
ucore操作系统学习(二) ucore lab2物理内存管理分析
一、lab2物理内存管理介绍
操作系统的一个主要职责是管理硬件资源,并向应用程序提供具有良好抽象的接口来使用这些资源。
而内存作为重要的计算机硬件资源,也必然需要被操作系统统一的管理。最初没有操作系统的情况下,不同的程序通常直接编写物理地址相关的指令。在多道并发程序的运行环境下,这会造成不同程序间由于物理地址的访问冲突,造成数据的相互覆盖,进而出错、崩溃。
现代的操作系统在管理内存时,希望达到两个基本目标:地址保护和地址独立。
地址保护指的是一个程序不能随意的访问另一个程序的空间,而地址独立指的是程序指令给出的内存寻址命令是与最终的物理地址无关的。在实现这两个目标后,便能够为多道并发程序运行时的物理内存访问的隔离提供支持。每个程序在编译、链接后产生的最终机器代码都可以使用完整的地址空间(虚拟地址),而不需要考虑其它的程序的存在。ucore通过两个连续的实验迭代,lab2和lab3分别实现了物理内存管理和虚拟内存管理(利用磁盘缓存非工作集内存,扩展逻辑上的内存空间)。
ucore的每个实验都是建立在前一个实验迭代的基础上的,要想更好的理解lab2,最好先理解之前lab1中的内容(lab1学习笔记)。
lab2在lab1平坦模型段机制的基础上,开启了80386的分页机制,并建立了内核页表;同时通过硬件中断探测出了当前内存硬件的布局,并以此为依据根据可用的内存建立了一个物理内存管理框架,通过指定某种分配算法,负责处理所有的物理内存页分配与释放的请求。
lab2的代码结构和执行流程与lab1差别不大,其主要新增了以下功能:
1. bootmain.S中的物理内存探测
2. 在新增的entry.S内核入口程序中开启了80386页机制
3. kern_init内核总控函数中通过pmm_init函数进行整个物理内存管理器的构建初始化
二、lab2实验细节分析
2.1 物理内存布局探测
为了进行物理内存的管理,操作系统必须先探测出当前硬件环境下内存的布局,了解具体哪些物理内存空间是可用的。
ucore在实验中是通过e820这一BIOS中断来探测内存布局的,由于BIOS中断必须在80386的实模式下才能正常工作,因此是在bootloader引导进入保护模式前进行的,代码位于/boot/bootasm,S中。在引导的汇编代码中收集到的数据,通过C中定义的e820map结构体进行映射。
e820map结构:
struct e820map { int nr_map; struct { uint64_t addr; uint64_t size; uint32_t type; } __attribute__((packed)) map[E820MAX]; };
bootasm.S内存布局探测:
# 在实模式下,通过BIOS的e820中断探测当前内存的硬件信息 probe_memory: # 0x8000处开始存放探测出的内存布局结构(e820map) movl $0, 0x8000 xorl %ebx, %ebx # 0x8004处开始存放e820map中的map字段,存放每一个entry movw $0x8004, %di start_probe: # 在eax、ecx、edx中设置int 15h中断参数 movl $0xE820, %eax movl $20, %ecx movl $SMAP, %edx int $0x15 # 如果eflags的CF位为0,说明探测成功,跳转至cont段执行 jnc cont # e820h中断失败,直接结束探测 movw $12345, 0x8000 jmp finish_probe cont: # 设置存放下一个探测出的内存布局entry的地址(因为e820map中的entry数组每一项是8+8+4=20字节的) addw $20, %di # e820map中的nr_map自增1 incl 0x8000 # 0与中断响应后的ebx比较(如果是第一次调用或内存区域扫描完毕,则ebx为0。 如果不是,则ebx存放上次调用之后的计数值) cmpl $0, %ebx # 是否还存在新的内存段需要探测 jnz start_probe finish_probe: # 结束探测
2.2 启用分页机制
ucore在lab2中开启了80386的分页机制,实现了基于平坦段模型的段页式内存管理,为后续虚拟内存的实现做好了准备。
如果对80386分页机制原理不太熟悉的话,可以参考一下我之前的博客:80386分页机制与虚拟内存。
虚拟地址的概念
需要注意的是,在80386分页机制工作原理的许多资料中,开启了页机制后由指令(段选择子+段内偏移)所构成的地址被称为逻辑地址;而逻辑地址通过GDT或LDT等段表转换之后得到的地址被称为线性地址;如果开启了页机制,得到线性地址后还需要查找页表来得到最终的物理地址。
整个的转换过程大致为:逻辑地址->线性地址->物理地址。但虚拟地址这一概念并没有得到统一,在实验指导书中,虚拟地址指的是程序指令给出的逻辑地址,而在有的资料中,则将线性地址称作虚拟地址。查阅有关资料时一定要注意虚拟地址这一概念在上下文中的确切含义,避免产生混淆。
ucore开启分页机制的细节
lab2以及往后的实验中,在ucore的虚拟空间设计中,开启了页机制后的内核是位于高位地址空间的,而低位内存空间则让出来交给用户应用程序使用。
ucore内核被bootloader指定加载的物理地址基址相对lab1而言是不变的。但在开启分页机制的前后,CPU翻译逻辑地址的方式也立即发生了变化。开启分页机制前,内核程序的指令指针是指向低位内存的,而开启了页机制后,我们希望能够正确、无损的令内核的指令指针指向高位地址空间,但保证其最终访问的物理地址不变,依然能够正确的执行。在实验指导书中有专门的一节提到:系统执行中地址映射的三个阶段。
在这里补充一下第二个阶段开启分页模式时的细节:在开启页机制的瞬间是如何巧妙的保证后续指令正确访问的。
根据git仓库上的提交记录,发现ucore开启分页机制的实现细节在2018年初进行了很大的改动。网上许多发表较早的ucore学习博客其内容部分已经过时,在参考时需要注意。(实验指导书的该节标题也有错误:应该是系统执行中地址映射的三个阶段,而不是之前的四个阶段了)。
entry.S
