python爬虫从入门到入狱
python爬虫从入门到入狱
备注:在本笔记之前需要掌握python基础,以及html页面基础知识
一.urllib
什么是爬虫:
解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息
解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息
爬虫的核心:
1.爬取网页:爬取整个网页 包含了网页中所有得内容
2.解析数据:将网页中你得到的数据 进行解析
3.难点:爬虫和反爬虫之间的博弈
爬虫用途:
数据分析/人工数据集
社交软件冷启动
舆情监控
竞争对手监控

爬虫分类:
通用爬虫:
搜索引擎等,抓取的数据大部分是无用的。
聚焦爬虫:
功能 :
根据需求,实现爬虫程序,抓取需要的数据
设计思路 :
1.确定要爬取的url 如何获取Url
2.模拟浏览器通过http协议访问url,获取服务器返回的html代码 如何访问
3.解析html字符串(根据一定规则提取需要的数据)
如何解析
反爬手段:
1.User‐Agent:
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版 本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
2.代理IP
西次代理
快代理
什么是高匿名、匿名和透明代理?它们有什么区别?
1.使用透明代理,对方服务器可以知道你使用了代理,并且也知道你的真实IP。
2.使用匿名代理,对方服务器可以知道你使用了代理,但不知道你的真实IP。
3.使用高匿名代理,对方服务器不知道你使用了代理,更不知道你的真实IP。
3.验证码访问 打码平台 云打码平台 超级🦅
4.动态加载网页
网站返回的是js数据 并不是网页的真实数据
selenium驱动真实的浏览器发送请求
5.数据加密
分析js代码
urllib库使用:
基本使用:
# _*_ coding :utf-8 _*_
# @time : 2021/9/24 21:35
# @Author :xiaowei
# @File : urllib_test
# @Project : python code
# 1.定义一个url 即访问的地址
import urllib.request
url = 'http://www.baidu.com'
# 2、模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 3.response中的数据很多,不仅有源码,还有状态码。响应头等,仅获取源码
content = response.read()
content2 =response.read().decode('utf-8')
# 4.打印数据
# 返回的数据以b开头 即read方法返回的是字节形式的二进制数据
# 将二进制转化为字符串 解码 decode(‘编码的格式’)
print(content2)


一个类型和六个方法:
import urllib.request
url = 'http://www.baidu.com'
#一个类型和六个方法
# response是HTTPResponse的类型
response = urllib.request.urlopen(url)
# 按照一个字节一个字节去读
content = response.read()
#返回多少个字节
content = response.read(5)
#只能读取一行
content = response.readline()
#一行一行读,直到读完
content = response.readlines()
print(content)
# 返回状态码
print(response.getcode())
# 返回url地址
print(response.geturl())
# 获取响应头
print(response.getheaders())
下载:
import urllib.request
#下载网页
url = 'http://www.baidu.com'
# # url代表下载路径 filename代表下载文件的名字
# # python既可以写变量的名字也可以直接写值
urllib.request.urlretrieve(url,'baidu.html')
#下载图片
url = 'https://tse2-mm.cn.bing.net/th/id/OIP-C.vbUeOACHqn70ux2ZmdjO1QHaEo?w=300&h=187&c=7&r=0&o=5&pid=1.7'
urllib.request.urlretrieve(url,'xiong.jpg')
#下载视频
url = 'https://apd-2be3cb5fa1eba3ace9ba8652f9e8663b.v.smtcdns.com/om.tc.qq.com/AtmKvikJLZXTJvMYsApPXVA7_x2-b9dPtw6CrB835ZVA/uwMROfz2r5zEIaQXGdGnC2dfJ6rBbB0u18Msl1j33cNgltoG/r0180343hpq.p702.1.mp4?sdtfrom=v1010&guid=08b493d1a71090ad818922900ca4684d&vkey=9D04EE38C5A8D2D7DE8A46AC8241779B7DDEAD4794E93DBFE77BDFB1DDF00C4C0D93495CE853833759180A6B1C6D473905FF6CF0B8593A9751E4728A97A64D8217CE91FDD2E60FA40D42B06DAE2DC6FA3BC82E7BE9A03534F49BBE248E57688699EDF5ACB605CF6084963B0219DEB068CCD93C39FB977AECE930F948FB59F296FD77F76FBE663C7B'
urllib.request.urlretrieve(url,'xiong.mp4')

注意:如何获取需要下载的视频的地址
F12进入工程模式,点击这个标签,选择页面上的元素
查看video标签里的src地址,即为所需下载的视频地址
请求对象定制:解决反爬的第一种手段
UA介绍:User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统 及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等
如何获取UA:1.直接百度搜索 2.F12工程模式查看 network request Handler 里有一个 UA
import urllib.request
url = 'https://www.baidu.com'
# url的组成
# http/https www.baidu.com 80/443 s wd=周杰伦 #
# 协议 主机 端口号 路径 参数 锚点
# http: 80
# https: 443
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 因为urlopen方法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
# 注意 因为参数传递顺序的问题 不能直接写url 和写 headers,因为其有多个参数 所以需要关键字传参
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)
get请求的quote方法:将中文转变为Unicode
我们在百度搜索 周杰伦 得到 地址 https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6 wd=后面的周杰伦变为乱码,即转码为Unicode 因为直接使用中文的情况会出错
# 需求 获取 https://www.baidu.com/s?wd=周杰伦的网页源码
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象的定制为了解决反爬的第一种手段
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 将周杰伦三个字变成unicode编码的格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
# 打印数据
print(content)
编码集的演变‐‐‐ 由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号, 这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突, 所以,中国制定了GB2312编码,用来把中文编进去。 你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc‐kr里, 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。 因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。 Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。
现代操作系统和大多数编程语言都直接支持Unicode。
上述方法对于一个关键词比较方便,但并不适用于多个关键词
urlencode():
# urlencode应用场景:多个参数的时候
# https://www.baidu.com/s?wd=周杰伦&sex=男
# import urllib.parse
#
# data = {
# 'wd':'周杰伦',
# 'sex':'男',
# 'location':'中国台湾省'
# }
#
# a = urllib.parse.urlencode(data)
# print(a)
#获取https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6&sex=%E7%94%B7的网页源码
import urllib.request
import urllib.parse
base_url = 'https://www.baidu.com/s?'
