Pytorch学习笔记 2 使用Pytorch实现线性回归
import torch
from torch.autograd import Variable
设置参数
w = Variable(torch.randn(1), requires_grad = True)
b = Variable(torch.randn(1), requires_grad = True)
w, b
设置损失函数
def get_loss(y_, y):
res = torch.mean((y-y_)**2)
return res
设置要求的回归
def model(x):
return w*x+b
代入数据
x = torch.Tensor([1,2,3,4,5])
y = torch.Tensor([6, 7, 8, 9, 10])
结果如下

使用简单的方法完成回归
epoch = 10000 # 训练的轮次
for i in range(epoch):
y_ = model(x)
loss = get_loss(y_, y) #带入损失函数
loss.backward() # 求梯度
w.data = w.data -1e-2 *w.grad.data # 根据梯度更新参数
b.data = b.data - 1e-2*b.grad.data # 根据梯度更新参数
w.grad.zero_()
b.grad.zero_()
使用优化器实现回归
引入一个新类 torch.nn
Parameter其用途和Variable相同,不同的是它可以被自动注册在module中,且默认可求导
from torch import nn
optimizer = torch.optim.SGD([w, b], lr=0.01) #首先注册优化器
for i in range(epoch):
y_ = model(x)
loss = get_loss(y_, y) #带入损失函数
loss.backward()
optimizer.step() #全部迭代过程都成了这个命令
optimizer.zero_grad() #记得还原为0
结果如下
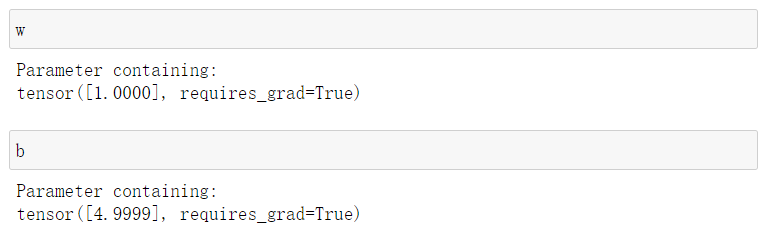
优化器也可使用Adam,此时可以选取一个较大的学习率作为初始值
很喜欢听到一个老师说的“半年理论”,现在做出的努力,一般要在半年的沉淀之后,才能出结果,所以在遇到瓶颈之时,不妨再努力半年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号