#include <mmu.h> #include <memlayout.h> #define REALLOC(x) (x - KERNBASE) .text .globl kern_entry kern_entry: # REALLOC是因为内核在构建时被设置在了高位(kernel.ld中设置了内核起始虚地址0xC0100000,使得虚地址整体增加了KERNBASE) # 因此需要REALLOC来对内核全局变量进行重定位,在开启分页模式前保证程序访问的物理地址的正确性 # load pa of boot pgdir # 此时还没有开启页机制,__boot_pgdir(entry.S中的符号)需要通过REALLOC转换成正确的物理地址 movl $REALLOC(__boot_pgdir), %eax # 设置eax的值到页表基址寄存器cr3中 movl %eax, %cr3 # enable paging 开启页模式 movl %cr0, %eax # 通过or运算,修改cr0中的值 orl $(CR0_PE | CR0_PG | CR0_AM | CR0_WP | CR0_NE | CR0_TS | CR0_EM | CR0_MP), %eax andl $~(CR0_TS | CR0_EM), %eax # 将cr0修改完成后的值,重新送至cr0中(此时第0位PE位已经为1,页机制已经开启,当前页表地址为刚刚构造的__boot_pgdir) movl %eax, %cr0 # update eip # now, eip = 0x1..... next是处于高位地址空间的 leal next, %eax # set eip = KERNBASE + 0x1..... # 通过jmp至next处,使得内核的指令指针指向了高位。但由于巧妙的设计了高位映射的内核页表,使得依然能准确访问之前低位虚空间下的所有内容 jmp *%eax next: # unmap va 0 ~ 4M, it is temporary mapping xorl %eax, %eax # 将__boot_pgdir的第一个页目录项清零,取消0~4M虚地址的映射 movl %eax, __boot_pgdir # 设置C的内核栈 # set ebp, esp movl $0x0, %ebp # the kernel stack region is from bootstack -- bootstacktop, # the kernel stack size is KSTACKSIZE (8KB)defined in memlayout.h movl $bootstacktop, %esp # now kernel stack is ready , call the first C function # 调用init.c中的kern_init总控函数 call kern_init # should never get here # 自旋死循环(如果内核实现正确,kern_init函数将永远不会返回并执行至此。因为操作系统内核本身就是通过自旋循环常驻内存的) spin: jmp spin .data .align PGSIZE .globl bootstack bootstack: .space KSTACKSIZE .globl bootstacktop bootstacktop: # kernel builtin pgdir # an initial page directory (Page Directory Table, PDT) # These page directory table and page table can be reused! .section .data.pgdir .align PGSIZE __boot_pgdir: .globl __boot_pgdir # map va 0 ~ 4M to pa 0 ~ 4M (temporary) # 80386的每一个一级页表项能够映射4MB连续的虚拟内存至物理内存的关系 # 第一个有效页表项,当访问0~4M虚拟内存时,虚拟地址的高10位为0,即找到该一级页表项(页目录项),进而可以找到二级页表__boot_pt1 # 进而可以进行虚拟地址的0~4M -> 物理地址 0~4M的等价映射 .long REALLOC(__boot_pt1) + (PTE_P | PTE_U | PTE_W) # space用于将指定范围大小内的空间全部设置为0(等价于P位为0,即不存在的、无效的页表项) # KERNBASE/一个物理页的大小(PGSHIFT 4KB即偏移12位)/一个二级页表内的页表项(2^10个) * 4(一个页表项32位,即4byte) # 偏移的距离 - (. - __boot_pgdir) 是为了对齐 .space (KERNBASE >> PGSHIFT >> 10 << 2) - (. - __boot_pgdir) # pad to PDE of KERNBASE # map va KERNBASE + (0 ~ 4M) to pa 0 ~ 4M # 第二个有效页表项,前面通过.space偏移跳过特定的距离,当虚拟地址为KERNBASE~KERNBASE+4M时,能够查找到该项 # 其对应的二级页表同样是__boot_pt1,而其中映射的物理地址为按照下标顺序排列的0~4M, # 因此其最终的效果便能将KERNBASE~KERNBASE+4M的虚拟内存空间映射至物理内存空间的0~4M .long REALLOC(__boot_pt1) + (PTE_P | PTE_U | PTE_W) .space PGSIZE - (. - __boot_pgdir) # pad to PGSIZE .set i, 0 # __boot_pt1是一个存在1024个32位long数据的数组,当将其作为页表时其中每一项都代表着一个物理地址映射项 # i为下标,每个页表项的内容为i*1024作为映射的物理页面基址并加上一些低位的属性位(PTE_P代表存在,PTE_W代表可写) __boot_pt1: .rept 1024 .long i * PGSIZE + (PTE_P | PTE_W) .set i, i + 1 .endr
页表映射关系图:
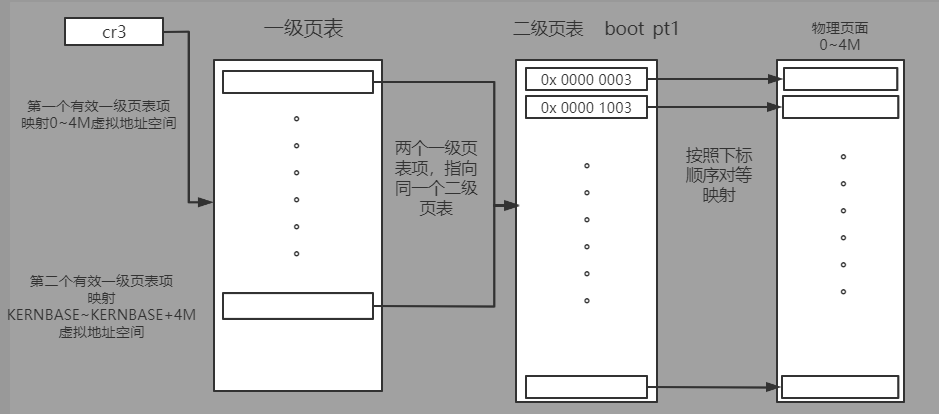
2.3 ucore是如何实现物理内存管理功能的
开启了分页机制后,下面介绍lab2中的重点:ucore是如何实现物理内存管理功能的。初始化物理内存管理器的入口位于总控函数的pmm_init函数。
pmm_init函数:
//pmm_init - setup a pmm to manage physical memory, build PDT&PT to setup paging mechanism // - check the correctness of pmm & paging mechanism, print PDT&PT void pmm_init(void) { // We've already enabled paging // 此时已经开启了页机制,由于boot_pgdir是内核页表地址的虚拟地址。通过PADDR宏转化为boot_cr3物理地址,供后续使用 boot_cr3 = PADDR(boot_pgdir); //We need to alloc/free the physical memory (granularity is 4KB or other size). //So a framework of physical memory manager (struct pmm_manager)is defined in pmm.h //First we should init a physical memory manager(pmm) based on the framework. //Then pmm can alloc/free the physical memory. //Now the first_fit/best_fit/worst_fit/buddy_system pmm are available. // 初始化物理内存管理器 init_pmm_manager(); // detect physical memory space, reserve already used memory, // then use pmm->init_memmap to create free page list // 探测物理内存空间,初始化可用的物理内存 page_init(); //use pmm->check to verify the correctness of the alloc/free function in a pmm check_alloc_page(); check_pgdir(); static_assert(KERNBASE % PTSIZE == 0 && KERNTOP % PTSIZE == 0); // recursively insert boot_pgdir in itself // to form a virtual page table at virtual address VPT // 将当前内核页表的物理地址设置进对应的页目录项中(内核页表的自映射) boot_pgdir[PDX(VPT)] = PADDR(boot_pgdir) | PTE_P | PTE_W; // map all physical memory to linear memory with base linear addr KERNBASE // linear_addr KERNBASE ~ KERNBASE + KMEMSIZE = phy_addr 0 ~ KMEMSIZE // 将内核所占用的物理内存,进行页表<->物理页的映射 // 令处于高位虚拟内存空间的内核,正确的映射到低位的物理内存空间 // (映射关系(虚实映射): 内核起始虚拟地址(KERNBASE)~内核截止虚拟地址(KERNBASE+KMEMSIZE) = 内核起始物理地址(0)~内核截止物理地址(KMEMSIZE)) boot_map_segment(boot_pgdir, KERNBASE, KMEMSIZE, 0, PTE_W); // Since we are using bootloader's GDT, // we should reload gdt (second time, the last time) to get user segments and the TSS // map virtual_addr 0 ~ 4G = linear_addr 0 ~ 4G // then set kernel stack (ss:esp) in TSS, setup TSS in gdt, load TSS // 重新设置GDT gdt_init(); //now the basic virtual memory map(see memalyout.h) is established. //check the correctness of the basic virtual memory map. check_boot_pgdir(); print_pgdir(); }
物理内存管理器pmm_manager初始化
pmm_init在得到了内核页目录表的物理地址后(boot_cr3),便通过init_pmm_manager函数初始化了物理内存管理器框架。该框架(全局变量pmm_manager)是一个被抽象出来的,用于表达物理内存管理行为的函数指针集合,内核启动时会对这一函数指针集合进行赋值。
有了这一层函数指针集合的抽象层后,调用方就可以与提供服务的逻辑解耦了,在不修改任何调用方逻辑的情况下,简单的修改函数指针集合的实现便能进行不同物理内存管理器的替换。如果熟悉面向对象概念的话,就会发现这和接口interface的概念类似,ucore物理内存管理器框架就是以面向对象的思维,面向接口开发的,通过函数指针集合的方式实现多态这一特性。
C语言作为一门较低级的语言,其底层的函数指针功能就是C++/JAVA等面向对象语言中虚函数表的基础,只是C语言本身设计上并不支持语言级的面向对象编程,而必须由开发者手工的编写类似的模板代码,自己实现面向对象语言中由编译器自动实现的逻辑。
init_pmm_manager函数:
//init_pmm_manager - initialize a pmm_manager instance static void init_pmm_manager(void) { // pmm_manager默认指向default_pmm_manager 使用第一次适配算法 pmm_manager = &default_pmm_manager; cprintf("memory management: %s\n", pmm_manager->name); pmm_manager->init(); }
pmm_manager定义:
// pmm_manager is a physical memory management class. A special pmm manager - XXX_pmm_manager // only needs to implement the methods in pmm_manager class, then XXX_pmm_manager can be used // by ucore to manage the total physical memory space. struct pmm_manager { const char *name; // XXX_pmm_manager's name // 管理器的名称 void (*init)(void); // initialize internal description&management data structure // (free block list, number of free block) of