Linux 命令学习(一)
Linux 命令学习之旅(热爱学习中,生活奔波~)
1.col 命令
用来过滤掉控制字符(控制字符:就是一些会改变终端状态(控制终端)的字符)
语法
col [-bfx][-l<缓冲区列数>]
-b 过滤掉所有的控制字符,包括 RLF 和 HRLF。
-f 滤除 RLF 字符,但允许将 HRLF 字符呈现出来。
-x 以多个空格字符来表示跳格字符。
-l <缓冲区列数> 预设的内存缓冲区有 128 列,您可以自行指定缓冲区的大小。
例子: man ls | col -b > ls_help
上面命令的作用是:查看 ls 命令操作的相关内容把相应控制字符过滤后,将剩余文件输出到 ls_help 文件中。
col 命令可以将文件中的相关控制字符过滤掉,这样查看的时候文件就不会在有控制字符。( col 还有相关参数,大家可以试试)
2. vim 或 vi 命令
用于写文件
有三种模式分别为:
(1)命令模式(Command mode)
(2)输入模式(Insert mode)
(3)底线命令模式(Last line mode)
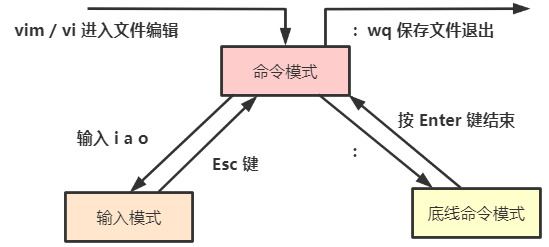
例子: vim a.txt 或 vi a.txt
用于向文件写入或修改相关内容(里面还有许多丰富的小命令哦!感兴趣的小伙伴可以用 man 查看下)。
3.emacs 命令
emacs 是一种代码编辑工具(需要下载安装)
基本命令:
C 代表 Ctrl 键
C-x C-c:用于退出 Emacs
C-x C-f:用于打开一个文件,如果文件不存在的话,会先创建一个文件
C-g:取消未完成的命令
语法
emacs (选项)(文件)
选项:
+<行号>:启动emacs编辑器,并将光标移动到制定行号的行; -q:启动emacs编辑器,而不加载初始化文件; -u<用户>:启动emacs编辑器时,加载指定用户的初始化文件; -t<文件>:启动emacs编辑器时,把指定的文件作为中端,不适用标准输入(stdin)与标准输出(stdout); -f<函数>:执行指定lisp(广泛应用于人工智能领域的编程语言)函数; -l<lisp代码文件>:加载指定的lisp代码文件; -batch:以批处理模式运行emacs编辑器。
例子: emacs -batch hellworld
4.colrm 命令
colrm命令用于滤掉指定的行。colrm指令从标准输入设备读取数据,转而输出到标准输出设备。如果不加任何参数,则该指令不会过滤任何一行。
colrm [ 开始行数编号 <结束行数编号> ]
参数说明:
开始行数编号: 指定要删除的列的起始编号。
结束行数编号: 指定要删除的列的结束编号,有时候这个参数可以省略。
例子: colrm 20 50 < /etc/fstab
注意:如果直接使用 colrm 命令不带参数时该命令不会删除任何列。
5.comm 命令
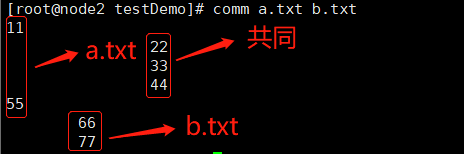
Linux comm 命令用于比较两个已排过序的文件。
这项指令会一列列地比较两个已排序文件的差异,并将其结果显示出来,如果没有指定任何参数,则会把结果分成 3 列显示:第 1 列仅是在第 1 个文件中出现过的列,第 2 列是仅在第 2 个文件中出现过的列,第 3 列则是在第 1 与第 2 个文件里都出现过的列。若给予的文件名称为 - ,则 comm 指令会从标准输入设备读取数据。
语法:
comm [-123] [--help] [--version] [第1个文件] [第2个文件]
参数:
- -1 不显示只在第 1 个文件里出现过的列。
- -2 不显示只在第 2 个文件里出现过的列。
- -3 不显示只在第 1 和第 2 个文件里出现过的列。
- --help 在线帮助。
- --version 显示版本信息。
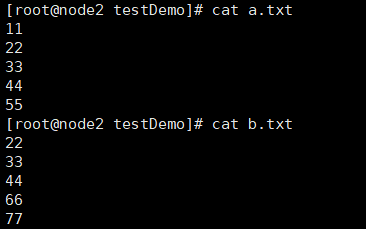
现在创建 a.txt 和 b.txt 进行如下操作:
6. csplit 命令
Linux csplit命令用于分割文件。
将文件依照指定的范本样式予以切割后,分别保存成名称为xx00,xx01,xx02...的文件。若给予的文件名称为"-",则 csplit 指令会从标准输入设备读取数据。
语法
csplit [-kqsz][-b<输出格式>][-f<输出字首字符串>][-n<输出文件名位数>][文件][范本样式...]
