


面试连环炮系列(十一):说说你们的分布式ID设计方案
-
说说你们的分布式ID设计方案
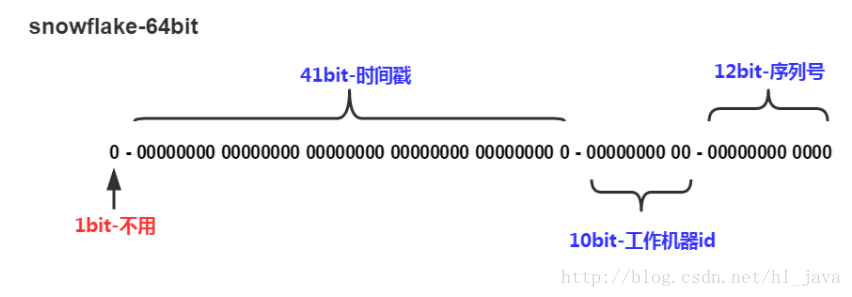
我们采用Snowflake算法,生成一个64bit的数字,64bit被划分成多个段,分别表示时间戳、机器编码、序号。
- 41位的时间序列(精确到毫秒,41位的长度可以使用69年)。
- 10位的机器标识(10位的长度最多支持部署1024个节点)。
- 12位的计数顺序号(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)。
优点: - 时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序。
- 性能高,每秒可生成几百万ID。
- 可以根据自身业务需求灵活调整bit位划分,满足不同需求。
-
Snowflake算法有什么缺点?
它的算法依赖机器时钟,如果机器时钟回拨,会导致重复ID生成。虽然在单机上是递增的,但是分布式环境下,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况。 -
UUID不是更简单吗,为什么不用?
UUID是16字节128位长的数字,以36字节的字符串表示,UUID算法规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。UUID过长,而且没有顺序,不适合用于数据库索引字段。 -
Snowflake算法的ID太长了,有没有更短的方案
可以采用基于Redis的原子操作INCR自增,比如订单号 = 日期 + 当日自增长号。 -
采用Redis方案的缺点是什么?
- 如果系统中没有Redis,还需要引入,增加系统复杂度。
- 需要编码和配置的工作量比较大。
参考(部分摘抄的文字版权属于原作者):
https://blog.csdn.net/hl_java/article/details/78462283
https://www.jianshu.com/p/2456c737aebb
博客作者:编码专家
公 众 号:编码专家
独立博客:codingbrick.com
文章出处:https://www.cnblogs.com/xiaoyangjia/p/11607361.html
本文版权归作者所有,任何人或团体、机构全部转载或者部分转载、摘录,请在文章明显位置注明作者和原文链接。
公 众 号:编码专家
独立博客:codingbrick.com
文章出处:https://www.cnblogs.com/xiaoyangjia/p/11607361.html
本文版权归作者所有,任何人或团体、机构全部转载或者部分转载、摘录,请在文章明显位置注明作者和原文链接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号