XXX_pmm_manager // 初始化管理器 void (*init_memmap)(struct Page *base, size_t n); // setup description&management data structcure according to // the initial free physical memory space // 设置可管理的内存,初始化可分配的物理内存空间 struct Page *(*alloc_pages)(size_t n); // allocate >=n pages, depend on the allocation algorithm // 分配>=N个连续物理页,返回分配块首地址指针 void (*free_pages)(struct Page *base, size_t n); // free >=n pages with "base" addr of Page descriptor structures(memlayout.h) // 释放包括自Base基址在内的,起始的>=N个连续物理内存页 size_t (*nr_free_pages)(void); // return the number of free pages // 返回全局的空闲物理页数量 void (*check)(void); // check the correctness of XXX_pmm_manager };
通过探测出的内存布局设置空闲物理映射空间
ucore使用一个通用的Page结构,来映射每个被管理的物理页面。
其中调用的init_memmap函数,会通过pmm_manage框架的init_memmap,由指定的算法来初始化其内部结构。在ucore lab2的参考答案中,默认使用的是default_pmm_manager,其使用的是效率虽然不高,但简单、易理解的第一次适配算法(first fit)。关于default_pmm_manager的细节,会在下面再展开介绍。
Page结构
/* * * struct Page - Page descriptor structures. Each Page describes one * physical page. In kern/mm/pmm.h, you can find lots of useful functions * that convert Page to other data types, such as phyical address. * */ struct Page { // 当前物理页被虚拟页面引用的次数(共享内存时,影响物理页面的回收) int ref; // page frame's reference counter // 标志位集合(目前只用到了第0和第1个bit位) bit 0表示是否被保留(可否用于物理内存分配: 0未保留,1被保留);bit 1表示对于可分配的物理页,当前是否是已被分配的 uint32_t flags; // array of flags that describe the status of the page frame // 在不同分配算法中意义不同(first fit算法中表示当前空闲块中总共所包含的空闲页个数 ,只有位于空闲块头部的Page结构才拥有该属性,否则为0) unsigned int property; // the num of free block, used in first fit pm manager // 空闲链表free_area_t的链表节点引用 list_entry_t page_link; // free list link };
通过page_init函数可以利用之前在bootasm.S中探测到的e820map布局结构,初始化空闲物理内存空间。
page_init函数:
/* pmm_init - initialize the physical memory management */ static void page_init(void) { // 通过e820map结构体指针,关联上在bootasm.S中通过e820中断探测出的硬件内存布局 // 之所以加上KERNBASE是因为指针寻址时使用的是线性虚拟地址。按照最终的虚实地址关系(0x8000 + KERNBASE)虚拟地址 = 0x8000 物理地址 struct e820map *memmap = (struct e820map *)(0x8000 + KERNBASE); uint64_t maxpa = 0; cprintf("e820map:\n"); int i; // 遍历memmap中的每一项(共nr_map项) for (i = 0; i < memmap->nr_map; i ++) { // 获取到每一个布局entry的起始地址、截止地址 uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size; cprintf(" memory: %08llx, [%08llx, %08llx], type = %d.\n", memmap->map[i].size, begin, end - 1, memmap->map[i].type); // 如果是E820_ARM类型的内存空间块 if (memmap->map[i].type == E820_ARM) { if (maxpa < end && begin < KMEMSIZE) { // 最大可用的物理内存地址 = 当前项的end截止地址 maxpa = end; } } } // 迭代每一项完毕后,发现maxpa超过了定义约束的最大可用物理内存空间 if (maxpa > KMEMSIZE) { // maxpa = 定义约束的最大可用物理内存空间 maxpa = KMEMSIZE; } // 此处定义的全局end数组指针,正好是ucore kernel加载后定义的第二个全局变量(kern_init处第一行定义的) // 其上的高位内存空间并没有被使用,因此以end为起点,存放用于管理物理内存页面的数据结构 extern char end[]; // 需要管理的物理页数 = 最大物理地址/物理页大小 npage = maxpa / PGSIZE; // pages指针指向->可用于分配的,物理内存页面Page数组起始地址 // 因此其恰好位于内核空间之上(通过ROUNDUP PGSIZE取整,保证其位于一个新的物理页中) pages = (struct Page *)ROUNDUP((void *)end, PGSIZE); for (i = 0; i < npage; i ++) { // 遍历每一个可用的物理页,默认标记为被保留无法使用 