R3ctf--rCore嵌入式逆向
前言:
首先,这道题涉及到许多的操作系统的知识,让从未做过类似题目的小白受益匪浅;
然后,这个题目会用到qemu,gdb这些,让我也练习到了gdb调试,不再过度依赖与gui页面的ida调试
解题流程:
解包文件系统--->gdb调试附加文件--->关注系统调用的跳转
解包文件系统:
首先,我们要根据这个项目的打包文件去写对应的解包程序,还是要感谢我师哥对我的提示,要不然还在傻傻的调试os,对于这个文档放在了下面的引用中,可以交给deepwiki来审计说明文档,然后让他对应打包文档写一个解包的,我看🐟✌使用ai用的是python写的,挺好用的,我最开始用rust写对应的,不怎么好编译,需要在打包的那个环境中进行本地编译,就直接借鉴大佬的提示来往下做:
import struct
from abc import ABC, abstractmethod
from typing import List, Optional
import threading
import os
BLOCK_SIZE = 512
class BlockDevice(ABC):
@abstractmethod
def read_block(self, block_id: int, buf: bytearray) -> None:
pass
@abstractmethod
def write_block(self, block_id: int, buf: bytes) -> None:
pass
class BlockFile(BlockDevice):
def __init__(self, file_path: str):
self.file_path = file_path
self.lock = threading.Lock()
def read_block(self, block_id: int, buf: bytearray) -> None:
with self.lock:
with open(self.file_path, 'rb') as f:
f.seek(block_id * BLOCK_SIZE)
data = f.read(BLOCK_SIZE)
if len(data) != BLOCK_SIZE:
raise ValueError("Not a complete block!")
buf[:] = data
def write_block(self, block_id: int, buf: bytes) -> None:
with self.lock:
with open(self.file_path, 'r+b') as f:
f.seek(block_id * BLOCK_SIZE)
written = f.write(buf)
if written != BLOCK_SIZE:
raise ValueError("Not a complete block!")
class SuperBlock:
MAGIC = 0x3b800001
def __init__(self):
self.magic = 0
self.total_blocks = 0
self.inode_bitmap_blocks = 0
self.inode_area_blocks = 0
self.data_bitmap_blocks = 0
self.data_area_blocks = 0
@classmethod
def from_bytes(cls, data: bytes):
sb = cls()
values = struct.unpack('<6I', data[:24])
sb.magic, sb.total_blocks, sb.inode_bitmap_blocks, \
sb.inode_area_blocks, sb.data_bitmap_blocks, sb.data_area_blocks = values
return sb
def is_valid(self) -> bool:
return self.magic == self.MAGIC
class DiskInode:
DIRECT_COUNT = 28
def __init__(self):
self.size = 0
self.direct = [0] * self.DIRECT_COUNT
self.indirect1 = 0
self.indirect2 = 0
self.type_ = 0 # 0 = File, 1 = Directory
@classmethod
def from_bytes(cls, data: bytes):
required_size = 128
if len(data) < required_size:
data = data.ljust(required_size, b'\x00')
inode = cls()
# 1 + 28 + 3 = 32 unsigned ints, each 4 bytes, total 128 bytes
values = struct.unpack('<I28I3I', data[:required_size])
inode.size = values[0]
inode.direct = list(values[1:29])
inode.indirect1 = values[29]
inode.indirect2 = values[30]
inode.type_ = values[31]
return inode
def is_dir(self) -> bool:
return self.type_ == 1
class DirEntry:
SIZE = 32
def __init__(self, name: str = "", inode_id: int = 0):
self.name = name
self.inode_id = inode_id
@classmethod
def from_bytes(cls, data: bytes):
name_bytes = data[:28]
name = name_bytes.rstrip(b'\x00').decode('utf-8')
inode_id = struct.unpack('<I', data[28:32])[0]
return cls(name, inode_id)
class EasyFileSystem:
def __init__(self, block_device: BlockDevice):
self.block_device = block_device
self._load_superblock()
def _load_superblock(self):
buf = bytearray(BLOCK_SIZE)
self.block_device.read_block(0, buf)
self.superblock = SuperBlock.from_bytes(buf)
if not self.superblock.is_valid():
raise ValueError("Error loading EFS!")
