Python基础第五天——字符编码、文件处理、函数的使用
一、拾遗
1、常量
定义:不变的量叫做常量
例:
MYNAME = "xiaobai"
2、变量的命名规范
(1)驼峰法
例:MyAge = 18
(2)下划线
例:my_age = 18 # 官方推荐此写法
二、字符编码
1、文本编辑器
常用的文本编辑器有:记事本、word、vim编辑器、Notepad++、Pycharm等
(1)文本编辑器存储文件的原理:
打开:
打开文本编辑器就是将文本编辑器放到内存里了。
编辑:
在文本编辑器里输入的任何内容都是存放在内存中,若突然断电则编辑的内容不会被保存(有些文本编辑器自带自动保存功能)
保存:
要想永久保存就必须将内存中的数据刷到硬盘里,选择保存的路径然后保存一个文件的形式储存在硬盘里
(2)python解释器执行文件的原理:
首先编写一个python程序并保存到指定路径
然后让python解释器到指定路径打开此程序解释,并执行(翻译)该程序: python d:/指定路径/ 文件名.py (读的过程)
运行python程序的过程中实际上经历了3个阶段:
<1>python解释器先启动(存放在内存)
<2>python解释器再从硬盘读取python文件,把python文件里的内容当成普通字符读到内存里
<3>解释并执行python文件
所以python解释器具备读文件的功能,与其它文本编辑器不同之处在于多了解释并执行这一步,其它文本编辑器只是打印显示。
2、字符编码
定义:
要想让计算机工作计,就必须通电,而计算机只认高低电平,为了让计算机能听人的指示去干活,就必须要通过一套人制定好的标准去干活。这套标准就叫做字符编码
常见的字符编码介绍:
字符编码起源于美国,所以字符编码是基于英文考虑的。
(1)ASCII
一个字符用一个Bytes表示。1Bytes = 8bit,bit就是二进制位

二进制转十进制的换算:
例:
二进制数:11001
转换成十进制:1*(2**4)+1*(2**3)+0*(2**2)+0*(2**1)+1*(2**0)=25
(2)GBK
为了满足中国人的需求,中国人定制了GBK
GBK用2个Bytes表示一个字符,也就是16个bit
但是其他国家也照此方法用2个Bytes定制了自己国家语言的字符编码,此时就出现了乱码
(3)unicode
unicode字符编码又称为万国码,它是为了解决乱码现象而产生的
unicode用2个Bytes表示一个字符,兼容万国语言
(4)补充:容量单位的换算
最小单位是bit
1 Bytes = 8 bit
1 KB = 1024 Bytes
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
......
(5)utf-8
unicode字符编码本来可以世界通用了,但是对于万恶的美国人来说,每个英文字符也要占2个Bytes,增加了一倍的空间,于是美国人抛弃了这种万国码,为了迎合万恶的美国人,于是就产生了utf-8这种字符编码。
utf-8是一种可变长的字符编码,存英文字符时用1Bytes表示,对中文字符用3Bytes表示
此时,字符编码终于统一了。
(6)unicode与utf-8的特点与应用场景
这两种字符编码对比
unicode:所有字符都是占2个Bytes,优点是字符转数字的速度最快。缺点是占用空间大
utf-8:英文占1个Bytes,中文占3个Bytes,优点是精准、省空间。缺点是字符转数字的速度慢,是因为每次都要对字符进行判断才能精准地表示。
所以,综上述两种编码应用以下的场景:
1、内存中使用的编码是unicode,虽然会多占空间,但是转换速度快,生产场景中的需求是内存的速度尽可能保证快
2、硬盘与网络传输则用的编码是utf-8,占用空间小,保证数据稳定。虽然速度慢,但是由于网络I/O的延迟与硬盘I/O的延迟要远大于utf-8的转换速度,所以并不影响