data = {
'wd':'周杰伦',
'sex':'男',
'location':'中国台湾省'
}
new_data = urllib.parse.urlencode(data)
# 请求资源路径
url = base_url + new_data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码的数据
content = response.read().decode('utf-8')
# 打印数据
print(content)
post请求百度翻译:
首先找百度翻译的接口:
我们在F12工程模式下,查看network加载的资源
似乎找到了一些线索,继续查找,我们发现
在preview中我们看到了所有可能的释义

所以它的Request URL: https://fanyi.baidu.com/sug应该就是我们要的接口
# post请求
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'kw':'spider'
}
# post请求的参数 必须要进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
# post的请求的参数 是不会拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数 必须要进行编码
request = urllib.request.Request(url=url,data=data,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 字符串--》json对象
import json
obj = json.loads(content)
print(obj)
# post请求方式的参数 必须编码 data = urllib.parse.urlencode(data)
# 编码之后 必须调用encode方法 data = urllib.parse.urlencode(data).encode('utf-8')
# 参数是放在请求对象定制的方法中 request = urllib.request.Request(url=url,data=data,headers=headers)
post请求百度翻译之详细翻译:
同样是在F12下,我们可以看到有如下,它的信息比之前的更多,这就是详细翻译
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
# 'Accept': '*/*',
# 'Accept-Encoding': 'gzip, deflate, br',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Connection': 'keep-alive',
# 'Content-Length': '135',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BIDUPSID=DAA8F9F0BD801A2929D96D69CF7EBF50; PSTM=1597202227; BAIDUID=DAA8F9F0BD801A29B2813502000BF8E9:SL=0:NR=10:FG=1; __yjs_duid=1_c19765bd685fa6fa12c2853fc392f8db1618999058029; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=R2bEZvTjFCNHQxdUV-cTZ-MzZrSGxhbUYwSkRkUWk2SkxxS3E2M2lqaFRLUlJoRVFBQUFBJCQAAAAAAAAAAAEAAAA3e~BTveK-9sHLZGF5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFOc7GBTnOxgaW; BDUSS_BFESS=R2bEZvTjFCNHQxdUV-cTZ-MzZrSGxhbUYwSkRkUWk2SkxxS3E2M2lqaFRLUlJoRVFBQUFBJCQAAAAAAAAAAAEAAAA3e~BTveK-9sHLZGF5AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFOc7GBTnOxgaW; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=DAA8F9F0BD801A29B2813502000BF8E9:SL=0:NR=10:FG=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=2; H_PS_PSSID=34435_31660_34405_34004_34073_34092_26350_34426_34323_22158_34390; delPer=1; BA_HECTOR=8185a12020018421b61gi6ka20q; BCLID=10943521300863382545; BDSFRCVID=boDOJexroG0YyvRHKn7hh7zlD_weG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0mOTHv8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF=tR3aQ5rtKRTffjrnhPF3-44vXP6-hnjy3bRkX4Q4Wpv_Mnndjn6SQh4Wbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD-ug3-7qqU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqC8hMIt43f; BCLID_BFESS=10943521300863382545; BDSFRCVID_BFESS=boDOJexroG0YyvRHKn7hh7zlD_weG7bTDYLEOwXPsp3LGJLVJeC6EG0Pts1-dEu-EHtdogKK0mOTHv8F_2uxOjjg8UtVJeC6EG0Ptf8g0M5; H_BDCLCKID_SF_BFESS=tR3aQ5rtKRTffjrnhPF3-44vXP6-hnjy3bRkX4Q4Wpv_Mnndjn6SQh4Wbttf5q3RymJ42-39LPO2hpRjyxv4y4Ldj4oxJpOJ-bCL0p5aHl51fbbvbURvD-ug3-7qqU5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIE3-oJqC8hMIt43f; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1629701482,1629702031,1629702343,1629704515; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1629704515; __yjs_st=2_MDBkZDdkNzg4YzYyZGU2NTM5NzBjZmQ0OTZiMWRmZGUxM2QwYzkwZTc2NTZmMmIxNDJkYzk4NzU1ZDUzN2U3Yjc4ZTJmYjE1YTUzMTljYWFkMWUwYmVmZGEzNmZjN2FlY2M3NDAzOThhZTY5NzI0MjVkMmQ0NWU3MWE1YTJmNGE5NDBhYjVlOWY3MTFiMWNjYTVhYWI0YThlMDVjODBkNWU2NjMwMzY2MjFhZDNkMzVhNGMzMGZkMWY2NjU5YzkxMDk3NTEzODJiZWUyMjEyYTk5YzY4ODUyYzNjZTJjMGM5MzhhMWE5YjU3NTM3NWZiOWQxNmU3MDVkODExYzFjN183XzliY2RhYjgz; ab_sr=1.0.1_ZTc2ZDFkMTU5ZTM0ZTM4MWVlNDU2MGEzYTM4MzZiY2I2MDIxNzY1Nzc1OWZjZGNiZWRhYjU5ZjYwZmNjMTE2ZjIzNmQxMTdiMzIzYTgzZjVjMTY0ZjM1YjMwZTdjMjhiNDRmN2QzMjMwNWRhZmUxYTJjZjZhNTViMGM2ODFlYjE5YTlmMWRjZDAwZGFmMDY4ZTFlNGJiZjU5YzE1MGIxN2FiYTU3NDgzZmI4MDdhMDM5NTQ0MjQxNDBiNzdhMDdl',
# 'Host': 'fanyi.baidu.com',
# 'Origin': 'https://fanyi.baidu.com',
# 'Referer': 'https://fanyi.baidu.com/?aldtype=16047',
# 'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
# 'sec-ch-ua-mobile': '?0',
# 'Sec-Fetch-Dest': 'empty',
# 'Sec-Fetch-Mode': 'cors',
# 'Sec-Fetch-Site': 'same-origin',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest',
}
data = {
'from': 'en',
'to': 'zh',
'query': 'love',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '198772.518981',
'token': '5483bfa652979b41f9c90d91f3de875d',
'domain': 'common',
}
# post请求的参数 必须进行编码 并且要调用encode方法
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象的定制
request = urllib.request.Request(url = url,data = data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