inode_total_blocks = self.superblock.inode_bitmap_blocks + self.superblock.inode_area_blocks
self.inode_area_start_block = 1 + self.superblock.inode_bitmap_blocks
self.data_area_start_block = 1 + inode_total_blocks + self.superblock.data_bitmap_blocks
def get_disk_inode_pos(self, inode_id: int) -> tuple[int, int]:
inode_size = 128 # Size of DiskInode struct
inodes_per_block = BLOCK_SIZE // inode_size
block_id = self.inode_area_start_block + inode_id // inodes_per_block
offset = (inode_id % inodes_per_block) * inode_size
return block_id, offset
def read_disk_inode(self, inode_id: int) -> DiskInode:
block_id, offset = self.get_disk_inode_pos(inode_id)
buf = bytearray(BLOCK_SIZE)
self.block_device.read_block(block_id, buf)
data = buf[offset:offset + 128]
if len(data) < 128:
data = data.ljust(128, b'\x00')
return DiskInode.from_bytes(data)
class Inode:
def __init__(self, inode_id: int, fs: EasyFileSystem):
self.inode_id = inode_id
self.fs = fs
def ls(self) -> List[str]:
disk_inode = self.fs.read_disk_inode(self.inode_id)
if not disk_inode.is_dir():
return []
file_count = disk_inode.size // DirEntry.SIZE
files = []
for i in range(file_count):
entry_data = self._read_at(i * DirEntry.SIZE, DirEntry.SIZE)
if entry_data:
entry = DirEntry.from_bytes(entry_data)
files.append(entry.name)
return files
def find(self, name: str) -> Optional['Inode']:
disk_inode = self.fs.read_disk_inode(self.inode_id)
if not disk_inode.is_dir():
return None
file_count = disk_inode.size // DirEntry.SIZE
for i in range(file_count):
entry_data = self._read_at(i * DirEntry.SIZE, DirEntry.SIZE)
if entry_data:
entry = DirEntry.from_bytes(entry_data)
if entry.name == name:
return Inode(entry.inode_id, self.fs)
return None
def read_at(self, offset: int, size: int) -> bytes:
return self._read_at(offset, size)
def _read_at(self, offset: int, size: int) -> bytes:
disk_inode = self.fs.read_disk_inode(self.inode_id)
if offset >= disk_inode.size:
return b''
end = min(offset + size, disk_inode.size)
result = bytearray()
current_offset = offset
while current_offset < end:
block_idx = current_offset // BLOCK_SIZE
block_offset = current_offset % BLOCK_SIZE