3、编码与解码:
编码:encode,以一种字符编码标准如GBK,再由内存将编码好的字符保存至硬盘中,encode的结果就是一个Bytes类型,一个Bytes有8个bit位
解码:decode,由硬盘将编码好的字符以一种字符编码如GBK释放到内存中
打一个比方来形象地解释编码与解码:
抗战时期,我军通讯兵通过电报为了把军情安全地发送至总司令部,于是事先定义了一张码表(这就好比计算机中的字符编码),便把军情通过这张码表进行了加密(这就类似于计算机中的编码——encode),电报传送至总司令部后,总司令部的通讯兵又将这份加密后的电报通过码表进行翻译(这就类似于计算机中的解码——decode)最终得到军情。
注意事项:文件按什么编码存的就一定要按什么编码解开,否则会出现乱码。
在python3中默认是以unicode识别的。
4、声明Python解释器的字符编码:
在python文件中第一行加上:
# -*- coding:utf-8 -*- 或 coding:utf-8(指定的字符编码,本例用utf-8)
5、python程序的执行
阶段一:启动python解释器
阶段二:python解释器负责打开python文件,即从硬盘中读取python文件的内容到内存中。
6、unicode的特性:
unicode可以encode任何编码。不可以decode
内存里全是unicode是建立在文件内容未执行的基础之上,把文件内容全部读到内存中,此时内存中的代码全部是unicode编码的。
在执行阶段,开发人员可以将unicode控制——encode任何编码
例:
print("hahaha") # 以unicode编码存的。
x = "小白" # 以unicode编码存的。
y = "小白".encode("utf-8") # 变量y现在是一个经过utf-8编码后的bytes类型,
# 这种情况是在unicode编码后的基础上,再进行以“utf-8”编码后得到的Bytes类型
print(y) # 用此方法表示bytes类型:


7、Python2与Python3的字符编码区别:
(1)Python2
在python2中怎样定义str?
python2默认的字符编码是ascii
python2里的str被识别成bytes,是因为python2它自作主张,把str encode成bytes类型再存到内存空间里了,所以我们在python2中看到的字符串是编码后的结果。那么内存中的unicode要编码就需要一个标准,这个标准就是按照文件头指定的字符编码而编码的。
python2定义一个字符串相当于经历的过程如下:
1、自动将“你好”这个字符串encode成文件头指定的字符编码:
,若头文件没有指定则默认用Python2自带的accsii码。
2、得到encode后的结果:
3、最后把encode后的结果再赋予变量"x":
。


图示:

总结:
Pyhon2里的str就是bytes。是按文件头的字符编码进行encode的。若没指定字符编码则按默认的字符编码ascii进行encode。
(2)Python3
unicode可以encode任意字符编码,(就是Bytes类型,Bytes类型是编码后的结果)但不能decode。
识别字符串是在执行阶段才有的概念
pyhton3默认的字符编码是utf-8
python3的str是unicode,bytes是编码后的结果。

补充:
unicode只能encode任何编码,encode指定编码后就是bytes类型。用什么字符编码编码的就一定要用什么字符编码解码。
unicode不能decode
图示:

总结:
Pyhon3里的str被定义为unicode
8、乱码解决方法:
乱码是在两个阶段发生的:
(1)无解:一种是在存的时候发生乱码,这种方式无解,文件就废了。
(2)有解:另一种情况发生乱码有解。文件本身没乱码,例如存的时候是以utf-8格式存的,而读的时候却以gbk方式读就产生了乱码,这时只需要换成utf-8的字符编码即可解决乱码。
三、文件处理
操作系统为我们提供了文件系统,文件系统里面都是一个个的文件,所以想要对硬盘做存取操作就必须以文件为单位进行操作。我们用python写的是应用程序,应用程序是不能直接操作硬件的。而读写硬盘又需要对硬件进行操作,所以应用程序只能对操作系统发起调用,让操作系统来帮应用程序对硬盘进行操作。
open()
定义:python向操作系统发起系统调用的一函数,告诉操作系统需要打开一个文件进行读写的操作。
语法:
变量 = open(“文件的路径以及文件名”,“打开文件的模式”,encode =“指定字符编码”)
例:
f = open("a.txt") # 打开文件的模式不写默认是以"r"读的方式打开
# 变量f表示向操作系统发起调用后所返回的结果。
print(f) # f 是一个对象,得到结果为:<_io.TextIOWrapper name='a.txt' mode='r' encoding='cp936'>
f.close()
f.close()表示关闭文件。
打开一个文件就会占着内存空间,必须用f.close()对其进行关闭。否则这个文件会一直处于打开的操作,会一直占用资源。
1、文件的r模式:
例:
f = open('a.txt','r',encode='utf-8')
“r” 如果不写默认也是以读的方式打开文件,r模式若文件不存在则会报错。
(1)f.read()
f.read()表示对文件进行读操作。它将读取文件中的所有内容,文件中的光标位置会移至文件末尾
例:
首先在windows操作系统下创建一个a.txt的文件,往a.txt里写放一些字符然后保存起来,(若不指定字符编码,pycharm默认是以utf-8编码方式保存的。)