import json
obj = json.loads(content)
print(obj)
相比前面的简易版翻译,这个详细版的request data变多了,同时增加了反爬虫需要的headers也变化了(每个网站都不同)
ajax的get请求:以豆瓣电影第一页为实例
打开豆瓣电影,F12进入工程模式,在network查看与我们需要的数据有关的内容
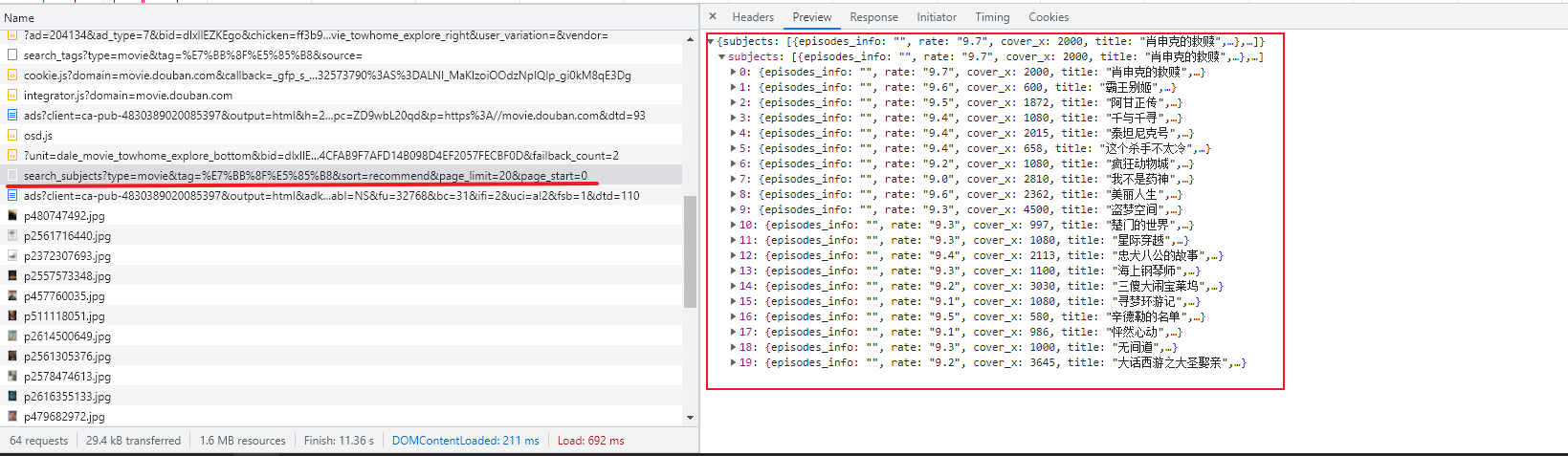
备注:json数据为前后端分离项目传送数据
# get请求
# 获取豆瓣电影的第一页的数据 并且保存起来
import urllib.request
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%BB%8F%E5%85%B8&sort=recommend&page_limit=20&page_start=0'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# (1) 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# (2)获取响应的数据
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# (3) 数据下载到本地
# open方法默认情况下使用的是gbk的编码 如果我们要想保存汉字 那么需要在open方法中指定编码格式为utf-8
# encoding = 'utf-8'
fp = open('douban.json','w',encoding='utf-8')
fp.write(content)
# with open('douban1.json','w',encoding='utf-8') as fp:
# fp.write(content)
ajax的get请求豆瓣电影前十页:
我们通过馆长豆瓣电影网站我们得知每次加载时只会加载20条数据,随着滑动的动作,会继续加载新的数据,分析每一次新加载的数据的规律
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=0&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=20&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=40&limit=20
# https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&
# start=60&limit=20
# page 1 2 3 4
# start 0 20 40 60
# start (page - 1)*20
# 下载豆瓣电影前10页的数据
# (1) 请求对象的定制
# (2) 获取响应的数据
# (3) 下载数据
import urllib.parse
import urllib.request
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start':(page - 1) * 20,
'limit':20
}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
#注意 这里的open方法里面的参数是字符串 一定记得将 page强制转换一下
def down_load(page,content):
with open('douban_' + str(page) + '.json','w',encoding='utf-8')as fp:
fp.write(content)
# 程序的入口
if __name__ == '__main__':
start_page = int(input('请输入起始的页码'))
end_page = int(input('请输入结束的页面'))
for page in range(start_page,end_page+1):
# 每一页都有自己的请求对象的定制
request = create_request(page)
# 获取响应的数据
content = get_content(request)
# 下载
down_load(page,content)
实践证明,将limit改为200即可一次获得200条数据
ajax的post请求肯德基官网:
# 1页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
# 2页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# post
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': '10'
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url=base_url,headers=headers,data=data)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(page,content):
with open('kfc_' + str(page) + '.json','w',encoding='utf-8')as fp:
fp.write(content)
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页源码
content = get_content(request)
# 下载
down_load(page,content)
异常:
URLError\HTTPError:
简介:
1.HTTPError类是URLError类的子类
2.导入的包urllib.error.HTTPError
urllib.error.URLError
3.http错误:http错误是针对浏览器无法连接到服务器而增加出来的错误提示。引导并告诉浏览者该页是哪里出
了问题。
4.通过urllib发送请求的时候,有可能会发送失败,这个时候如果想让你的代码更加的健壮,可以通过try‐
except进行捕获异常,异常有两类,URLError\HTTPError
import urllib.request
import urllib.error
# url = 'https://blog.csdn.net/sulixu/article/details/1198189491'
url = 'http://www.doudan1111.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
try:
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级。。。')
except urllib.error.URLError:
print('我都说了 系统正在升级。。。')
微博的cookie登陆:
# 适用的场景:数据采集的时候 需要绕过登陆 然后进入到某个页面
# 个人信息页面是utf-8 但是还报错了编码错误 因为并没有进入到个人信息页面 而是跳转到了登陆页面
# 那么登陆页面不是utf-8 所以报错
# 什么情况下访问不成功?
# 因为请求头的信息不够 所以访问不成功
import urllib.request
url = 'https://weibo.cn/6451491586/info'
headers = {
# ':authority': 'weibo.cn',
# ':method': 'GET',
# ':path': '/6451491586/info',
# ':scheme': 'https',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
# cookie中携带着你的登陆信息 如果有登陆之后的cookie 那么我们就可以携带着cookie进入到任何页面
'cookie': '_T_WM=24c44910ba98d188fced94ba0da5960e; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFxxfgNNUmXi4YiaYZKr_J_5NHD95QcSh-pSh.pSKncWs4DqcjiqgSXIgvVPcpD; SUB=_2A25MKKG_DeRhGeBK7lMV-S_JwzqIHXVv0s_3rDV6PUJbktCOLXL2kW1NR6e0UHkCGcyvxTYyKB2OV9aloJJ7mUNz; SSOLoginState=1630327279',
# referer 判断当前路径是不是由上一个路径进来的 一般情况下 是做图片防盗链
'referer': 'https://weibo.cn/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存到本地
with open('weibo.html','w',encoding='utf-8')as fp:
fp.write(content)
handler处理器基本使用:
为什么要学习handler?
urllib.request.urlopen(url) 不能定制请求头
urllib.request.Request(url,headers,data) 可以定制请求头
Handler 定制更高级的请求头(随着业务逻辑的复杂 请求对象的定制已经满足不了我们的需求(动态cookie和代理
不能使用请求对象的定制)
# 需求 使用handler来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
# handler build_opener open
# (1)获取hanlder对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3) 调用open方法
response = opener.open(request)
content = response.read().decode('utf-8')
print(content)
代理服务器:
1.代理的常用功能?
