


hadoop集群的搭建与配置(2)
对解压过后的文件进行从命名
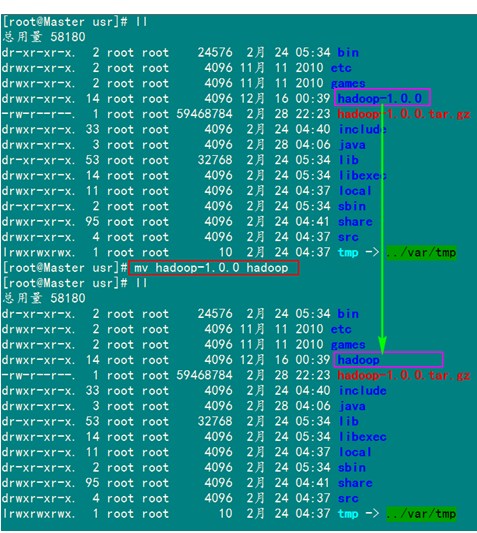
把"/usr/hadoop"读权限分配给hadoop用户(非常重要)
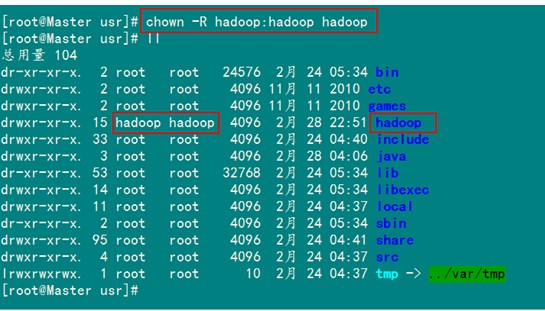
配置完之后我们要创建一个tmp文件供以后的使用

然后对我们的hadoop进行配置文件的配置
vim /etc/profile
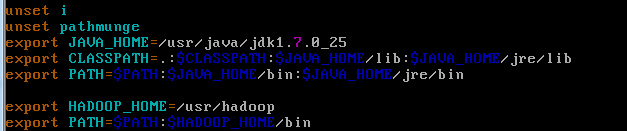
最下边的两行就是我们的hadoop文件的配置内容

重新启动配置文件。
之后要配置hadoop的hadoop-env.sh文件

添加如下内容、

保存退出即可
我们接下来要配置core-site.xml、hdfs-site.xml、mapred-site.xml三个文件了。
通过命令

对文件进行编辑
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<!-- file system properties -->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.9.199:9000</value>
</property>
</configuration>
同样的方法编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<configuration>
注解:因为只有一台Slave1所以配置value为1
编辑mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>http://192.168.9.199:9001</value>
</property>
</configuration>
在我们的Master和Slave1上都要进行master主服务器ip地址的配置


把我们的master的ip地址写入进去,这里在Master服务器和Slave1上都是要配置的
通过一下方式我们可以查看配置的效果

这个时候我们发现配置已经成功了
下面我们还要在我们的主服务器上进行特殊的配置(只有主服务器才进行该配置)
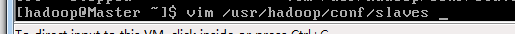

