
spark集群搭建
hadoop集群搭建参考:http://www.cnblogs.com/HeroBeast/p/4962730.html
前提条件:已经搭建好hadoop集群,在此基础上,有三台主机,并且主机之间设置了ssh免密码登陆,我的主机名字是:hadoop01,hadoop02,hadoop03
目标:
搭建一个master,两个slaver的集群
环境:
JAVA:1.7.0
SCALA:2.10.4:http://www.scala-lang.org/download/all.html
spark:1.3.1:http://spark.apache.org/downloads.html
直接下载编译之后的,然后下载对应的hadoop版本:http://archive.cloudera.com/cdh5/cdh/5/hadoop/
hadoop使用cdh更好

1,安装scala
配置scala环境
解压到/root/soft目录下
然后配置环境变量如下

刷新profile source /etc/profile
测试scala
进入scala的shell命令:

这样,scala的环境就配置好了
配置spark环境:
进入conf目录下修改三个文件名如下结构;
1,修改spark-env.sh
设置java_home路径
设置scala_home路径
加入:

再加入历史设置:
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://spark00:8020/user/cyhp/sparkhistory"
HADOOP_CONF_DIR=/root/------ 表示使用hdfs上的资源,如果需要使用本地资源,请把这一句注销
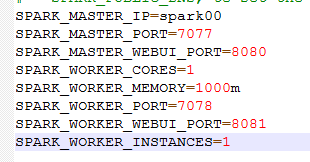
注:在设置Worker进程的CPU个数和内存大小,要注意机器的实际硬件条件,如果配置的超过当前Worker节点的硬件条件,Worker进程会启动失败。
解释:
| SPARK_MASTER_IP | 绑定一个外部IP给master. |
| SPARK_MASTER_PORT | 从另外一个端口启动master(默认: 7077) |
| SPARK_MASTER_WEBUI_PORT | Master的web UI端口 (默认: 8080),这个端口太常用,建议换一个 |
| SPARK_WORKER_PORT | 启动Spark worker 的专用端口(默认:随机) |
| SPARK_WORKER_DIR | 伸缩空间和日志输入的目录路径(默认: SPARK_HOME/work); |
| SPARK_WORKER_CORES | 作业可用的CPU内核数量(默认: 所有可用的); |
| SPARK_WORKER_MEMORY | 作业可使用的内存容量,默认格式1000M或者 2G (默认: 所有RAM去掉给操作系统用的1 GB);注意:每个作业自己的内存空间由SPARK_MEM决定。 |
| SPARK_WORKER_WEBUI_PORT | worker 的web UI 启动端口(默认: 8081) |
| SPARK_WORKER_INSTANCES | 没太机器上运行worker数量 (默认: 1). 当你有一个非常强大的计算机的时候和需要多个Spark worker进程的时候你可以修改这个默认值大于1 . 如果你设置了这个值。要确保SPARK_WORKER_CORE 明确限制每一个r worker的核心数, 否则每个worker 将尝试使用所有的核心 |
| SPARK_DAEMON_MEMORY | 分配给Spark master和 worker 守护进程的内存空间 (默认: 512m) |
| SPARK_DAEMON_JAVA_OPTS | Spark master 和 worker守护进程的JVM 选项(默认: none) |
2,修改slaves

3,修改spark-defalts.con

spark.master spark://spark00:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://spark00:8020/user/cyhp/sparkhistory
spark.eventLog.compress true
依次将scala的安装包,spark,拷贝到haoop02,03
scp -r scala-2.10.4/ hadoop02:/root/soft/
scp -r spark-1.3.0/ hadoop02:/root/soft/
scp -r /etc/profile hadoop02:/etc/
至此,spark集群环境已经搭建好了
---------------------------------------------------------
测试:
hadoop01上:
cd /root/soft/spark-1.3.1
sbin/start-master.sh 启动master
sbin/start-slaves.sh 启动worker
现在hadoop01上启动了一个master进程
hadoop02,hadoop03启动了一个worker进程
打开浏览器:

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
说明spark集群没有问题,现在来测试Wordcount例子
写一份wc.input文件上传到hdfs中:
位置: hdfs://hadoop01:8020/user/hadoop/data/wc.input
打开spark的shell客户端:
cd /root/soft/spark-1.3.1/bin
./spark-shell
scala> val rdd=sc.textFile("hdfs://hadoop01:8020/user/hadoop/data/wc.input")
scala> rdd.cache()
scala> val wordcount=rdd.flatMap(_.split(" ")).map(x=>(x,1)).reduceByKey(_+_)
scala> wordcount.take(10)
scala> val wordsort=wordcount.map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
scala> wordsort.take(10)
再来用官方给的代码测试:
package com.cloudyhadoop.spark.appimport org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.SparkConfobject SimpleApp{def main(args:Array[String]){val logFile ="hdfs://hadoop01:8020/user/cyhp/spark/wc.input"// Should be some file on your systemval conf =newSparkConf()//.setAppName("Simple Application").setMaster("spark://spark00:7077")//集群模式// .setMaster("local") // 本地模式val sc =newSparkContext(conf)val logData = sc.textFile(logFile,2).cache()val numAs = logData.filter(line => line.contains("a")).count()val numBs = logData.filter(line => line.contains("b")).count()println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))sc.stop()}}
打包方式:
在IDEA中打包生成jar,
进入spark主目录,执行命令:bin/spark-submit --jars /jar包位置
具体的idea使用方式,打jar包,参考:http://www.cnblogs.com/xiaoxiao5ya/p/b20abaa9640c55a9e9ec9b2109887f2a.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号