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源 扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务
器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3.提高访问速度 扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
4.隐藏真实IP 扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
2.代码配置代理 创建Reuqest对象 创建ProxyHandler对象 用handler对象创建opener对象
使用opener.open函数发送请求
import urllib.request
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers= headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
proxies = {
'http':'118.24.219.151:16817'
}
# handler build_opener open
handler = urllib.request.ProxyHandler(proxies = proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)
备注:代理IP可通过搜索快代理获取
代理池:
import urllib.request
proxies_pool = [
{'http':'118.24.219.151:16817'},
{'http':'118.24.219.151:16817'},
]
import random
proxies = random.choice(proxies_pool)
url = 'http://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
request = urllib.request.Request(url = url,headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)
xpath:
安装xpath:
xpath使用: 注意:提前安装xpath插件
(1)打开chrome浏览器
(2)点击右上角小圆点
(3)更多工具
(4)扩展程序
(5)拖拽xpath插件到扩展程序中
(6)如果crx文件失效,需要将后缀修改zip
(7)再次拖拽
(8)关闭浏览器重新打开
(9)ctrl + shift + x
(10)出现小黑框
xpath的基本使用:
1.安装lxml库 pip install lxml(注意:需要将cmd下的路径选为python安装目录下的scripts文件夹下)
2.导入lxml.etree from lxml import etree
3.etree.parse() 解析本地文件 html_tree = etree.parse('XX.html')
4.etree.HTML() 服务器响应文件 html_tree = etree.HTML(response.read().decode('utf‐8')
4.html_tree.xpath(xpath路径)
实际使用:
xpath基本语法:
1.路径查询 //:查找所有子孙节点,不考虑层级关系 / :找直接子节点
2.谓词查询 //div[@id] //div[@id="maincontent"]
3.属性查询 //@class
4.模糊查询 //div[contains(@id, "he")] //div[starts‐with(@id, "he")]
5.内容查询 //div/h1/text()
6.逻辑运算 //div[@id="head" and @class="s_down"]
//title | //price
注意本地文件创建一个同名的html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
<!-- <ul>-->
<!-- <li>大连</li>-->
<!-- <li>锦州</li>-->
<!-- <li>沈阳</li>-->
<!-- </ul>-->
</body>
</html>
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('070_尚硅谷_爬虫_解析_xpath的基本使用.html')
#tree.xpath('xpath路径')
# 查找ul下面的li
# li_list = tree.xpath('//body/ul/li')
# 查找所有有id的属性的li标签
# text()获取标签中的内容
# li_list = tree.xpath('//ul/li[@id]/text()')
# 找到id为l1的li标签 注意引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 查找到id为l1的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')
# 查询id中包含l的li标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查询id的值以l开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
#查询id为l1和class为c1的
# li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
# 判断列表的长度
print(li_list)
print(len(li_list))
获取百度网站的百度一下:
# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers = headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath的返回值是一个列表类型的数据
#我们可以通过在浏览器中的小黑框中输入对应的xpath表达式查询对应的结果判断表达式是否正确
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
解析站长素材网站:
# (1) 请求对象的定制
# (2)获取网页的源码
# (3)下载
# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url = url, headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
# 这里需要注意获取到的src没有协议,需要手动加上
url = 'https:' + src
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)
jsonpath:
jsonpath的安装及使用方式: pip安装: pip install jsonpath
jsonpath的使用: obj = json.load(open('json文件', 'r', encoding='utf‐8'))
ret = jsonpath.jsonpath(obj, 'jsonpath语法')
json数据:
{ "store": {
"book": [
{ "category": "修真",
"author": "六道",
"title": "坏蛋是怎样练成的",
"price": 8.95
},
{ "category": "修真",
"author": "天蚕土豆",
"title": "斗破苍穹",
"price": 12.99
},
{ "category": "修真",
"author": "唐家三少",
"title": "斗罗大陆",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "修真",
"author": "南派三叔",
"title": "星辰变",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author": "老马",
"color": "黑色",
"price": 19.95
}
}
}
代码:
import json
import jsonpath
obj = json.load(open('test.json','r',encoding='utf-8'))
# 书店所有书的作者
# author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')
# print(author_list)
# 所有的作者
# author_list = jsonpath.jsonpath(obj,'$..author')
# print(author_list)
# store下面的所有的元素
# tag_list = jsonpath.jsonpath(obj,'$.store.*')
# print(tag_list)
# store里面所有东西的price
# price_list = jsonpath.jsonpath(obj,'$.store..price')
# print(price_list)
# 第三个书
# book = jsonpath.jsonpath(obj,'$..book[2]')
# print(book)
# 最后一本书
# book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
# print(book)
# 前面的两本书
# book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# print(book_list)
# 条件过滤需要在()的前面添加一个?
# 过滤出所有的包含isbn的书。
# book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
# print(book_list)
# 哪本书超过了10块钱
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
print(book_list)
jsonpath解析淘票票:
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
#结论:以冒号开头的属性都不可用
headers = {
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
#报编码错误有可能是这里的问题
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'cna=UkO6F8VULRwCAXTqq7dbS5A8; miid=949542021157939863; sgcookie=E100F01JK9XMmyoZRigjfmZKExNdRHQqPf4v9NIWIC1nnpnxyNgROLshAf0gz7lGnkKvwCnu1umyfirMSAWtubqc4g%3D%3D; tracknick=action_li; _cc_=UIHiLt3xSw%3D%3D; enc=dA18hg7jG1xapfVGPHoQCAkPQ4as1%2FEUqsG4M6AcAjHFFUM54HWpBv4AAm0MbQgqO%2BiZ5qkUeLIxljrHkOW%2BtQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=3ca69de1b9ad7dce614840fcd015dcdb_1629776735568; _m_h5_tk_enc=ab56df54999d1d2cac2f82753ae29f82; t=874e6ce33295bf6b95cfcfaff0af0db6; xlly_s=1; cookie2=13acd8f4dafac4f7bd2177d6710d60fe; v=0; _tb_token_=e65ebbe536158; tfstk=cGhRB7mNpnxkDmUx7YpDAMNM2gTGZbWLxUZN9U4ulewe025didli6j5AFPI8MEC..; l=eBrgmF1cOsMXqSxaBO5aFurza77tzIRb8sPzaNbMiInca6OdtFt_rNCK2Ns9SdtjgtfFBetPVKlOcRCEF3apbgiMW_N-1NKDSxJ6-; isg=BBoas2yXLzHdGp3pCh7XVmpja8A8S54lyLj1RySTHq14l7vRDNufNAjpZ2MLRxa9',
'referer': 'https://dianying.taobao.com/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# split 切割
content = content.split('(')[1].split(')')[0]