参数:
- -b<输出格式>或--suffix-format=<输出格式> 预设的输出格式其文件名称为xx00,xx01...等,您可以通过改变<输出格式>来改变输出的文件名。
- -f<输出字首字符串>或--prefix=<输出字首字符串> 预设的输出字首字符串其文件名为xx00,xx01...等,如果你指定输出字首字符串为"hello",则输出的文件名称会变成hello00,hello01...等。
- -k或--keep-files 保留文件,就算发生错误或中断执行,也不能删除已经输出保存的文件。
- -n<输出文件名位数>或--digits=<输出文件名位数> 预设的输出文件名位数其文件名称为xx00,xx01...等,如果你指定输出文件名位数为"3",则输出的文件名称会变成xx000,xx001...等。
- -q或-s或--quiet或--silent 不显示指令执行过程。
- -z或--elide-empty-files 删除长度为0 Byte文件。
- --help 在线帮助。
- --version 显示版本信息。
现在创建个文件 testfile
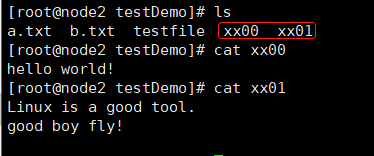
[root@node2 testDemo]# cat testfile hello world! Linux is a good tool. good boy fly!
[root@node2 testDemo]# csplit testfile 2 13 //第一个文件的字符数 37 //第二个文件的字符数
在testfile 的同目录下将生成两个文件,文件名分别为xx00、xx01,xx00 。
7.ed 命令
行文本编辑器,一次读取一行内容进行编辑。
ed 是Linux中功能最简单的文本编辑程序,一次仅能编辑一行而非全屏幕方式的操作。
ed 命令并不是一个常用的命令,但 ed 文本编辑器对于编辑大文件或对于在shell脚本程序中进行文本编辑很有用。
接下来我们操作下 ed 命令:
$ ed <- 激活 ed 命令 a <- 告诉 ed 我要编辑新文件 Hello world <- 输入第一行内容 I am good. <- 输入第二行内容 . <- 返回 ed 的命令行状态 i <- 告诉 ed 我要在最后一行之前插入内容 I am excellent. <- 将“I am excellent.”插入“Hello world.”和“I am good.”之间 . <- 返回 ed 的命令行状态 c <- 告诉 ed 我要替换最后一行输入内容 I am Lucifer. <- 将“I am good.”替换成“I am Lucifer.”(注意:这里替换的是最后输的内容) . <- 返回 ed 的命令行状态 w readme.text <- 将文件命名为“readme.text”并保存(注意:如果是编辑已经存在的文件,只需要敲入 w 即可) q <- 完全退出 ed 编辑器
我们来看下 testfile 里面的内容:
[root@node2 ~]# cat testfile Hello World.
I am excellent. I am Lucifer.
8.egrep 命令
可以使用 grep -E 来代替实现相同功能。
Linux egrep命令用于在文件内查找指定的字符串。
egrep执行效果与" grep -E "相似,使用的语法及参数可参照 grep 指令,与grep的不同点在于解读字符串的方法。
注意:egrep 是用extended regular expression语法来解读的,而grep则用basic regular expression 语法解读,extended regular expression 比 basic regular expression 的表达更规范。
用法:
egrep [范本模式][文件或目录]
参数说明:
- [范本模式] :查找的字符串规则。
- [文件或目录] :查找的目标文件或目录。
例子:
egrep java*
[root@node2 ~]# egrep Linux * testfile:Linux is good.
