
个人项目
个人项目
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/ |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024/homework/13136 |
| 这个作业的目标 | <完成个人项目,体验开发过程> |
GitHub 链接:https://github.com/xiaoyaosanshi/3122004713
psp表格
| Stage | Activity | Estimated Time (minutes) | Actual Time (minutes) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| Estimate | 估计这个任务需要多少时间 | 845 | 1107 |
| Development | 开发 | 790 | 1042 |
| Analysis | 需求分析 (包括学习新技术) | 100 | 190 |
| Design Spec | 生成设计文档 | 40 | 27 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 40 | 35 |
| Coding | 具体编码 | 400 | 550 |
| Code Review | 代码复审 | 25 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 120 |
组织架构:
1.PaperChecker 类是程序的核心,它将命令行工具的所有功能封装在一个单独的JAVA类中。其包含了四个主要方法:
2.main(String[] args):程序的入口点,处理命令行参数并启动相似度计算过程。
3.calculateSimilarity(String origin, String check, int cutLength):核心算法实现,根据给定的两个字符串计算其相似度。
4.writeResult(String filePath, double similarity):将相似度结果输出至指定文件。
5.calculateHashes(String text, int cutLength):利用给定的分割长度对文本进行分割,并生成文本的哈希集合以用于相似度计算。
核心算法与特色:
算法采用了“子串哈希集合”的概念来进行文本相似度计算,特色如下:
Jaccard相似度: 使用Jaccard指数来衡量两个集合的相似度,这是一种常用于比较样本集的统计量。
适合中文文本: 算法不依赖于空格分隔,因此适合处理中文及类似的非西方语言文本。
灵活的分割策略: calculateHashes方法按照cutLength来将文本切割成子串集合,这允许方法适配于不同长度的文本特征提取。
效率: 算法采用了HashSet来存储和计算交集和并集,相比于列表,它的查找和操作速度快。
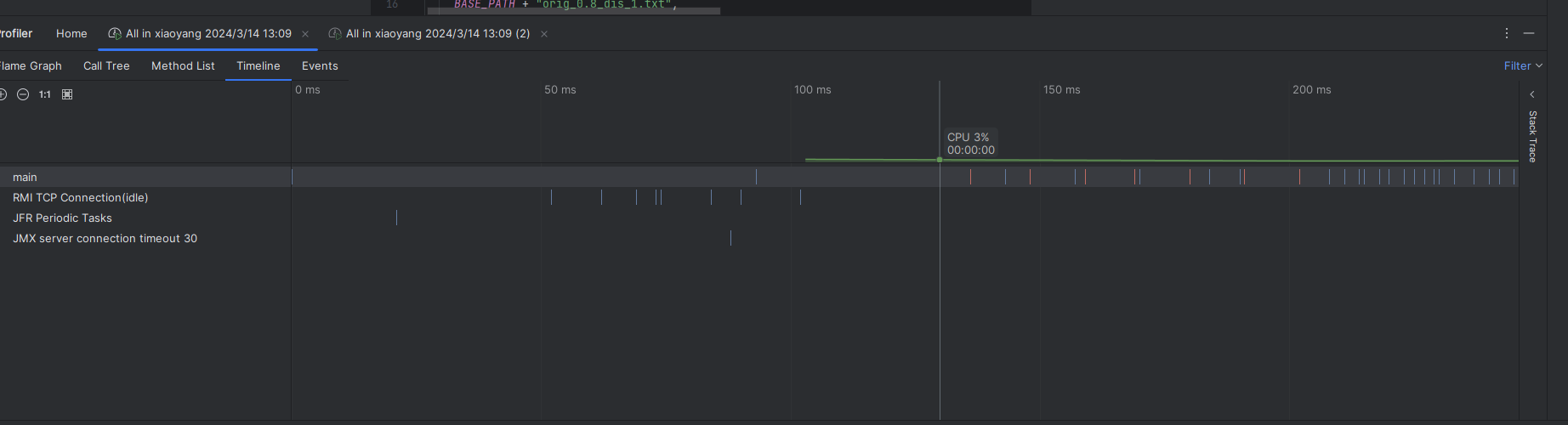
性能记录

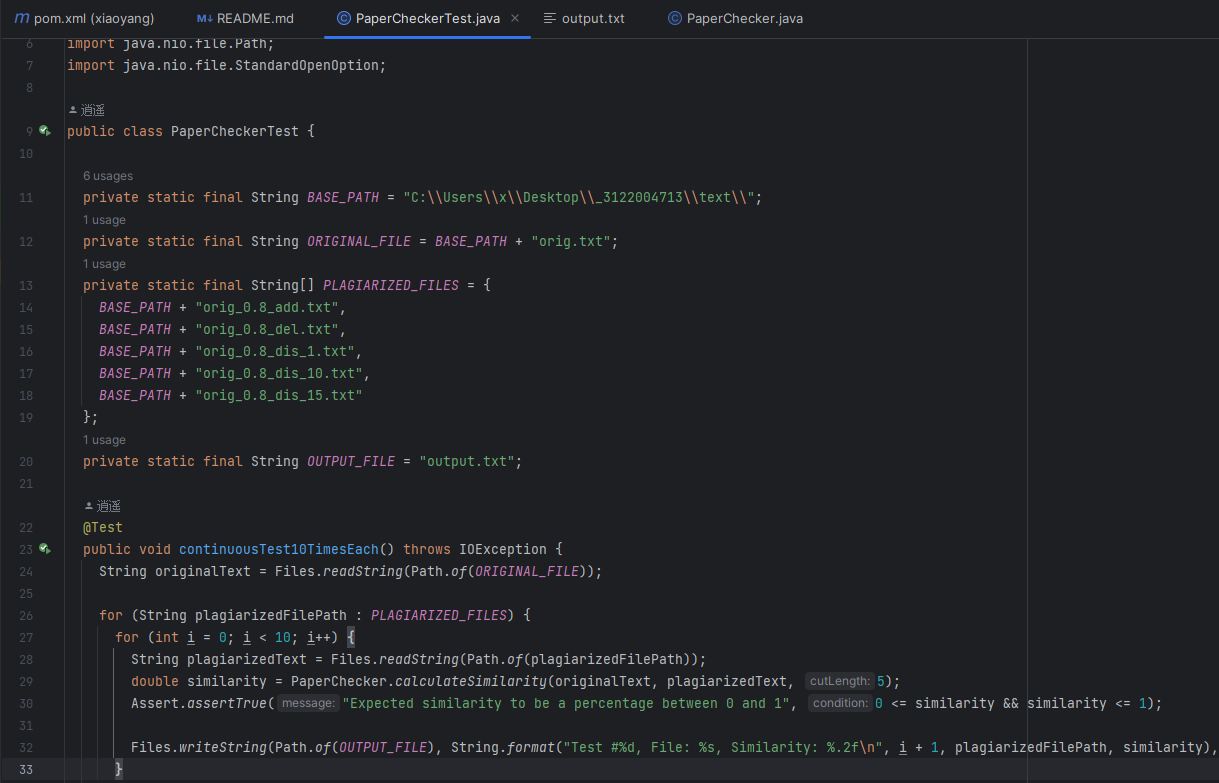
单元测试展示

总结
在开发个人项目的过程中,我经历了一系列充满挑战的学习和实践。本次项目的核心目标是实现一个简洁有效的文本相似度检测工具,用以辅助学术论文的抄袭检查。在这个旅程中,我不仅掌握了使用文本哈希集合进行Jaccard相似度计算的核心算法,而且我还熟悉了使用Java编程语言解决问题的机制。尤为重要的是,我通过这次经历学习到了如何运用PSP表格来有效管理个人软件开发过程,并且我还初步掌握了在GitHub上进行代码版本控制和项目管理的技巧。这些新技能的获得,为我日后的软件开发奠定了坚实的基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号