with open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','w',encoding='utf-8')as fp:
fp.write(content)
import json
import jsonpath
obj = json.load(open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','r',encoding='utf-8'))
city_list = jsonpath.jsonpath(obj,'$..regionName')
print(city_list)
BeautifulSoup:
基本介绍:
1.BeautifulSoup简称: bs4
2.什么是BeatifulSoup? BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点? 缺点:效率没有lxml的效率高
优点:接口设计人性化,使用方便
安装以及创建:
1.安装 pip install bs4
2.导入 from bs4 import BeautifulSoup
3.创建对象 服务器响应的文件生成对象 soup = BeautifulSoup(response.read().decode(), 'lxml')
本地文件生成对象 soup = BeautifulSoup(open('1.html'), 'lxml')
注意:默认打开文件的编码格式gbk所以需要指定打开编码格式
本地html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<a href="" id="" class="a1">尚硅谷</a>
<span>嘿嘿嘿</span>
</ul>
</div>
<a href="" title="a2">百度</a>
<div id="d1">
<span>
哈哈哈
</span>
</div>
<p id="p1" class="p1">呵呵呵</p>
</body>
</html>
from bs4 import BeautifulSoup
# 通过解析本地文件 来将bs4的基础语法进行讲解
# 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
soup = BeautifulSoup(open('075_尚硅谷_爬虫_解析_bs4的基本使用.html',encoding='utf-8'),'lxml')
# 根据标签名查找节点
# 找到的是第一个符合条件的数据
# print(soup.a)
# 获取标签的属性和属性值
# print(soup.a.attrs)
# bs4的一些函数
# (1)find
# 返回的是第一个符合条件的数据
# print(soup.find('a'))
# 根据title的值来找到对应的标签对象
# print(soup.find('a',title="a2"))
# 根据class的值来找到对应的标签对象 注意的是class需要添加下划线
# print(soup.find('a',class_="a1"))
# (2)find_all 返回的是一个列表 并且返回了所有的a标签
# print(soup.find_all('a'))
# 如果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据
# print(soup.find_all(['a','span']))
# limit的作用是查找前几个数据
# print(soup.find_all('li',limit=2))
# (3)select(推荐)
# select方法返回的是一个列表 并且会返回多个数据
# print(soup.select('a'))
# 可以通过.代表class 我们把这种操作叫做类选择器
# print(soup.select('.a1'))
# print(soup.select('#l1'))
# 属性选择器---通过属性来寻找对应的标签
# 查找到li标签中有id的标签
# print(soup.select('li[id]'))
# 查找到li标签中id为l2的标签
# print(soup.select('li[id="l2"]'))
# 层级选择器
# 后代选择器
# 找到的是div下面的li
# print(soup.select('div li'))
# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中 如果不加空格不会输出内容 但是在bs4中 不会报错 会显示内容
# print(soup.select('div > ul > li'))
# 找到a标签和li标签的所有的对象
# print(soup.select('a,li'))
# 节点信息
# 获取节点内容
# obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
# print(obj.string)
# print(obj.get_text())
# 节点的属性
# obj = soup.select('#p1')[0]
# name是标签的名字
# print(obj.name)
# 将属性值左右一个字典返回
# print(obj.attrs)
# 获取节点的属性
obj = soup.select('#p1')[0]
print(obj.attrs.get('class'))
print(obj.get('class'))
print(obj['class'])
bs4爬取星巴克数据:
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# //ul[@class="grid padded-3 product"]//strong/text()
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.get_text())
selenium:
什么是selenium?
(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动
真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。
为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
如何安装selenium?
(1)操作谷歌浏览器驱动下载地址 http://chromedriver.storage.googleapis.com/index.html
(2)谷歌驱动和谷歌浏览器版本之间的映射表 http://blog.csdn.net/huilan_same/article/details/51896672
(3)查看谷歌浏览器版本 谷歌浏览器右上角‐‐>帮助‐‐>关于
注:下载对应版本后将其解压,得到一个exe文件,将其放到项目根目录下
(4)pip install selenium
4.selenium的使用步骤?
(1)导入:from selenium import webdriver
(2)创建谷歌浏览器操作对象: path = 谷歌浏览器驱动文件路径 browser = webdriver.Chrome(path)
(3)访问网址
url = 要访问的网址
browser.get(url)
简单使用:
# (1)导入selenium
from selenium import webdriver
# (2) 创建浏览器操作对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# (3)访问网站
# url = 'https://www.baidu.com'
#
# browser.get(url)
url = 'https://www.jd.com/'
browser.get(url)
# page_source获取网页源码
content = browser.page_source
print(content)
selenium元素定位:
selenium的元素定位?
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先
要找到它们,WebDriver提供很多定位元素的方法 方法:
1.find_element_by_id eg:button = browser.find_element_by_id('su')
2.find_elements_by_name eg:name = browser.find_element_by_name('wd')
3.find_elements_by_xpath eg:xpath1 = browser.find_elements_by_xpath('//input[@id="su"]')
4.find_elements_by_tag_name eg:names = browser.find_elements_by_tag_name('input')
5.find_elements_by_css_selector eg:my_input = browser.find_elements_by_css_selector('#kw')[0]
6.find_elements_by_link_text eg:browser.find_element_by_link_text("新闻")
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据id来找到对象
# button = browser.find_element_by_id('su')
# print(button)
# 根据标签属性的属性值来获取对象的
# button = browser.find_element_by_name('wd')
# print(button)
# 根据xpath语句来获取对象
# button = browser.find_elements_by_xpath('//input[@id="su"]')
# print(button)
# 根据标签的名字来获取对象
# button = browser.find_elements_by_tag_name('input')
# print(button)
# 使用的bs4的语法来获取对象
# button = browser.find_elements_by_css_selector('#su')
# print(button)
# button = browser.find_element_by_link_text('直播')
# print(button)
获取标签文本:
from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
input = browser.find_element_by_id('su')
# 获取标签的属性
print(input.get_attribute('class'))
# 获取标签的名字
print(input.tag_name)
# 获取元素文本就是起始标签之间的元素
a = browser.find_element_by_link_text('新闻')
print(a.text)
交互:
点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动: js='document.documentElement.scrollTop=100000'
browser.execute_script(js) 执行js代码
获取网页代码:page_source
退出:browser.quit()
from selenium import webdriver
# 创建浏览器对象
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
# url
url = 'https://www.baidu.com'
browser.get(url)
import time
time.sleep(2)
# 获取文本框的对象
input = browser.find_element_by_id('kw')
# 在文本框中输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
button = browser.find_element_by_id('su')
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element_by_xpath('//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
browser.back()
time.sleep(2)
# 回去
browser.forward()
time.sleep(3)
# 退出
browser.quit()
Phantomjs:
1.什么是Phantomjs?
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
2.如何使用Phantomjs?
