scikit基础与机器学习入门(4) sklearn模块数据集的使用——自带数据集和自定义数据集
API通用方法
| 类型 | 获取方式 |
|---|---|
| 自带的小数据集 | sklearn.datasets.load_ |
| 在线下载的数据集 | sklearn.datasets.fetch_ |
| 计算机生成的数据集 | sklearn.datasets.make_ |
load系列
- 鸢尾花数据集: load_iris() 可用于分类 和 聚类
- 乳腺癌数据集: load_breast_cancer() 可用于分类
- 手写数字数据集: load_digits() 可用于分类
- 糖尿病数据集: load_diabetes() 可用于分类
- 波士顿房价数据集: load_boston() 可用于回归
- 体能训练数据集: load_linnerud() 可用于回归
- 图像数据集: load_sample_image(name)
make系列
- make_blobs 可用于聚类和分类
- make_classification 可用于分类
- make_circles 可用于分类
- make_moons 可用于分类
- make_multilabel_classification 可用于多标签分类
- make_regression 可用于回归
例子
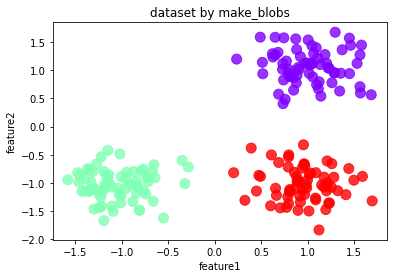
# 生成数据 make_blobs
# 导入相关的库
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib
from sklearn.datasets.samples_generator import make_blobs
# 设置参数 center:聚类中心
# cluster_std:聚类标准差
center=[[1,1],[-1,-1],[1,-1]]
cluster_std=0.3
# 生成样本
X,labels=make_blobs(n_samples=200,centers=center,n_features=2,
cluster_std=cluster_std,random_state = 0)
print('X.shape',X.shape)
print("labels",set(labels))
#np.c_:两矩阵左右相加
df = pd.DataFrame(np.c_[X,labels],columns = ['feature1','feature2','labels'])
#mycolormap = matplotlib.colors.ListedColormap(['red','cyan','magenta'], N=3)
#matplotlib常用colormap:'jet','rainbow','hsv'
df.plot.scatter('feature1','feature2', s = 100,
c = list(df['labels']),cmap = 'rainbow',colorbar = False,
alpha = 0.8,title = 'dataset by make_blobs')
更多的情况可查阅官方文档 Introduction · sklearn 中文文档 (apachecn.org)
很喜欢听到一个老师说的“半年理论”,现在做出的努力,一般要在半年的沉淀之后,才能出结果,所以在遇到瓶颈之时,不妨再努力半年

 浙公网安备 33010602011771号
浙公网安备 33010602011771号