# Get the actual block ID using multi-level indirection
block_id = self._get_block_id(disk_inode, block_idx)
if block_id == 0:
break
buf = bytearray(BLOCK_SIZE)
self.fs.block_device.read_block(block_id, buf)
bytes_to_read = min(BLOCK_SIZE - block_offset, end - current_offset)
result.extend(buf[block_offset:block_offset + bytes_to_read])
current_offset += bytes_to_read
return bytes(result)
def _get_block_id(self, disk_inode: DiskInode, inner_id: int) -> int:
INODE_DIRECT_COUNT = 28
INODE_INDIRECT1_COUNT = BLOCK_SIZE // 4 # 128 entries per indirect block
INDIRECT1_BOUND = INODE_DIRECT_COUNT + INODE_INDIRECT1_COUNT
if inner_id < INODE_DIRECT_COUNT:
# Direct blocks
return disk_inode.direct[inner_id]
elif inner_id < INDIRECT1_BOUND:
# Indirect1 blocks
if disk_inode.indirect1 == 0:
return 0
buf = bytearray(BLOCK_SIZE)
self.fs.block_device.read_block(disk_inode.indirect1, buf)
indirect_block = struct.unpack('<' + 'I' * (BLOCK_SIZE // 4), buf)
return indirect_block[inner_id - INODE_DIRECT_COUNT]
else:
# Indirect2 blocks
if disk_inode.indirect2 == 0:
return 0
last = inner_id - INDIRECT1_BOUND
indirect1_idx = last // INODE_INDIRECT1_COUNT
indirect1_offset = last % INODE_INDIRECT1_COUNT
buf = bytearray(BLOCK_SIZE)
self.fs.block_device.read_block(disk_inode.indirect2, buf)
indirect2_block = struct.unpack('<' + 'I' * (BLOCK_SIZE // 4), buf)
indirect1_block_id = indirect2_block[indirect1_idx]
if indirect1_block_id == 0:
return 0
self.fs.block_device.read_block(indirect1_block_id, buf)
indirect1_block = struct.unpack('<' + 'I' * (BLOCK_SIZE // 4), buf)
return indirect1_block[indirect1_offset]
def list_and_extract_files(fs_img_path: str, output_dir: str = "./extracted"):
# 打开文件系统镜像
block_device = BlockFile(fs_img_path)
efs = EasyFileSystem(block_device)
root_inode = Inode(0, efs) # 根 inode 通常是 0
# 列出所有文件
print("Files in fs.img:")
files = root_inode.ls()
for filename in files:
print(f" {filename}")
# 提取文件到 output_dir 目录
os.makedirs(output_dir, exist_ok=True)
for filename in files:
file_inode = root_inode.find(filename)
if file_inode:
file_data = file_inode.read_at(0, 1024 * 1024) # 读最多1MB
output_path = os.path.join(output_dir, filename)