(1)获取PhantomJS.exe文件路径path
(2)browser = webdriver.PhantomJS(path) (3)browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot('baidu.png')
from selenium import webdriver
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)
url = 'https://www.baidu.com'
browser.get(url)
browser.save_screenshot('baidu.png')
import time
time.sleep(2)
input = browser.find_element_by_id('kw')
input.send_keys('昆凌')
time.sleep(3)
browser.save_screenshot('kunling.png')
Chrome-headless:
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下 使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。
1.系统要求: Chrome
Unix\Linux 系统需要 chrome >= 59 Windows 系统需要 chrome >= 60
Python3.6 Selenium3.4.*
ChromeDriver2.31
# from selenium import webdriver
# from selenium.webdriver.chrome.options import Options
#
# chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
#
# # path是你自己的chrome浏览器的文件路径
# path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
# chrome_options.binary_location = path
#
# browser = webdriver.Chrome(chrome_options=chrome_options)
#
#
# url = 'https://www.baidu.com'
#
# browser.get(url)
#
# browser.save_screenshot('baidu.png')
# 封装的handless
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# path是你自己的chrome浏览器的文件路径
path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
return browser
browser = share_browser()
url = 'https://www.baidu.com'
browser.get(url)
requests:
基本使用:
官方文档
http://cn.python‐requests.org/zh_CN/latest/
快速上手
http://cn.python‐requests.org/zh_CN/latest/user/quickstart.html
import requests
url = 'http://www.baidu.com'
response = requests.get(url=url)
# 一个类型和六个属性
# Response类型
# print(type(response))
# 设置响应的编码格式
# response.encoding = 'utf-8'
# 以字符串的形式来返回了网页的源码
# print(response.text)
# 返回一个url地址
# print(response.url)
# 返回的是二进制的数据
# print(response.content)
# 返回响应的状态码
# print(response.status_code)
# 返回的是响应头
print(response.headers)
get请求:
# urllib
# (1) 一个类型以及六个方法
# (2)get请求
# (3)post请求 百度翻译
# (4)ajax的get请求
# (5)ajax的post请求
# (6)cookie登陆 微博
# (7)代理
# requests
# (1)一个类型以及六个属性
# (2)get请求
# (3)post请求
# (4)代理
# (5)cookie 验证码
import requests
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'wd':'北京'
}
# url 请求资源路径
# params 参数
# kwargs 字典
response = requests.get(url=url,params=data,headers=headers)
content = response.text
print(content)
# 总结:
# (1)参数使用params传递
# (2)参数无需urlencode编码
# (3)不需要请求对象的定制
# (4)请求资源路径中的?可以加也可以不加
post请求:
import requests
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
data = {
'kw': 'eye'
}
# url 请求地址
# data 请求参数
# kwargs 字典
response = requests.post(url=url,data=data,headers=headers)
content =response.text
import json
obj = json.loads(content,encoding='utf-8')
print(obj)
# 总结:
# (1)post请求 是不需要编解码
# (2)post请求的参数是data
# (3)不需要请求对象的定制
代理:
import requests
url = 'http://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
data = {
'wd':'ip'
}
proxy = {
'http':'212.129.251.55:16816'
}
response = requests.get(url = url,params=data,headers = headers,proxies = proxy)
content = response.text
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)
cookies登录读诗词网:
# 通过登陆 然后进入到主页面
# 通过找登陆接口我们发现 登陆的时候需要的参数很多
# _VIEWSTATE: /m1O5dxmOo7f1qlmvtnyNyhhaUrWNVTs3TMKIsm1lvpIgs0WWWUCQHl5iMrvLlwnsqLUN6Wh1aNpitc4WnOt0So3k6UYdFyqCPI6jWSvC8yBA1Q39I7uuR4NjGo=
# __VIEWSTATEGENERATOR: C93BE1AE
# from: http://so.gushiwen.cn/user/collect.aspx
# email: 595165358@qq.com
# pwd: action
# code: PId7
# denglu: 登录
# 我们观察到_VIEWSTATE __VIEWSTATEGENERATOR code是一个可以变化的量
# 难点:(1)_VIEWSTATE __VIEWSTATEGENERATOR 一般情况看不到的数据 都是在页面的源码中
# 我们观察到这两个数据在页面的源码中 所以我们需要获取页面的源码 然后进行解析就可以获取了
# (2)验证码
import requests
# 这是登陆页面的url地址
url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 获取页面的源码
response = requests.get(url = url,headers = headers)
content = response.text
# 解析页面源码 然后获取_VIEWSTATE __VIEWSTATEGENERATOR
from bs4 import BeautifulSoup
soup = BeautifulSoup(content,'lxml')
# 获取_VIEWSTATE
viewstate = soup.select('#__VIEWSTATE')[0].attrs.get('value')
# 获取__VIEWSTATEGENERATOR
viewstategenerator = soup.select('#__VIEWSTATEGENERATOR')[0].attrs.get('value')
# 获取验证码图片
code = soup.select('#imgCode')[0].attrs.get('src')
code_url = 'https://so.gushiwen.cn' + code
# 有坑
# import urllib.request
# urllib.request.urlretrieve(url=code_url,filename='code.jpg')
# requests里面有一个方法 session() 通过session的返回值 就能使用请求变成一个对象
session = requests.session()
# 验证码的url的内容
response_code = session.get(code_url)
# 注意此时要使用二进制数据 因为我们要使用的是图片的下载
content_code = response_code.content
# wb的模式就是将二进制数据写入到文件
with open('code.jpg','wb')as fp:
fp.write(content_code)
# 获取了验证码的图片之后 下载到本地 然后观察验证码 观察之后 然后在控制台输入这个验证码 就可以将这个值给
# code的参数 就可以登陆
code_name = input('请输入你的验证码')
#如何获取登录接口 的呼入错误的登陆信息登录或者勾选preserve log(保留日志)
# 点击登陆
url_post = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
data_post = {
'__VIEWSTATE': viewstate,
'__VIEWSTATEGENERATOR': viewstategenerator,
'from': 'http://so.gushiwen.cn/user/collect.aspx',
'email': '595165358@qq.com',
'pwd': 'action',
'code': code_name,
'denglu': '登录',
}
response_post = session.post(url = url, headers = headers, data = data_post)
content_post = response_post.text
with open('gushiwen.html','w',encoding= ' utf-8')as fp:
fp.write(content_post)
# 难点
# (1) 隐藏域
# (2) 验证码
超级鹰打码平台的使用:
登录超级鹰打码平台,下载对应语言的支持

#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print(chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
scrapy:
(1)scrapy是什么?