然后对a.txt文件进行读操作,一运行程序发现是乱码。

原因:
open()是向windows操作系统发起一个调用,要求打开a.txt这个文件。没有指定字符编码,那么此时windows操作系统就默认按它自己的字符编码——GBK的方式去返回打开a.txt的结果了。而a.txt又是以utf-8编码方式存储的,所以就会报乱码的错误了。
解决方法:
告诉windows操作系统a.txt这个文件用utf-8的方式打开。此时就不会报错了。
f = open('a.txt',encode='utf-8')

(2)f.readline()
f.readline()表示读一行。光标位置则在该行的末尾
(3)f.readlines()
f.readlines()表示将文件的每一行都读出来存成一个列表的形式,每一行都带着一个换行符。
2、文件的w模式:
例:
f = open('a.txt','w',encode='utf-8')
w模式在文件存在的情况下会覆盖,在文件不存在的情况下会创建新文件。
(1)f.write()
往文件里存取内容都是字符串
所以f.write()往文件写必须是字符串
例:
f.write(123456) # 错误,必须是字符串形式
f.write("123456") # 正确
若写多个f.write()操作,想要有换行效果则在每个f.write()中手动加上换行符。
例:

# 以上例子也可以用一个 f.write()来写:f.write("hello,xiaobai\n","嗨,小白\n")
输出结果:

(2)f.writelines()
以列表的方式往文件里写入内容,要注意的是列表里的元素必须是字符串。
格式:
f.writelines(['元素1\n','元素2\n','元素3\n', ......])
例:

# 以上例子与 f.write()类似,f.writelines的优点在于:以列表为单位写入。
输出结果:
3、文件的a模式:
a模式在文件存在的情况下文件内容不会被覆盖,写内容是追加的方式写,这种模式的光标位置在内容的最后。在文件不存在的情况下会创建新文件。
应用场景:写日志操作
例:

输出结果:
4、文件的其它方法:
例:
f = open('a.txt','r',encoding='utf-8')
(1)f.flush()
对一个文件写数据,实际上是先写到内存里,操作系统会定期把数据从内存往硬盘里刷。如果想让数据写完就立刻刷入硬盘,则加上f.flush()。

(2)f.closed()
判断文件是否是关闭。打印f.closed()得到布尔值,关闭状态为True,未关闭状态为False
例:

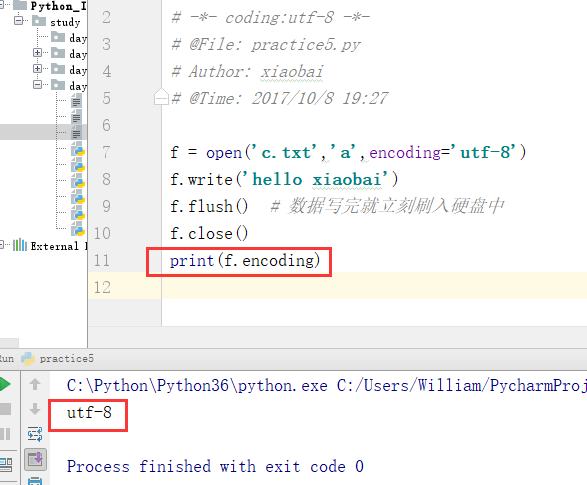
(3)f.encoding
查看字符编码
(4)f.name
查看文件名

(5)f.readable()
判断文件是否可读,r模式为True,w和a模式为False

(6)f.writable()
与f.readable()正好相反,判断文件是否可写,w和a模式为True,r模式为False

5、文件内光标移动
(1)f.read()
读操作,表示以字符为单位移动光标,括号内若不加参数则读取文件全部内容,光标位置在文件内容的最后。
例1:
f = open('a.txt','r',encoding='utf-8')
print(f.read(3))
# f.read()可以指定参数,表示以字符为单位移动光标,其它方法中的移动光标如:f.seek()、f.truncate()都是以字节为单位的移动光标。
例2:
c.txt的内容:

用f.read()取出文件内容:

(2)f.seek() (重点)
读操作,表示以字节为单位移动光标,以文件起始位置作为参照物。括号里是一个参数时每次默认以文件起始位置操作。
<1> 例1:用f.seek(0)将光标回到起始位置。
c.txt的内容:

解决方法:用f.seek()将光标位置回到文件的开头位置。

<2>f.seek()中的参数
f.seek()括号中实际上有两个参数,括号里只写一个参数时,表示第二个参数的值为0,0表示光标从文件起始位置进行移动。
第二个参数一共有3个值,分别是0、1、2
0:表示光标从文件起始位置进行移动
1:表示光标从当前位置进行移动
2:表示光标从文件末尾倒过来进行移动
例1:光标从文件起始位置进行移动
c.txt的内容:

例2:用f.seek()将光标从当前位置进行移动
如果直接在例1中的第2个f.seek()括号里加上参数则会出现以下情况:

原因在f.seek()是以字节为单位进行光标移动的,但是在 “r” 模式下是字符形式的。
所以又引出一个新的知识点:
r、w、a模式是“字符”形式的
rb、wb、ab模式是“字节”形式的
如果用了rb、wb、ab模式对一个文件进行操作,如果再指定字符编码则会报错。因为此时文件的内容就是二进制(bytes)形式的。(我们还是能看到文件的内容是因为这些二进制的内容是通过软件从硬盘读到内存,经过内存的解码才让我们看到内容。)
rb模式:
例:查看c.txt里的内容:

如果想要查看c.txt文件里的内容,则需要进行解码,因为是c.txt里的内容是以utf-8进行编码存储到硬盘的的,所以一定要以utf-8进行解码:

wb模式:
例:用wb模式往b.txt文件里写入内容
如果直接用往b.txt文件里写入字符串则会报错,提示不能以字符串的形式写入,必须以bytes的形式写入。

所以在“wb”模式下必须改成bytes形式才能写入:

查看b.txt里的内容,已成功写入了:

补充:
(1)rb、wb、ab模式的作用
ab与wb同似,就不举例了。
那么以rb、wb、ab这几种模式对文件操作有什么好处呢?(重点)
答:读操作就是以bytes方式读的,写操作也是以bytes方式去写的,所以这几种模式不会出现乱码的问题。可以用于打开图片、视频的操作。
例:对一个图片文件进行操作
a.jpg的内容如下:

如果直接用r模式进行读操作,则会报错:

因为图片不是字符串,如果想读到图片的内容就只能以rb模式读取图片的二进制:

因为图片存的不是字符编码格式的二进制,而是图片格式的二进制,所以不能用字符编码进行decode。
(2)读出图片内容
补充:
拷贝的原理:
对一个文件进行拷贝操作,拷贝文件是打开原文件从原文件读内容,然后再打开一个新文件并将原文件的内容往这个新文件里一行一行地写。这就是拷贝的过程。
下面写一个模拟拷贝功能的代码把将图片的内容读出来:

打开a.copy.jpg,此时完成了拷贝的操作。

<3> 接第<2>点中f.seek()中的参数细讲
例1:
f.seek()第二个参数为“1”时:
表示接上一个f.seek()的位置
要求:让第二个f.seek()接上次位置开始移动
c.txt文件中的内容:


例2:
f.seek()第二个参数为“2”时:
表示以文件内容的末尾开始作为参照位置。
c.txt文件的内容,一共是43个字节
当第二个参数为2,第一个参数为0时,表示从文件光标从末尾开始,倒着移动了0个bytes。

当第一个参数是负数,第二个参数是2时,表示光标从文件末尾开始,倒着往前移动。

用decode查看读到的内容:

(3)f.tell()
读操作,也是以字节为单位,告之光标所在的位置。
例:

(3)f.truncate()
写操作,(必须以w模式或a模式才能进行操作,否则报错)表示截断,从文件开头到指定位置,以字节为单位
例:

查看C.txt文件的内容:表示截断至第10个字节的位置。

6、文件的路径
因为是在windows系统上打开的文件,所以文件的路径如果要用到绝对路径时,则:
(1)绝对路径的分隔符改为两个斜杠
第一个斜杠表示转义,用来转义第二个斜杠的,使第二个斜杠变成普通的字符串。

(2)在绝对路径前加上小写字母“r”
表示原生字符串,里面的“\”都变成无意义的字符串了。

7、文件的修改
我们平时对一个文件进行修改时需要做的步骤是打开一个文件编辑器放至内存中,然后才能对文件的内容进行修改。我们对文件进行修改实际上是修改内存中的内容,再将修改好的新内容覆盖掉硬盘上的旧内容。所以得出以下结论:
1、文件的修改必须是在内存中进行,2、文件的修改就是覆盖操作。
例:
写一个类似文本编辑器的软件将c.txt内容中的“小白”改成“大神”。
c.txt中的内容如下:

操作的思路:
首先打开文件——一行一行地读文件(循环的方式读)——判断“小白”是否在这行内——把“小白”替换成“大神”——把修改好的内容覆盖掉旧文件

文件中的一行行的内容是不依赖索引的
如果用f.readlines()是使用索引的,它是把文件中所有内容以列表的形式都放到了内存中,文件内容的每一行为列表的元素,然后进行循环判断。此方法虽然可以完成替换的要求,但是很占内存且不适用于工作场景。方法如下:(不推荐使用)

推荐方法如下:
以不依赖索引的方式进行循环判断 (推荐)
方法一:
# 通过不依赖索引的方式,推荐使用此方法:
import os # 6、用来进行覆盖操作而要调用的模块
f1 = open('c.txt','r',encoding='utf-8') # 原文件
f2 = open('修改后的c.txt','w',encoding='utf-8') # 新文件
for line in f1: # 1、不依赖索引进行遍历,可以避免将文件所有的内容读到内存中,得到每行的内容
if '小白' in line: # 2、判断字符串“小白”是否在每一行内,如果在则替换成“大神”
line = line.replace('小白','大神') # 3、通过replace()方法进行替换操作
f2.write(line) # 4、将替换成“大神”的行都写入到新文件f2里
else:
f2.write(line) # 4 、如果字符串“小白”没有在每行里,则把这些行也写入新文件f2里
# 5、将以上修改好的内容就写入到“修改后的c.txt”这个文件里了
f1.close()
f2.close()
# 6、接下来则要进行覆盖操作,这里必须先导入os模块
os.remove('c.txt') # 7、通过os模块删除原文件c.txt
os.rename('修改后的c.txt','c.txt') # 8、通过os模块将文件'修改后的c.txt'改名为‘c.txt’
输出结果:
原来的c.txt文件被删除,“修改后的c.txt”文件被重命名为“c.txt”
查看修改后的c.txt文件中的内容:

方法二:将以上代码进行优化:
import os # 6、用来进行覆盖操作而要调用的模块
f1 = open('c.txt','r',encoding='utf-8') # 原文件
f2 = open('修改后的c.txt','w',encoding='utf-8') # 新文件
for line in f1: # 1、不依赖索引进行遍历,可以避免将文件所有的内容读到内存中,得到每行的内容
if '小白' in line: # 2、判断字符串“小白”是否在每一行内,如果在则替换成“大神”
line = line.replace('小白','大神') # 3、通过replace()方法进行替换操作
f2.write(line) # 4、如果字符串 “小白”在该行里 ,则修改为'大神'并把这修改好的line写到新文件f2里
# 4、如果字符串“小白”没有在每行里,则直接把line写到新文件f2里
# 5、将以上修改好的内容就写入到“修改后的c.txt”这个文件里了
f1.close()
f2.close()
# 6、接下来则要进行覆盖操作,这里必须先导入os模块
os.remove('c.txt') # 7、通过os模块删除原文件c.txt
os.rename('修改后的c.txt','c.txt') # 8、通过os模块将文件'修改后的c.txt'改名为‘c.txt’
方法三:将方法二代码进一步优化:语法糖
语法糖格式:
with open('文件名','模式',encoding='字符编码')as 文件变量名:
此方法可以省略f.close()操作,这样可以避免忘记加上f.close()而产生的代码错误问题。代码如下:
import os
with open('c.txt','r',encoding='utf-8') as f1,\
open('修改后的c.txt','w',encoding='utf-8') as f2: # 反斜杠的作用是语句太长,为了查看方便。
for line in f1:
if '小白' in line:
line = line.replace('小白','大神')
f2.write(line)
os.remove('c.txt')
os.rename('修改后的c.txt','c.txt')
8、文件的其它模式:r+、w+、a+ (基本不用)
(1)r+
读写:可读、可写
(2)w+
写读:可读,可写
(3)a+
写读:可读,可写
四、函数的定义与函数的调用
之前我们写的代码是按照流程写的,优点在于通俗易懂、方便、逻辑清晰,与计算机的处理流程相一致。缺点在于可读性差(代码乱)、代码冗余、功能可扩展性差
为了解决以上问题,我们则需要用到函数来解决问题。
1、函数的定义
什么是函数?
先举个生活中的小例子:例如,你是一位伐木工,要砍树则需要制造一把斧子。每砍完一棵树就造一把斧子,这是不现实的。实际上你只需要一把斧子即可完成所有的砍树工作,这把斧子就类似于python中要调用到的函数功能。
定义:函数即工具,事先准备工具的过程就是定义函数。把定义好的函数拿过来用,这就是调用函数。所以得出结论:pyhton的函数必须是先定义后调用。
调用函数只需要加上括号即可调用,语法如下:
函数名()
2、函数的分类
(1)内置函数:built-in
Python内置好的函数,如:len()、max()、min()、sum()等,此类函数的特点是不用自己定义,python解释器已经为我们定义好了。
(2)自定义函数:
语法:
def 函数名(参数1,参数2,......): # 括号内可以不加参数也可以加上参数,多个参数用逗号分隔。
# 补充:函数名必须是英文且具有可读性
'''注释''' # 用来描述该函数的功能
函数体 # 写函数实现的功能
函数名() # 调用函数
写一个简单的函数:
例:
def print_tag(): # 定义函数,函数名必须具有可读性
print("奔跑吧小白")
print_tag() # 调用函数,先找到函数名,再加上括号进行调用。
print_tag() # 函数可以多次调用
输出结果:
奔跑吧小白
奔跑吧小白
(3)小练习:
要求:
写一个函数功能实现以下打印效果:
**********************
**********************
**********************
hello,xiaobai!
**********************
**********************
**********************
def print_tag(tag): # 2、括号中的tag是形参,用来接收调用时传入进来的实参:“*”,此时tag = “*”
print(tag*20) # 字符串的拼接操作,将字符串“*”乘以20,得到20个“*”
def print_msg():
print('hello,xiaobai!')
print_tag("*") # 1、调用print_tag函数时传入参数:“*”
print_tag("*")
print_tag("*")
print_msg()
print_tag("*")
print_tag("*")
print_tag("*")
以上方法仍可以优化:我们可以指定“*”号的个数,将代码修改为:
def print_tag(tag,count): # 2、括号中的tag是形参,用来接收调用时传入进来的实参:“*”,此时tag = “*”