SetPageReserved(pages + i); } // 计算出存放物理内存页面管理的Page数组所占用的截止地址 // freemem = pages(管理数据的起始地址) + (Page结构体的大小 * 需要管理的页面数量) uintptr_t freemem = PADDR((uintptr_t)pages + sizeof(struct Page) * npage); // freemem之上的高位物理空间都是可以用于分配的free空闲内存 for (i = 0; i < memmap->nr_map; i ++) { // 遍历探测出的内存布局memmap uint64_t begin = memmap->map[i].addr, end = begin + memmap->map[i].size; if (memmap->map[i].type == E820_ARM) { if (begin < freemem) { // 限制空闲地址的最小值 begin = freemem; } if (end > KMEMSIZE) { // 限制空闲地址的最大值 end = KMEMSIZE; } if (begin < end) { // begin起始地址以PGSIZE为单位,向高位取整 begin = ROUNDUP(begin, PGSIZE); // end截止地址以PGSIZE为单位,向低位取整 end = ROUNDDOWN(end, PGSIZE); if (begin < end) { // 进行空闲内存块的映射,将其纳入物理内存管理器中管理,用于后续的物理内存分配 // 这里的begin、end都是探测出来的物理地址 // 第一个参数:起始Page结构的虚拟地址base = pa2page(begin) // 第二个参数:空闲页的个数 = (end - begin) / PGSIZE init_memmap(pa2page(begin), (end - begin) / PGSIZE); } } } } }
初始化完毕后ucore物理内存布局示意图:

其中page_init中的end指向了BSS段结束处,freemem指向空闲内存空间的起始地址。pages(内核页表)位于"管理空闲空间的区域"这一内存块中。实际可用于分配/释放的空闲物理页位于内存空间起始地址~实际物理内存空间结束地址之间。
对虚拟地址进行映射/解除映射
ucore的lab2中有两个练习:
1. 通过一个线性地址来得到对应的二级页表项(pmm.c中的get_pte函数)。得到这个二级页表项地址后,便可以建立起虚拟地址与物理地址的映射关系。
2. 解除释放一个二级页表项与实际物理内存的映射关系(pmm.c中的page_remove_pte函数)。
需要注意的是,开启了页机制后,所有程序指令都是以逻辑地址(虚拟地址)的形式工作的,像指针、数组访问时等都必须是虚拟地址才能正确的工作(例如使用KADDR宏进行转换)。而页表/页目录表中的存放的物理页面基址映射都是物理地址。
get_pte函数:
//get_pte - get pte and return the kernel virtual address of this pte for la // - if the PT contains this pte didn't exist, alloc a page for PT // 通过线性地址(linear address)得到一个页表项(二级页表项)(Page Table Entry),并返回该页表项结构的内核虚拟地址 // 如果应该包含该线性地址对应页表项的那个页表不存在,则分配一个物理页用于存放这个新创建的页表(Page Table) // parameter: 参数 // pgdir: the kernel virtual base address of PDT 页目录表(一级页表)的起始内核虚拟地址 // la: the linear address need to map 需要被映射关联的线性虚拟地址 // create: a logical value to decide if alloc a page for PT 一个布尔变量决定对应页表项所属的页表不存在时,是否将页表创建 // return vaule: the kernel virtual address of this pte 返回值: la参数对应的二级页表项结构的内核虚拟地址 pte_t * get_pte(pde_t *pgdir, uintptr_t la, bool create) { /* LAB2 EXERCISE 2: YOUR CODE * * If you need to visit a physical address, please use KADDR() * please read pmm.h for useful macros * * Maybe you want help comment, BELOW comments can help you finish the code * * Some Useful MACROs and DEFINEs, you can use them in below implementation. * MACROs or Functions: * PDX(la) = the index of page directory entry of VIRTUAL ADDRESS la. * KADDR(pa) : takes a physical address and returns the corresponding kernel virtual address. * set_page_ref(page,1) : means the page be referenced by one time * page2pa(page): get the physical address of memory which this (struct Page *) page manages * struct Page * alloc_page() : allocation a page * memset(void *s, char c, size_t n) : sets the first n bytes of the memory area pointed by s * to the specified value c. * DEFINEs: * PTE_P 0x001 // page table/directory entry flags bit : Present * PTE_W 0x002 // page table/directory entry flags bit : Writeable * PTE_U 0x004 // page table/directory entry flags bit : User can access */ #if 0 pde_t *pdep = NULL; // (1) find page directory entry if (0) { // (2) check if entry is not present // (3) check if creating is needed, then alloc page for page table // CAUTION: this page is used for page table, not for common data page // (4) set page reference uintptr_t pa = 0; // (5) get linear address of page // (6) clear page content using memset // (7) set page directory entry's permission } return NULL; // (8) return page table entry #endif // PDX(la) 根据la的高10位获得对应的页目录项(一级页表中的某一项)索引(页目录项) // &pgdir[PDX(la)] 根据一级页表项索引从一级页表中找到对应的页目录项指针 pde_t *pdep = &pgdir[PDX(la)]; // 判断当前页目录项的Present存在位是否为1(对应的二级页表是否存在) if (!(*pdep & PTE_P)) { // 对应的二级页表不存在 // *page指向的是这个新创建的二级页表基地址 struct Page *page; if (!create || (page = alloc_page()) == NULL) { // 如果create参数为false或是alloc_page分配物理内存失败 return NULL; } // 二级页表所对应的物理页 引用数为1 set_page_ref(page, 1); // 获得page变量的物理地址 uintptr_t pa = page2pa(page); // 将整个page所在的物理页格式胡,全部填满0 memset(KADDR(pa), 0, PGSIZE); // la对应的一级页目录项进行赋值,使其指向新创建的二级页表(页表中的数据被MMU直接处理,为了映射效率存放的都是物理地址) // 或PTE_U/PTE_W/PET_P 标识当前页目录项是用户级别的、可写的、已存在的 *pdep = pa | PTE_U | PTE_W | PTE_P; } // 要想通过C语言中的数组来访问对应数据,需要的是数组基址(虚拟地址),而*pdep中页目录表项中存放了对应二级页表的一个物理地址 // PDE_ADDR将*pdep的低12位抹零对齐(指向二级页表的起始基地址),再通过KADDR转为内核虚拟地址,进行数组访问 // PTX(la)获得la线性地址的中间10位部分,即二级页表中对应页表项的索引下标。这样便能得到la对应的二级页表项了 return &((pte_t *)KADDR(PDE_ADDR(*pdep)))[PTX(la)]; }
page_remove_pte函数:
//page_remove_pte - free an Page sturct which is related linear address la // - and clean(invalidate) pte which is related linear address la //note: PT is changed, so the TLB need to be invalidate static inline void page_remove_pte(pde_t *pgdir, uintptr_t la, pte_t *ptep) { /* LAB2 EXERCISE 3: YOUR CODE * * Please check if ptep is valid, and tlb must be manually updated if mapping is updated * * Maybe you want help comment, BELOW comments can help you finish the code * * Some Useful MACROs and DEFINEs, you can use them in below implementation. * MACROs or Functions: * struct Page *page pte2page(*ptep): get the according page from the value of a ptep * free_page : free a page * page_ref_dec(page) : decrease page->ref. NOTICE: ff page->ref == 0 , then this page should be free. * tlb_invalidate(pde_t *pgdir, uintptr_t la) : Invalidate a TLB entry, but only if the page tables being * edited are the ones currently in use by the processor. * DEFINEs: * PTE_P 0x001 // page table/directory entry flags bit : Present */ #if 0 if (0) { //(1) check if page directory is present struct Page *page = NULL; //(2) find corresponding page to pte //(3) decrease page reference //(4) and free this page when page reference reachs 0 //(5) clear second page table entry //(6) flush tlb } #endif if (*ptep & PTE_P) { // 如果对应的二级页表项存在 // 获得*ptep对应的Page结构 struct Page *page = pte2page(*ptep); // 关联的page引用数自减1 if (page_ref_dec(page) == 0) { // 如果自减1后,引用数为0,需要free释放掉该物理页 free_page(page); } // 清空当前二级页表项(整体设置为0) *ptep = 0; // 由于页表项发生了改变,需要TLB快表 tlb_invalidate(pgdir, la); } }