Scrapy是一个为了爬取网站数据,提取结构性数据(数据存放在网页中相同的结构内)而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
(2)安装scrapy:
pip install scrapy
安装过程中出错:
如果安装有错误!!!! pip install Scrapy building 'twisted.test.raiser' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual‐cpp‐build‐tools
解决方案: http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载twisted对应版本的whl文件(如我的Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl),cp后面是 python版本,amd64代表64位,运行命令: pip install C:\Users\...\Twisted‐17.5.0‐cp36‐cp36m‐win_amd64.whl pip install Scrapy
如果再报错 python ‐m pip install ‐‐upgrade pip
如果再报错 win32 解决方法: pip install pypiwin32
再报错:使用anaconda 使用步骤: 打开anaconda 点击environments 点击not installed 输入scrapy apply
在pycharm中选择anaconda的环境
scrapy项目的创建以及运行:
基本使用:
1. 创建爬虫的项目 scrapy startproject 项目的名字
注意:项目的名字不允许使用数字开头 也不能包含中文
2. 创建爬虫文件
要在spiders文件夹中去创建爬虫文件
cd 项目的名字\项目的名字\spiders
cd scrapy_baidu_091\scrapy_baidu_091\spiders
创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取网页
eg:scrapy genspider baidu http://www.baidu.com
一般情况下不需要添加http协议 因为start_urls的值是根据allowed_domains
修改的 所以添加了http的话 那么start_urls就需要我们手动去修改了
3. 运行爬虫代码
scrapy crawl 爬虫的名字
eg:
scrapy crawl baidu
2.项目组成:
spiders __init__.py 自定义的爬虫文件.py
__init__.py items.py
middlewares.py pipelines.py
settings.py
‐‐‐》由我们自己创建,是实现爬虫核心功能的文件
‐‐‐》定义数据结构的地方,是一个继承自scrapy.Item的类 ‐‐‐》中间件 代理
‐‐‐》管道文件,里面只有一个类,用于处理下载数据的后续处理 默认是300优先级,值越小优先级越高(1‐1000)
‐‐‐》配置文件 比如:是否遵守robots协议,User‐Agent定义等
爬虫文件(baidu.py):
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫的名字 用于运行爬虫的时候 使用的值
name = 'baidu'
# 允许访问的域名
allowed_domains = ['http://www.baidu.com']
# 起始的url地址 指的是第一次要访问的域名
# start_urls 是在allowed_domains的前面添加一个http://
# 在 allowed_domains的后面添加一个/
start_urls = ['http://www.baidu.com/']
# 是执行了start_urls之后 执行的方法 方法中的response 就是返回的那个对象
# 相当于 response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('苍茫的天涯是我的爱')
因为反爬协议,我们会被禁止爬虫,需要修改setting.py
# Obey robots.txt rules
# 注释掉之后 那么就不遵守robots协议了 他是一个君子协议 一般情况下 我们不用遵守
# ROBOTSTXT_OBEY = True
58同城结构项目和基本方法:
参照上述步骤创建项目
import scrapy
class TcSpider(scrapy.Spider):
name = 'tc'
allowed_domains = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
start_urls = ['https://bj.58.com/sou/?key=%E5%89%8D%E7%AB%AF%E5%BC%80%E5%8F%91']
def parse(self, response):
# 字符串
# content = response.text
# 二进制数据
# content = response.body
# print('===========================')
# print(content)
span = response.xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
print('=======================')
print(span.extract())
1. scrapy项目的结构
项目名字
项目名字
spiders文件夹 (存储的是爬虫文件)
init
自定义的爬虫文件 核心功能文件 ****************
init
items 定义数据结构的地方 爬取的数据都包含哪些
middleware 中间件 代理
pipelines 管道 用来处理下载的数据
settings 配置文件 robots协议 ua定义等
2. response的属性和方法
response.text 获取的是响应的字符串
response.body 获取的是二进制数据
response.xpath 可以直接是xpath方法来解析response中的内容
response.extract() 提取seletor对象的data属性值
response.extract_first() 提取的seletor列表的第一个数据
scrapy架构组成:
(1)引擎
‐‐‐》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器
‐‐‐》从引擎处获取到请求对象后,请求数据
(3)spiders
‐‐‐》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及 分析某个网页(或者是有些网页)的地方。
(4)调度器
‐‐‐》有自己的调度规则,无需关注
(5)管道(Item pipeline) ‐‐‐》最终处理数据的管道,会预留接口供我们处理数据 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行 一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
1. 清理HTML数据 2. 验证爬取的数据(检查item包含某些字段) 3. 查重(并丢弃) 4. 将爬取结果保存到数据库中
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html']
# 注意如果你的请求的接口是html为结尾的 那么是不需要加/的
start_urls = ['https://car.autohome.com.cn/price/brand-15.html']
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name,price)
scrapy工作原理:

scrapy shell管理工具:
1.什么是scrapy shell?
Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。 其本意是用来测试提取
数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。 该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。 在编写您的spider时,该
终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
2.安装ipython 安装:pip install ipython 简介:如果您安装了 IPython ,Scrapy终端将使用 IPython (替代标准Python终端)。 IPython 终端与其他相
比更为强大,提供智能的自动补全,高亮输出,及其他特性。
3.应用:(1)scrapy shell www.baidu.com (2)scrapy shell http://www.baidu.com (3) scrapy shell "http://www.baidu.com" (4) scrapy shell "www.baidu.com"
语法:
(1)response对象: response.body response.text response.url response.status
(2)response的解析: response.xpath() (常用) 使用xpath路径查询特定元素,返回一个selector列表对象
response.css() 使用css_selector查询元素,返回一个selector列表对象 获取内容 :response.css('#su::text').extract_first() 获取属性 :response.css('#su::attr(“value”)').extract_first()
(3)selector对象(通过xpath方法调用返回的是seletor列表) extract()
提取selector对象的值 如果提取不到值 那么会报错 使用xpath请求到的对象是一个selector对象,需要进一步使用extract()方法拆
包,转换为unicode字符串 extract_first() 提取seletor列表中的第一个值 如果提取不到值 会返回一个空值 返回第一个解析到的值,如果列表为空,此种方法也不会报错,会返回一个空值
xpath() css()
注意:每一个selector对象可以再次的去使用xpath或者css方法
当当网爬取数据:
items.py 定义数据结构的地方 爬取的数据都包含哪些
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyDangdang095Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 通俗的说就是你要下载的数据都有什么
# 图片
src = scrapy.Field()
# 名字
name = scrapy.Field()
# 价格
price = scrapy.Field()
settings.py 将管道对应的配置打开
ITEM_PIPELINES = {
# 管道可以有很多个 那么管道是有优先级的 优先级的范围是1到1000 值越小优先级越高
'scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline': 300,
# DangDangDownloadPipeline
'scrapy_dangdang_095.pipelines.DangDangDownloadPipeline':301
}
pipelines.py 管道 用来处理下载的数据
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 如果想使用管道的话 那么就必须在settings中开启管道
class ScrapyDangdang095Pipeline:
# 在爬虫文件开始的之前就执行的一个方法
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item就是yield后面的book对象
def process_item(self, item, spider):
# 以下这种模式不推荐 因为每传递过来一个对象 那么就打开一次文件 对文件的操作过于频繁
# # (1) write方法必须要写一个字符串 而不能是其他的对象
# # (2) w模式 会每一个对象都打开一次文件 覆盖之前的内容
# with open('book.json','a',encoding='utf-8')as fp:
# fp.write(str(item))
self.fp.write(str(item))
return item
# 在爬虫文件执行完之后 执行的方法
def close_spider(self,spider):
self.fp.close()
dang.py
import scrapy
#下面这种导入可能会引起编译器错误,直接忽略即可
from scrapy_dangdang_095.items import ScrapyDangdang095Item
class DangSpider(scrapy.Spider):
name = 'dang'
# 如果是多页下载的话 那么必须要调整的是allowed_domains的范围 一般情况下只写域名
allowed_domains = ['category.dangdang.com']
#注意这里url结尾的/一定要去掉
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
# pipelines 下载数据
# items 定义数据结构的
# src = //ul[@id="component_59"]/li//img/@src
# alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# 所有的seletor的对象 都可以再次调用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 第一张图片和其他的图片的标签的属性是不一样的
# 第一张图片的src是可以使用的 其他的图片的地址是data-original
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdang095Item(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book