# 2、括号中的count是形参,用来接收调用时传入进来的实参:20,此时count = 20
print(tag*count) # 3、字符串的拼接操作,将字符串“*”乘以count,得到20个“*”
def print_msg():
print('hello,xiaobai!')
print_tag("*",20) # 1、调用print_tag函数时传入参数:“*”对应给第一个形参tag,20对应给第二个形参count
print_tag("*",20)
print_tag("*",20)
print_msg()
print_tag("*",20)
print_tag("*",20)
print_tag("*",20)
再将以上代码进行优化:(终极优化版)
def print_tag(tag,count,line_num): # 2、line_num用来打印多行“*”的,调用时传入3这个值给了line_num
for i in range(line_num): # 3、循环得到3行"*"
print(tag * count) # 4、将每行的“*”乘以调用时传入进来20,得到20个“*”每行。
def print_msg(msg):
print(msg)
print_tag('*',20,3) # 1、将这3个参数按位置分别传入至形参tag、count、line_num中。
print_msg('hello xiaobai')
print_tag('*',20,3)
3、函数的定义与调用细讲
函数的使用必须是先定义,后调用!
(1)定义函数
分为三种形式:
<1>定义无参函数
函数不依赖于外部传进来的参数就能被执行就叫无参函数。
例:
def print_tag(): # 括号内无参数
print('hello, xiaobai!')
<2>定义有参函数
必须依赖于外部的调用者传过来的参数,函数才能够被执行,这就叫有参函数。
例:
def print_tag(tag,count,line_num):
for i in range(line_num):
print(tag*count)
<3>定义空函数
只要函数体为pass,就叫空函数。作用:便于以后扩展,程序可读性强。
例:公司交待你写一个项目,项目里那些要实现的功能肯定不是一上线就开始写的,而是先要构思好一个项目的架构,这时就要用到空函数了,最后再一个个地去完善。
例:
def aut():
'''用户认证'''
pass
def get():
'''上传功能'''
pass
def put():
'''下载功能'''
pass
...
(2)调用函数
<1>无参函数的调用
定义时无参,调用时也必须无参。
例:
def print_tag(): # 定义时括号内没有形参
print('hello,xiaobai')
print_tag() # 直接用函数名加上括号即可调用 。括号内无需传入参数
<2>有参函数的调用
定义时有参,调用时也必须传入参数。定义了几个形参就要传几个参数,对号入座。
例:
def print_tag(tag,count,line_num): # 定义时就有3个形参,所以必须传入3个参数进来
for i in range(line_num):
print(tag * count)
def print_msg(msg):
print(msg)
print_tag('*',20,3) # 调用时就必须传入3个形参,多传、少传或者不传都会报错。
print_msg('hello xiaobai')
print_tag('*',20,3)
<3>函数的返回值
例:
def func():
print('from func')
func() # 执行函数句形式
res = func() # 执行函数的表达形式
print(res) # 此时的res没有返回值
输出结果:
None
如何让函数有返回值呢?
函数结束时加上一句return的返回值
例:
def func():
print('from func')
return xiaobai
return xiaoxiaobai
res = func() # 将返回值赋予变量res
print(res) # 此时打印res的值得到func函数的返回值——xiaobai,因为函数规定的只能执行一次return。整个函数就结束了,后面的代码不会被执行。
(3)小练习
练习一:
用函数写一个程序:比较两个值的最大值。
def max2(x,y):
if x > y:
return x
else:
return y
res = max2(20,2) # 这里就随机输入两个数字,让函数进行比较后得到函数的返回值,拿到的函数的返回值可以直接作加减乘除运算。
print(res)
输出结果:
20
补充:函数的调用可以被当作一个参数进行传递
练习二:
比较3个数的中的最大的值。
def max2(x,y):
if x > y:
return x
else:
return y
# 三个值分别为:17,100,33
# max2(17,33) # 先比较最小的两个数,得到其中的最大的数33
res = max2(max2(17,33),100) # 再把这个返回值当作第一个参数与100进行比较
print(res)
以上例子说明,函数的调用可以当作一个参数传进去。
思考:
什么情况下要用到函数的返回值?
答:函数执行后
如果要得到一个最终的结果。针对这种情况,一定要有一个返回值。
如果函数的代码只是一堆普通的操作(打印、用户交互处理等),则不需要返回值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号