default_pmm.c 第一次适配分配算法分析
ucore提供了pmm_manager框架,可以支持灵活的切换多种物理内存分配算法。而为了实验的简单性,ucore的参考答案提供了相对好理解的first fit第一次适配算法作为例子,来展示ucore是的物理内存管理功能时如何工作的。
在ucore的第一次适配分配算法中,是通过一个双向链表结构来连接各个连续空闲块的,即定义在default_pmm.c中的free_area_t变量。free_area_t结构十分简单,一个整数nr_free记录着全局保存着多少空闲物理页,另一个list_entry_t类型的变量free_list,作为整个空闲链表的头结点。
free_area_t结构:
/* free_area_t - maintains a doubly linked list to record free (unused) pages */ typedef struct { list_entry_t free_list; // the list header unsigned int nr_free; // # of free pages in this free list } free_area_t;
list_entry_t结构:
struct list_entry { struct list_entry *prev, *next; }; typedef struct list_entry list_entry_t;
回顾一下Page结构的定义,其中包含了一个属性page_link,就可以用于挂载到free_area_t空闲链表中。
ucore通用双向链表介绍
如果对数据结构中的双向链表知识有一定了解的话,可能会对ucore中双向链表的实现感到疑惑。
一般来说,双向链表结构的节点除了前驱和后继节点的指针/引用之外,还存在一个用于包裹业务数据的data属性,而ucore中的链表节点list_entry却没有这个data数据属性。这是因为ucore中的双向链表结构在设计之初是希望能够通用的:不但能将Page结构链接起来,还能链接其它任意的数据。而C语言中并没有c++或是java中的泛型功能,只能定义为某一特定类型的data属性,如果data域与链表的节点定义在一起的话,就没法做到足够通用。
ucore参考了linux中的做法,反其道而行:不再是双向链表的节点包裹数据,而是由数据本身保存链表节点引用。这样设计的最大好处就是链表可以通用,能够链接各种类型的数据结构到一起;但与此同时也带来了一些问题,比如其降低了代码的可读性,编译器也没法确保链表中的数据都是合理的类型。
le2page宏的原理
在对传统的双向链表遍历时,由于是链表节点本身包裹了data,因此可以直接访问到节点关联的data数据。而在ucore的双向链表实现中,由于链表节点本身没有保存data数据,而是反被data数据包裹,因此需要一些比较巧妙(tricky)的方法来实现对节点所属结构的访问。
在空闲链表这一实现中,是由Page结构包裹着链表节点page_link。ucore提供了le2page宏,通过le2page可以由page_link反向得到节点所属的Page结构。
在ucore中,就有通过struct Page *p = le2page(le, page_link)这样的逻辑,其中le是链表节点的指针。
// convert list entry to page #define le2page(le, member) \ to_struct((le), struct Page, member) /* * * to_struct - get the struct from a ptr * @ptr: a struct pointer of member * @type: the type of the struct this is embedded in * @member: the name of the member within the struct * */ #define to_struct(ptr, type, member) \ ((type *)((char *)(ptr) - offsetof(type, member))) /* Return the offset of 'member' relative to the beginning of a struct type 返回member到结构起始地址的相对偏移*/ #define offsetof(type, member) \ ((size_t)(&((type *)0)->member))
可以看到le2page宏是依赖to_struct这一通用宏来实现的。在le2page中,其传递给to_struct宏的三个参数分别是链表的指针ptr,type为Page结构体本身的定义,member为page_link。
C语言中,结构体中数据结构的最终在虚拟内存空间中是按照属性的顺序,从低位到高位排列的,而page_link的指针地址必然高于Page结构的基地址,且两者之间的差值可以通过结构体中的定义得到。在to_struct中,通过ptr(即page_link的指针地址)减去offset(type,member)(即page_link到Struct Page结构的相对偏移),便能够得到page_link节点所属Page结构的首地址。最后通过type *,将其强制转换为对应的Page指针。
offsetof宏巧妙的构造了一个位于起始地址0的type类型指针,并通过&获得其member属性的地址。由于其结构指针的初始地址为0,则最后得到的就是member字段相对于type结构基址的相对偏移量了。
这是C语言中通过结构体中某一属性地址访问其所属结构体的一种巧妙实现。
le2page宏对于C语言的初学者来说确实不是很好理解,连注释中都指出这一做法有些tricky,但在理解其原理之后,未来实验中更多依赖to_struct宏的地方就不会再被困扰了。
le2page原理图:

default_pmm.c 第一次适配分配算法中的分配与释放功能的分析
default_pmm.c中完整的实现了pmm_manager所指定的函数接口,限于篇幅,这里只重点介绍其分配与释放物理内存页的功能。
分配物理内存页的功能由default_alloc_pages函数完成;释放物理内存页的功能由default_free_pages函数完成。
default_alloc_pages函数:
/** * 接受一个合法的正整数参数n,为其分配N个物理页面大小的连续物理内存空间. * 并以Page指针的形式,返回最低位物理页(最前面的)。 * * 如果分配时发生错误或者剩余空闲空间不足,则返回NULL代表分配失败 * */ static struct Page * default_alloc_pages(size_t n) {
assert(n > 0); if (n > nr_free) { return NULL; } struct Page *page = NULL; list_entry_t *le = &free_list; // TODO: optimize (next-fit) // 遍历空闲链表 while ((le = list_next(le)) != &free_list) { // 将le节点转换为关联的Page结构 struct Page *p = le2page(le, page_link); if (p->property >= n) { // 发现一个满足要求的,空闲页数大于等于N的空闲块 page = p; break; } } // 如果page != null代表找到了,分配成功。反之则分配物理内存失败 if (page != NULL) { if (page->property > n) { // 如果空闲块的大小不是正合适(page->property != n) // 按照指针偏移,找到按序后面第N个Page结构p struct Page *p = page + n; // p其空闲块个数 = 当前找到的空闲块数量 - n p->property = page->property - n; SetPageProperty(p); // 按对应的物理地址顺序,将p加入到空闲链表中对应的位置 list_add_after(&(page->page_link), &(p->page_link)); } // 在将当前page从空间链表中移除 list_del(&(page->page_link)); // 闲链表整体空闲页数量自减n nr_free -= n; // 清楚page的property(因为非空闲块的头Page的property都为0) ClearPageProperty(page); } return page; }
default_free_pages函数:
/** * 释放掉自base起始的连续n个物理页,n必须为正整数 * */ static void default_free_pages(struct Page *base, size_t n) { assert(n > 0); struct Page *p = base; // 遍历这N个连续的Page页,将其相关属性设置为空闲 for (; p != base + n; p ++) { assert(!PageReserved(p) && !PageProperty(p)); p->flags = 0; set_page_ref(p, 0); } // 由于被释放了N个空闲物理页,base头Page的property设置为n base->property = n; SetPageProperty(base); // 下面进行空闲链表相关操作 list_entry_t *le = list_next(&free_list); // 迭代空闲链表中的每一个节点 while (le != &free_list) { // 获得节点对应的Page结构 p = le2page(le, page_link); le = list_next(le); // TODO: optimize if (base + base->property == p) { // 如果当前base释放了N个物理页后,尾部正好能和Page p连上,则进行两个空闲块的合并 base->property += p->property; ClearPageProperty(p); list_del(&(p->page_link)); } else if (p + p->property == base) { // 如果当前Page p能和base头连上,则进行两个空闲块的合并 p->property += base->property; ClearPageProperty(base); base = p; list_del(&(p->page_link)); } } // 空闲链表整体空闲页数量自增n nr_free += n; le = list_next(&free_list); // 迭代空闲链表中的每一个节点 while (le != &free_list) { // 转为Page结构 p = le2page(le, page_link); if (base + base->property <= p) { // 进行空闲链表结构的校验,不能存在交叉覆盖的地方 assert(base + base->property != p); break; } le = list_next(le); } // 将base加入到空闲链表之中 list_add_before(le, &(base->page_link)); }
三、总结
从ucore lab2的实验pmm_manager框架的实现中使得我进一步的意识到面向对象,或者说是面向接口/协议编程并不是面向对象语言的专属。面向对象这一概念更多的是一种通过抽象、聚合进行模块化,降低系统复杂度的一种思想。在ucore中就用C语言以面向对象的方式,解耦了具体的物理内存分配策略与使用物理内存管理逻辑的解耦,而在《计算机程序的构造与解释》SICP一书中,便是用lisp这一被公认为是函数式编程范式的语言实现了一个面向对象的系统。面向对象与函数式这两种编程范式并不是水火不容的,而都是作为一种控制系统整体复杂度的抽象手段之一。
仔细观察pmm_manager框架的设计,可以明显感到C的多态实现不如支持面向对象编程的语言优雅,需要额外编写许多模板代码,且无法得到编译器更多的支持。这样一种类似设计模式的繁琐实现方式,在某种程度上来说也体现了C语言本身表达能力不足的缺陷,也是后来C++出现的一个主要原因。
通过ucore的实验,令我们能从源码层面实现不同物理内存的分配算法(挑战练习中要求实现更复杂的伙伴系统、slab分配器),使得操作系统书籍、原理课上讲解的相关理论不再枯燥,而是变得栩栩如生了,
这篇博客的完整代码注释在我的github上:https://github.com/1399852153/ucore_os_lab (fork自官方仓库)中的lab2_answer。
希望我的博客能帮助到对操作系统、ucore os感兴趣的人。存在许多不足之处,还请多多指教。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号