把我们的Slave1的服务器ip地址写入,有几台从服务器就要写入几次。
可以通过

查看我们配置的效果。
同样的道理我们也要在Slave1上进行hadoop的配置,这样才能把环境搭建好,通过以上的四部,进本是所有的需要的配置我们已经搭建完毕了。
(注解中间的配置有些地方是借鉴的博客园里的图片,跟真事的稍微有差别,到时候如果进行hadoop集群的搭建最好是去博客园把他的博客系列简单看看,不然只看我的配置,可能会中间出现不少问题,如果linux基础好的话,上手更快,一般都要花上至少三天的时间来完成两台服务器的搭建的呢)
配置完成之后下面就是要做hadoop的启动了
1)格式化HDFS文件系统
在"Master.Hadoop"上使用普通用户hadoop进行操作。(备注:只需一次,下次启动不再需要格式化,只需 start-all.sh)
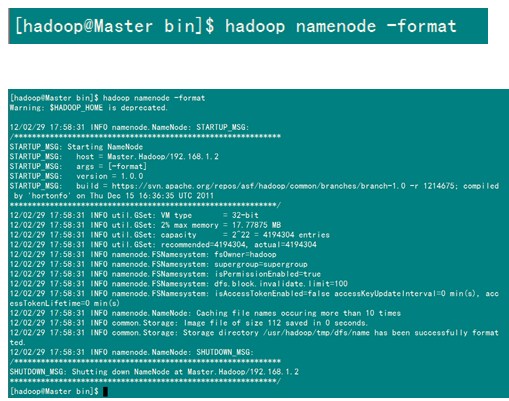
这个时候我们的的格式化已经成功了,但是有一个警告,可以在网上查一下简单的配置就解决了。
2)启动hadoop
在启动前关闭集群中所有机器的防火墙,不然会出现datanode开后又自动关闭。
service iptables stop
关闭防火墙。
使用下面的命令进行启动
start-all.sh
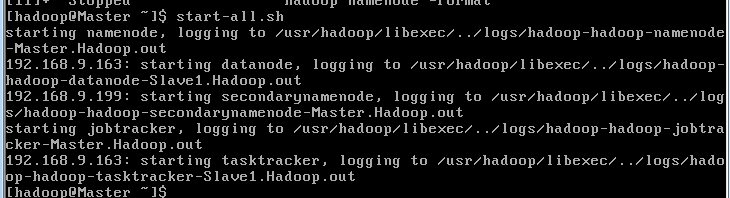
以上工作做完之后没有问题的话我们的hadoop就算是正式启动成功了。
下面我们可以通过两个命令查看是否成功
第一种方式
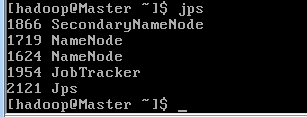
第二种方式
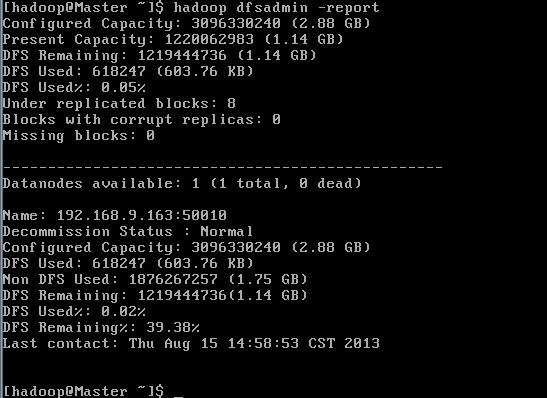
这个时候都看一看出来我们的配置已经成功了。
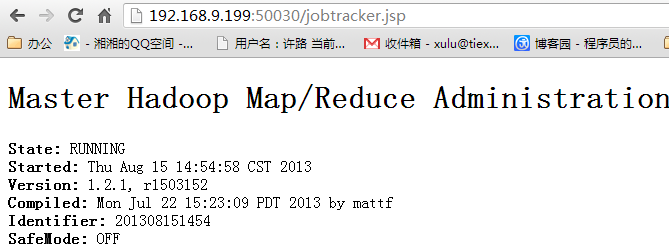
我们还可以通过访问我们的Master的ip地址在浏览器中查看我们的集群的情况
访问"http:192.168.9.199:50030"
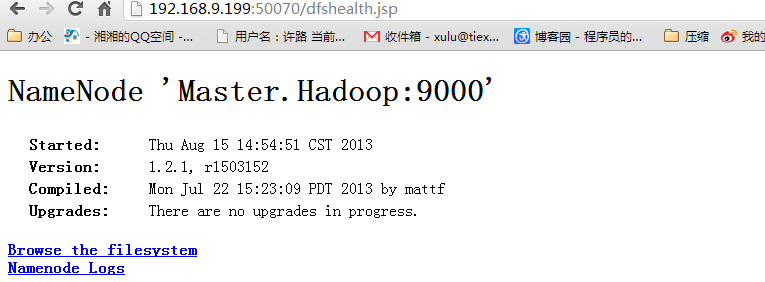
访问"http:192.168.9.199:50070"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号