9.ex 命令
相当于 vi 的单行编辑
Linux ex 命令用于在 Ex 模式下启动vim文本编辑器。效果如同vi -E,使用语法及参数可参照vi指令。
参数说明:
-b:使用二进制模式编辑文件
-c 指令:编辑完第一个文件后执行指定的指令
-d :编辑多个文件时,显示差异部分
-m :不允许修改文件
-n :不使用缓存
-oN:其中 N 为数字
-r :列出缓存,并显示恢复信息
-R :以只读的方式打开文件
-s :不显示任何错误信息
-V :显示指令的详细执行过程
--help :显示帮助信息
--version :显示版本信息
例子:
ex testfile
10.fgrep 命令
在指定文件内查找指定的字符串,本指令相当于执行grep指令加上参数"-F",详见 grep 命令说明。
语法
fgrep [范本样式][文件或目录...]
11.fmt 命令
用于对文本进行格式化,Linux fmt命令用于编排文本文件。fmt指令会从指定的文件里读取内容,将其依照指定格式重新编排后,输出到标准输出设备。若指定的文件名为"-",则 fmt 指令会从标准输入设备读取数据。
语法
fmt [-cstu][-p<列起始字符串>][-w<每列字符数>][--help][--version][文件...]
参数说明:
- -c或--crown-margin 每段前两列缩排。
- -p<列起始字符串>或-prefix=<列起始字符串> 仅合并含有指定字符串的列,通常运用在程序语言的注解方面。
- -s或--split-only 只拆开字数超出每列字符数的列,但不合并字数不足每列字符数的列。
- -t或--tagged-paragraph 每列前两列缩排,但第1列和第2列的缩排格式不同。
- -u或--uniform-spacing 每个字符之间都以一个空格字符间隔,每个句子之间则两个空格字符分隔。
- -w<每列字符数>或--width=<每列字符数>或-<每列字符数> 设置每列的最大字符数。
- --help 在线帮助。
- --version 显示版本信息。
例子:
fmt testfile
[root@node2 ~]# fmt testfile Hello Word. I am Tom. Linux is good.
12.fold 命令
用于指定文件的每行输出内容大小, fold命令用于限制文件列宽。fold 指令会从指定的文件里读取内容,将超过限定列宽的列加入增列字符后,输出到标准输出设备。
语法
fold [-bs][-w<每列行数>][--help][--version][文件...]
参数:
- -b或--bytes 以Byte为单位计算列宽,而非采用行数编号为单位。
- -s或--spaces 以空格字符作为换列点。
- -w<每列行数>或--width<每列行数> 设置每列的最大行数。
- --help 在线帮助。
- --version 显示版本信息。
将一个名为 testfile 的文件的行折叠成宽度为 20,可使用如下命令:
fold -w 20 testfile
一开始的 testfile 文件内容情况:
[root@node2 ~]# cat testfile Linux networks are becoming more and more common, but security is often an overlooked issue. Unfortunately,
in today’s environment all networks are potential hacker targets.
使用 fold 之后 testfile 内容情况:
[root@node2 ~]# fold -w 20 testfile Linux networks are b ecoming more and mor e common, but securi
ty is often an overl
ooked issue. Unfortu
nately, in today’s e
nvironment all netwo
rks are potential ha
cker targets.
13.grep 命令
Linux grep 命令用于查找文件里符合条件的字符串,用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来。若不指定任何文件名称,或是所给予的文件名为 -,则 grep 指令会从标准输入设备读取数据。
语法
grep [-abcEFGhHilLnqrsvVwxy][-A<显示列数>][-B<显示列数>][-C<显示列数>][-d<进行动作>][-e<范本样式>][-f<范本文件>][--help][范本样式][文件或目录...]
参数:
- -a 或 --text : 不要忽略二进制的数据。
- -A<显示行数> 或 --after-context=<显示行数> : 除了显示符合范本样式的那一列之外,并显示该行之后的内容。
- -c 或 --count : 计算符合样式的列数。
- -y : 此参数的效果和指定"-i"参数相同。
例子:
1.在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test *file
[root@node2 ~]# grep test *file they are necessary. test test test test.