# 每一页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法
# 就可以了
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg4-cp01.01.02.00.00.00.html
if self.page < 100:
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# 怎么去调用parse方法
# scrapy.Request就是scrpay的get请求
# url就是请求地址
# callback是你要执行的那个函数 注意不需要加()
yield scrapy.Request(url=url,callback=self.parse)
当当多条管道下载:
在下载信息的同时下载图片
pipelines.py
import urllib.request
# 多条管道开启
# (1) 定义管道类
# (2) 在settings中开启管道
# 'scrapy_dangdang_095.pipelines.DangDangDownloadPipeline':301
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url = 'http:' + item.get('src')
filename = './books/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url = url, filename= filename)
return item
当当网多页下载:
dang.py
base_url = 'http://category.dangdang.com/pg'
page = 1
# 每一页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法
# 就可以了
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg4-cp01.01.02.00.00.00.html
if self.page < 100:
self.page = self.page + 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
# 怎么去调用parse方法
# scrapy.Request就是scrpay的get请求
# url就是请求地址
# callback是你要执行的那个函数 注意不需要加()
yield scrapy.Request(url=url,callback=self.parse)
电影天堂多页数据下载:
多页数据即为我们需要通过多个页面之间的跳转获取所需的一条数据
movie.py
import scrapy
from scrapy_movie_099.items import ScrapyMovie099Item
class MvSpider(scrapy.Spider):
name = 'mv'
allowed_domains = ['www.dytt8.net']
start_urls = ['https://www.dytt8.net/html/gndy/china/index.html']
def parse(self, response):
# 要第一个的名字 和 第二页的图片
a_list = response.xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a_list:
# 获取第一页的name 和 要点击的链接
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二页的地址是
url = 'https://www.dytt8.net' + href
# 对第二页的链接发起访问
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name})
def parse_second(self,response):
# 注意 如果拿不到数据的情况下 一定检查你的xpath语法是否正确
src = response.xpath('//div[@id="Zoom"]//img/@src').extract_first()
# 接受到请求的那个meta参数的值
name = response.meta['name']
movie = ScrapyMovie099Item(src=src,name=name)
yield movie
items.py 封装数据
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyMovie099Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
settings.py里开启管道:
ITEM_PIPELINES = {
'scrapy_movie_099.pipelines.ScrapyMovie099Pipeline': 300,
}
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ScrapyMovie099Pipeline:
def open_spider(self,spider):
self.fp = open('movie.json','w',encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()
链接提取器的使用:
1.安装MySQL
2.使用pymysql
1.pip install pymysql
2.pymysql.connect(host,port,user,password,db,charset)
3.conn.cursor()
4.cursor.execute()
3.CrawlSpider
1.继承自scrapy.Spider
2.独门秘笈 CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发
送请求 所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常
合适的
3.提取链接 链接提取器,在这里就可以写规则提取指定链接
scrapy.linkextractors.LinkExtractor( allow = (), deny = (),
allow_domains = (), deny_domains = (),
4.模拟使用
正则用法:links1 = LinkExtractor(allow=r'list_23_\d+\.html') xpath用法:links2 = LinkExtractor(restrict_xpaths=r'//div[@class="x"]') css用法:links3 = LinkExtractor(restrict_css='.x')
5.提取连接 link.extract_links(response)
6.注意事项 【注1】callback只能写函数名字符串, callback='parse_item' 【注2】在基本的spider中,如果重新发送请求,那里的callback写的是 callback=self.parse_item 【注‐ ‐稍后看】follow=true 是否跟进 就是按照提取连接规则进行提取
运行原理:

crawlspider读书网:
需求:读书网数据入库
步骤:
1.创建项目:scrapy startproject dushuproject
2.跳转到spiders路径 cd\dushuproject\dushuproject\spiders
3.创建爬虫类:scrapy genspider ‐t crawl read www.dushu.com
4.items
5.spiders
6.settings
7.pipelines 数据保存到本地
数据保存到mysql数据库
基本使用:
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyReadbook101Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_readbook_101.items import ScrapyReadbook101Item
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['https://www.dushu.com/book/1188_1.html']
#正则: allow follow=true 是否跟进 就是按照提取连接规则进行提取
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\d+.html'),
callback='parse_item',
follow=True),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
name = img.xpath('./@data-original').extract_first()
src = img.xpath('./@alt').extract_first()
book = ScrapyReadbook101Item(name=name,src=src)
yield book
settings 开启管道:
ITEM_PIPELINES = {
'scrapy_readbook_101.pipelines.ScrapyReadbook101Pipeline': 300
}
链接数据库:
settings.py 配置MySQL数据库的信息
# 参数中一个端口号 一个是字符集 都要注意
DB_HOST = '192.168.231.130'
# 端口号是一个整数
DB_PORT = 3306
DB_USER = 'root'
DB_PASSWROD = '1234'
DB_NAME = 'spider01'
# utf-8的杠不允许写
DB_CHARSET = 'utf8'
ITEM_PIPELINES = {
'scrapy_readbook_101.pipelines.ScrapyReadbook101Pipeline': 300,
# MysqlPipeline
'scrapy_readbook_101.pipelines.MysqlPipeline':301
}
pipelines.py 管道配置MySQL信息
# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql
class MysqlPipeline:
def open_spider(self,spider):
settings = get_project_settings()
self.host = settings['DB_HOST']
self.port =settings['DB_PORT']
self.user =settings['DB_USER']
self.password =settings['DB_PASSWROD']
self.name =settings['DB_NAME']
self.charset =settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'],item['src'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
return item
def close_spider(self,spider):
self.cursor.close()
self.conn.close()
日志信息以及日志级别:
(1)日志级别:
CRITICAL:严重错误
ERROR: 一般错误
WARNING: 警告
INFO: 一般信息
DEBUG: 调试信息
默认的日志等级是DEBUG 只要出现了DEBUG或者DEBUG以上等级的日志 那么这些日志将会打印
(2)settings.py文件设置:
默认的级别为DEBUG,会显示上面所有的信息
在配置文件中 settings.py
LOG_FILE : 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL : 设置日志显示的等级,就是显示哪些,不显示哪些
scrapy的post请求:
(1)重写start_requests方法: def start_requests(self)
(2) start_requests的返回值: scrapy.FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data) url: 要发送的post地址 headers:可以定制头信息 callback: 回调函数
formdata: post所携带的数据,这是一个字典
spider:
import scrapy
import json
class TestpostSpider(scrapy.Spider):
name = 'testpost'
allowed_domains = ['https://fanyi.baidu.com/sug']
# post请求 如果没有参数 那么这个请求将没有任何意义
# 所以start_urls 也没有用了
# parse方法也没有用了
# start_urls = ['https://fanyi.baidu.com/sug/']
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'final'
}
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)
def parse_second(self,response):
content = response.text
obj = json.loads(content,encoding='utf-8')
print(obj)
代理:
(1)到settings.py中,打开一个选项 DOWNLOADER_MIDDLEWARES = { 'postproject.middlewares.Proxy': 543,
}
(2)到middlewares.py中写代码 def process_request(self, request, spider): request.meta['proxy'] = 'https://113.68.202.10:9999'
return None

 浙公网安备 33010602011771号
浙公网安备 33010602011771号