是IndexNode的链接有Next和Prev,我这里为了简略,只绘制出Next的链接。
我们能看到目前只有一页DataPage,这页DataPage的ItemCount是10,正好对应了10条数据。我再用PPT的模式将IndexNode,DataBlock的关系描述如下:
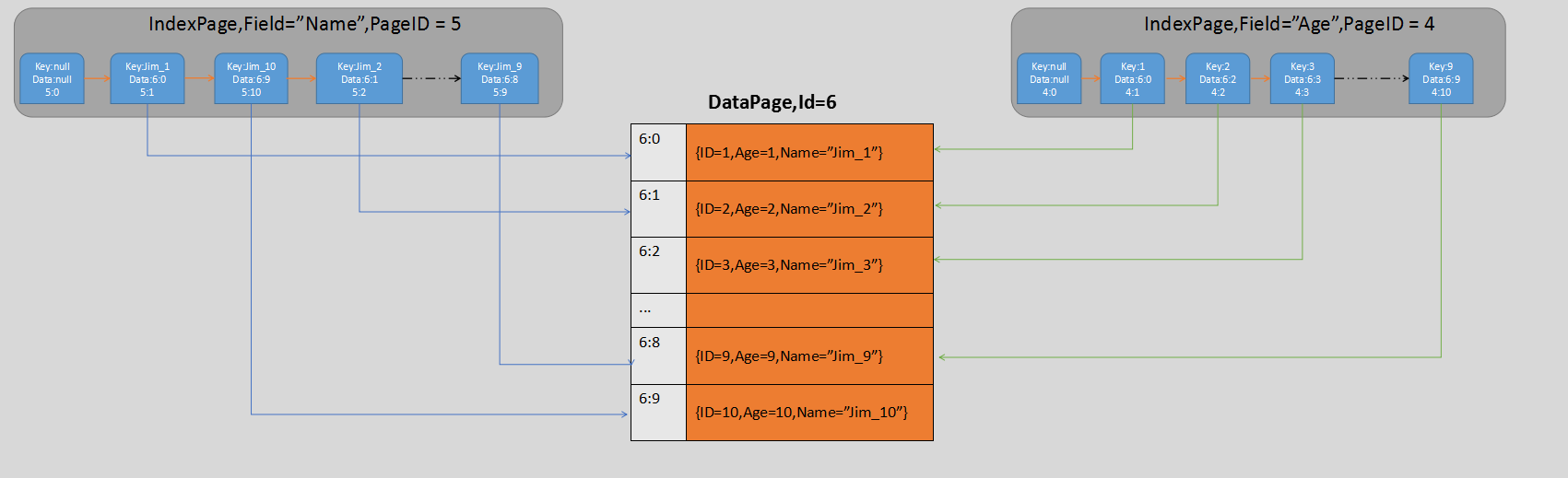
上面这张图就将IndexNode和DataBlock之间关系描述出来了,两个不同的IndexPage中的索引节点指向的是同一个DataPage中的DataBlock。同时请各位注意的是,由于插入的Age是数值,Name是字符串,所以他们各自在索引页里面的排列顺序肯定是不一样的。
3.针对博主数据之巅的疑问
博主数据之巅在分页问题上做了一些尝试,尝试过程中遇到了查询出来的数据ID并不是按顺序排列的问题,我这里截图如下:
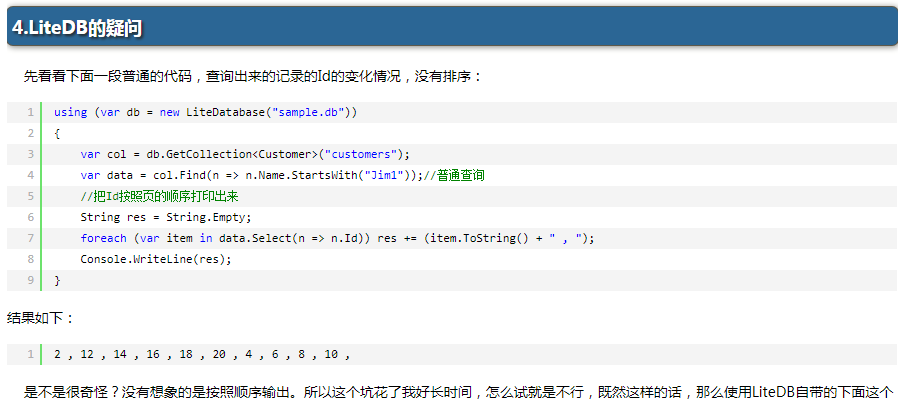
为什么查询出来的ID没有按序排列,这是因为执行n.Name.StartWith("Jim1")的linq语句时,LiteDB就从Field为Name的IndexPage中进行查询,这个IndexPage中的Key装的是字符串变量,那么进行比较的也是字符串。做个简单实验我们就能知道“Jim_1”<"Jim_11"<"Jim_2",这样索引对应的数据查询出来的id就是1,11,2这种顺序了。
4.对比Mysql
如果大家对mysql的索引稍微有些了解的话,应该知道mysql的索引数据结构使用的是B+树,mysql有两种主要的存储引擎叫做InnoDB和MyISM(下面内容转自博客https://www.cnblogs.com/shijingxiang/articles/4743324.html)。
InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
一个表如下图存储了4行数据。其中Id作为主索引,Name作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。
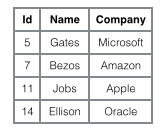
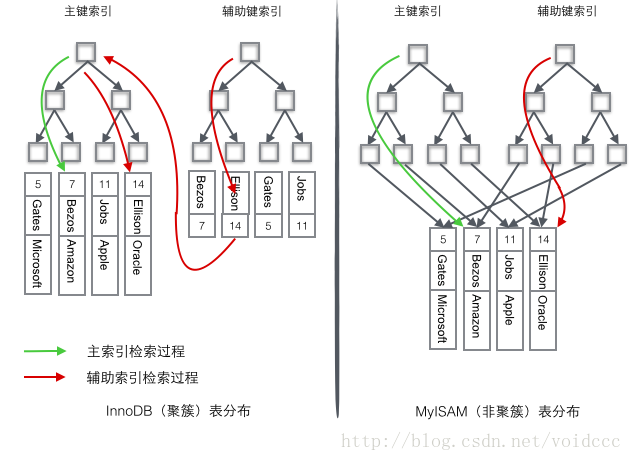
1 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,后面会涉及)会随着数据库里数据的修改而发生变化(前面的B+树节点分裂以及Page的分裂),使用聚簇索引就可以保证不管这个主键B+树的节点如何变化,辅助索引树都不受影响。
最后我们可以看到LiteDB的索引方式和MyISAM类似,不管是主键索引还是辅助索引指向的是数据的地址,只不过LiteDB索引内部是用跳表,而mysql用的是B+树。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号