2.反向查找。前面各个例子是查找并打印出符合条件的行,通过 "-v" 参数可以打印出不符合条件行的内容。
查找文件名中包含 test 的文件中不包含 test 的行,此时,使用的命令为:
grep -v test *test*
[root@node2 ~]# grep -v test *file Linux networks are becoming more and more common, but security is often an overlooked issue. Unfortunately, in today’s environment all networks are potential hacker targets,from top-secret military research networks to small home LANs.Linux Network Security focuses on securing Linux in a networked environment, where the security of the entire network needs to be considered rather than just isolated machines.It uses a mix of theory and practical techniques to teach administrators how to install and use security applications, as well as how the applications work and why
例子:从当前目录开始查找所有扩展名为 .txt 的文本文件,并找出包含 "test" 的行:
find .-name "*.txt"| xargs grep "test"
从根目录开始查找所有扩展名为 .log 的文本文件,并找出包含 "ERROR" 的行:
$ find /-type f -name "*.log"| xargs grep "ERROR"
14.ispell 命令
拼写检查程序,英文拼写错误,给出英文矫正指令。若在检查的文件中找到字典没有的词汇,ispell会建议使用的词汇,或是让你将新的词汇加入个人字典。
语法
ispell [-aAbBClmMnNPStVx][-d<字典文件>][-L<行数>][-p<字典文件>][-w<非字母字符>][-W<字符串长度>][要检查的文件]
检查文件的拼写。例如,检查 testfile 文件,可使用如下命令:
ispell testfile
15.jed 命令
文本编辑器,编辑程序的源代码(可模拟 emacs ), jed 命令用于编辑文本文件。Jed是以Slang所写成的程序,适合用来编辑程序原始代码。
语法
jed [-2n][-batch][-f<函数>][-g<行数>][-i<文件>][-I<文件>][-s<字符串>][文件]
实例
jed主要用于编辑程序的源码,编辑源码时将以彩色高亮的方式显示程序的语法。例如使用 jed 编辑一个C语言的源代码文件,可使用如下命令:
jed BubbleSort.c
16.joe 命令
纯文本编辑器,Joe是一个功能强大的全屏幕文本编辑程序。操作的复杂度要比Pico高一点,但是功能较为齐全。Joe一次可开启多个文件,每个文件各放在一个编辑区内,并可在文件之间执行剪贴的动作。
语法
joe [-asis][-beep][-csmode][-dopadding][-exask][-force][-help][-keepup][-lightoff][-arking][-mid][-nobackups][-nonotice][-nosta][-noxon][-orphan][-backpath<目录>][-columns<栏位>][-lines<行数>][-pg<行数>][-skiptop<行数>][-autoindent crlf linums overwrite rdonly wordwrap][+<行数>][-indentc<缩排字符>][-istep<缩排字符数>][-keymap<按键配置文件>][-lmargin<栏数>][-rmargin<栏数>][-tab<栏数>][要编辑的文件]</p>
实例
jed主要用于编辑程序的源码,编辑源码时将以彩色高亮的方式显示程序的语法。例如使用 jed 编辑一个C语言的源代码文件,可使用如下命令:
joe BubbleSort.c
17.join 命令
合并给定文件中的相同字段(必须是 sort 排序之后的文件),指定栏位内容相同的行连接起来。找出两个文件中,指定栏位内容相同的行,并加以合并。
join [-i][-a<1或2>][-e<字符串>][-o<格式>][-t<字符>][-v<1或2>][-1<栏位>][-2<栏位>][--help][--version][文件1][文件2]
用法:
将 a.txt 和 b.txt 两个文件中指定字段的内容相同的行连接起来
join a.txt b.txt
输入命令:
[root@node2 ~]# cat a.txt b.txt hello 123 linux 123 test 123 hello ios linux 456 test php
[root@node2 ~]# join a.txt b.txt hello 123 ios linux 123 456 test 123 php
18.look 命令
Linux look命令用于查询单词。look指令用于英文单字的查询。您仅需给予它欲查询的字首字符串,它会显示所有开头字符串符合该条件的单字。
语法
look [-adf][-t<字尾字符串>][字首字符串][字典文件]
参数说明:
- -a 使用另一个字典文件web2,该文件也位于/usr/dict目录下。
- -d 只对比英文字母和数字,其余一慨忽略不予比对。
- -f 忽略字符大小写差别。
- -t<字尾字符串> 设置字尾字符串。
用法:
为了查找在 testfile 文件中以字母 L 开头的所有的行,可以输入如下命令:
look L testfile
[root@node2 ~]# cat testfile Linux is very excellent. Linux is good to use. hello world! [root@node2 ~]# look L testfile Linux is very excellent. Linux is good to use.
19.mtype 命令
mtype 为 mtools 工具指令,模拟 MS-DOS 的 type 指令,可显示 MS-DOS 文件的内容。
语法
mtype [-st][文件]
参数说明:
- -s 去除8位字符码集的第一个位,使它兼容于7位的ASCII。
- -t 将 MS-DOS 文本文件中的 "换行+光标移至行首" 字符转换成 Linux 的换行字符。
-
mtype dos.txt #打开MS-DOS 文件
20.pico 命令
全屏文本编辑器,pico是个简单易用、以显示导向为主的文字编辑程序,它伴随着处理电子邮件和新闻组的程序pine而来。
语法
pico [-bdefghjkmqtvwxz][-n<间隔秒数>][-o<工作目录>][-r<编辑页宽>][-s<拼字检查器>][+<列数编号>][文件]
用法:
使用pico命令来编辑testfile文件,在终端中输入如下命令:
pico testfile
21.rgrep 命令
Linux rgrep命令用于递归查找文件里符合条件的字符串。
语法
rgrep [-?BcDFhHilnNrv][-R<范本样式>][-W<列长度>][-x<扩展名>][--help][--version][范本样式][文件或目录...]
用法:
rgrep linux *
[root@node2 ~]# rgrep linux * a.txt:linux 123 b.txt:linux 456
22.sed 命令
流式编辑器,Linux sed 命令是利用脚本来处理文本文件。sed 可依照脚本的指令来处理、编辑文本文件。Sed 主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
用法:
在testfile文件的第三行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
sed -e 3a\newLine testfile
[root@node2 ~]# sed -e 3a\newLine testfile Linux is very excellent. Linux is good to use. hello world! newLine
sed 命令是一个非常强大的命令(感兴趣的朋友们可以去学习下,很方便日常操作的)
23.sort 命令
排序指定,sort可针对文本文件的内容,以行为单位来排序。
语法:
sort [-bcdfimMnr][-o<输出文件>][-t<分隔字符>][+<起始栏位>-<结束栏位>][--help][--verison][文件]
用法:
在使用sort命令以默认的式对文件的行进行排序,使用的命令如下:
sort testfile
[root@node2 ~]# cat testfile php 90 java 80 python 100 [root@node2 ~]# sort testfile java 80 php 90 python 100
24.spell 命令
拼写检查指令,拼写错误的单词会输出,spell可从标准输入设备读取字符串,结束后显示拼错的词汇。
检查文件testfile是否有拼写错误,在命令行提示符下输入如下命令:
spell testfile
25.tr 命令
字符处理工具,用于替换和删除给定文本的单个内容。
语法
tr [-cdst][--help][--version][第一字符集][第二字符集] tr [OPTION]…SET1[SET2]
用法:
将文件testfile中的小写字母全部转换成大写字母,此时,可使用如下命令:
cat testfile |tr a-z A-Z
26.uniq 命令
用于去除文件当中的重复行内容(排序过的文件),还可以统计重复行数。Linux uniq 命令用于检查及删除文本文件中重复出现的行列,一般与 sort 命令结合使用。
uniq 可检查文本文件中重复出现的行列。
语法
uniq [-cdu][-f<栏位>][-s<字符位置>][-w<字符位置>][--help][--version][输入文件][输出文件]
例子:
[root@node2 ~]# cat testfile php 90 java 80 python 100 python 100 python 100 java 80 hadoop 120 linux 130 [root@node2 ~]# uniq testfile php 90 java 80 python 100 java 80 hadoop 120 linux 130
27.wc 命令
统计文本文件当中行数、单词数和字符数。Linux wc命令用于计算字数。利用wc指令我们可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。
语法
wc [-clw][--help][--version][文件...]
参数:
- -c或--bytes或--chars 只显示Bytes数。
- -l或--lines 只显示行数。
- -w或--words 只显示字数。
- --help 在线帮助。
- --version 显示版本信息。
在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。使用的命令为:
wc testfile
[root@node2 ~]# cat testfile php 90 java 80 python 100 python 100 python 100 java 80 hadoop 120 linux 130 [root@node2 ~]# wc testfile 8 16 77 testfile
更多详细命令解释大家可以参考:https://www.runoob.com/ 菜鸟教程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号