with open(output_path, 'wb') as f:
f.write(file_data)
print(f"Extracted: {filename} ({len(file_data)} bytes)")
if __name__ == "__main__":
list_and_extract_files("fs.img")
然后就可以得到对应的文件系统了
逆向调试文件:
调试说明:
对于这次的调试,我们需要与内核的交互,就不能直接当成与普通riscv架构的gdb调试手段
下面是普通附加调试的
qemu-system-riscv64 \
-machine virt \
-bios ./bios.bin \
-serial stdio \
-device loader,file=./os.bin,addr=0x80200000 \
-drive file=./fs.img,if=none,format=raw,id=x0 \
-device virtio-blk-device,drive=x0 \
-device virtio-gpu-device \
-device virtio-keyboard-device \
-device virtio-mouse-device \
-device virtio-net-device,netdev=net0 \
-netdev user,id=net0,hostfwd=udp::6200-:2000,hostfwd=tcp::6201-:80 \
-s \
-S -gdb tcp::1234
gdb-multiarch ./snake
下面是这次调试的:
qemu-system-riscv64 \
-machine virt \
-bios ./bios.bin \
-serial stdio \
-device loader,file=./os.bin,addr=0x80200000 \
-drive file=./fs.img,if=none,format=raw,id=x0 \
-device virtio-blk-device,drive=x0 \
-device virtio-gpu-device \
-device virtio-keyboard-device \
-device virtio-mouse-device \
-device virtio-net-device,netdev=net0 \
-netdev user,id=net0,hostfwd=udp::6200-:2000,hostfwd=tcp::6201-:80 \
-s \
-S -gdb tcp::1234
riscv64-unknown-elf-gdb snake
正式逆向:
首先肯定是先静态看嘛,因为前面有一个游戏,找到判断的地方修改寄存器就行
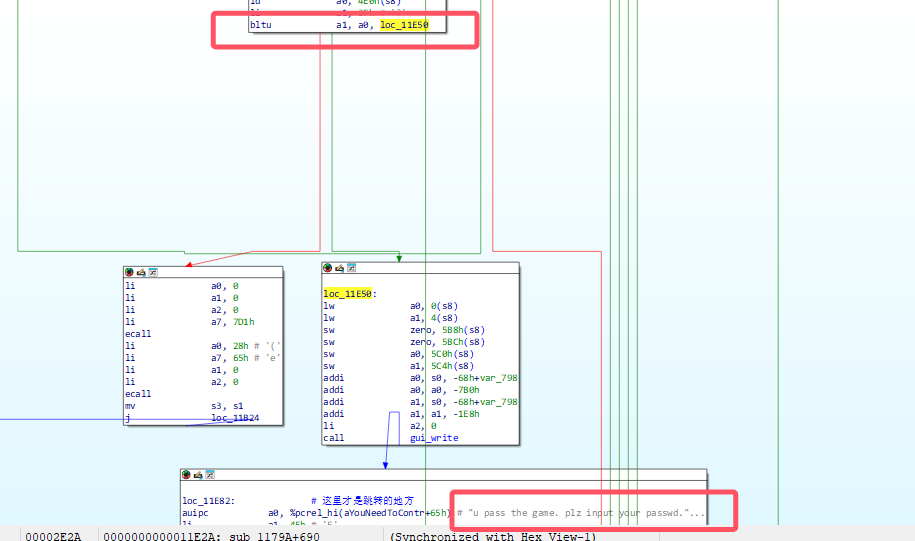
rust逆向就是靠关键字符串定位
只需要在上面bltu的地方修改寄存器a0为64就行
然后接下来会进行一系列系统号的调用
系统调用的跟随:
因为有些系统调用是自定义在操作系统的,我们必须到os.bin中去看他的逻辑,众所周知,从用户态到内核态会有中断处理,我就是找到的中断处理然后一点点往下跟的,其实不需要这样,走弯路了,两个方法:
1、直接搜调用号(有时不一定能找到);
2、去搜索syscall找到引用的地方就可以拿到了

继续调试逆向:
流程说明:
接下来就没有什么特殊的地方了,就是常规的逆向算法了,先说一下这个关键算法加密流程吧:
首先程序会进入调用号4000,a7寄存器中存放,4000中是对input的乱序
然后进入调用号4001,这里存放着AES的key,直接dump
然后返回snake用户程序,可以找到这个AES加密
最后进入调用号4002,这里是一个tea加密,只是有点难看罢了(步过可以去找rust写的TEA算法,去看能不能找到作者原版代码)
syscall_4000:
这个可以在os.bin中找到地址是80208E1E
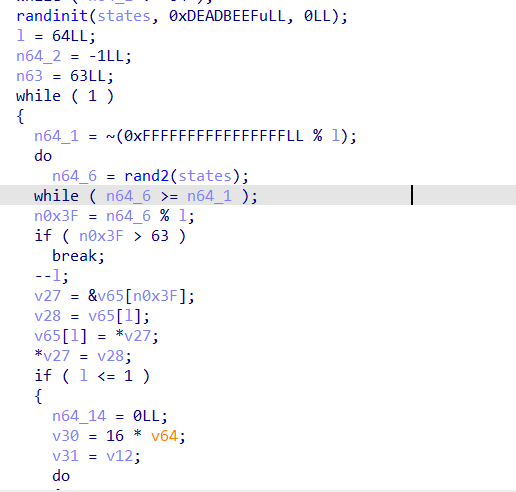
交给AI分析一下是一个变换序列的功能,我们可以copy代码运行一下看看前后的顺序是什么,也可以动态调试dump结束后的序列得到:
输入 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz+-
80208F48这里开始是开始交换顺序的地方
.text:0000000080208F48 add a0, a0, s7
.text:0000000080208F4A add a1, s7, s9
.text:0000000080208F4E lbu a2, 0(a0)
.text:0000000080208F52 lbu a3, 0(a1)
.text:0000000080208F56 sb a2, 0(a1)
.text:0000000080208F5A sb a3, 0(a0)

乱序后的

就这样得到了序列:
def desyscall_4000(buf):
ori = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23,
24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43,
44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63]
tar = [28, 33, 13, 11, 19, 45, 34, 0, 5, 61, 46, 31, 39, 8, 38, 7, 42, 24, 32, 36, 22, 4,
52, 29, 43, 25, 10, 9, 60, 63, 37, 48, 55, 35, 59, 23, 58, 41, 62, 49, 16, 53,
47, 40, 14, 26, 54, 50, 20, 15, 18, 56, 6, 57, 27, 1, 51, 30, 44, 17, 21, 2, 3, 12]
ans = [0] * 64
for i in range(len(buf)):
ans[tar[i]] = buf[i] # 修正此处
return ans
下面是加密的还原:
mask32 = (1 << 32) - 1
mask64 = (1 << 64) - 1
mask128 = (1 << 128) - 1
def randinit(k):
v3 = (0x2360ED051FC65DA4 * k) & mask64
v4 = ((0x4385DF649FCCF645 * k) >> 64) & mask64
v5 = (0x4385DF649FCCF645 * k) & mask64
res = []
res0 = (v5 - 0x78E366AFA5CC7E86) & mask64
res1 = ((v5 >= 0x78E366AFA5CC7E86) + v3 + v4 + 0x5DB0E700D4B19567) & mask64
res.append(((res1 << 64) | res0) & mask128)
res2 = 0xB7860F7A9A5F029F
res3 = 0x5FC1C2D3FF7A0DC6
res.append(((res3 << 64) | res2) & mask128)
return res
def rand2(state):
res = ((state[0] >> 58) ^ (state[0] >> 87)) & mask64
rot = state[0] >> 122
res = ((res >> rot) | (res << (64 - rot))) & mask64
state[0] = 0x2360ed051fc65da44385df649fccf645 * state[0] + state[1] & mask128
return res
def syscall_4000(buf):
k1 = 0xdeadbeef
k2 = 0
state = randinit(k1)
l = 64
while l > 64:
while True:
v = rand2(state)
if v < ~(0xFFFFFFFFFFFFFFFF % l):
break
i = v % l
l -= 1
buf[i], buf[l] = buf[l], buf[i]
syscall_4001:
接下来跳转4001

就是一个RC4,稍微改了一下,dump密钥
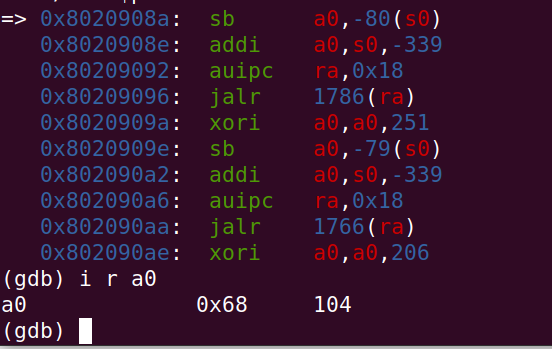

dump拿到了密钥,16字节
0x68,0x61,0x76,0x34,0x5f,0x61,0x5f,0x67,0x30,0x30,0x64,0x5f,0x74,0x31,0x6d,0x34
下面是算法的还原
def init_sbox(key):
s_box = list(range(256)) # 初始化 S-box
key_len = len(key)
if key_len != 0:
index = 0
j = 0
key_pos = 0
while index < 256:
if key_pos >= key_len:
key_pos = 0 # 模拟 key 重复使用
key_byte = key[key_pos]
key_pos += 1
current_value = s_box[index]
j = (j + j * index + key_byte + current_value) & 0xFF # 保证 0-255 范围
# 交换 s_box[index] 和 s_box[j]
s_box[index], s_box[j] = s_box[j], s_box[index]
index += 1
return s_box # 返回初始化好的 S-box
def KeyStream(length, Sbox, key):
# 生成密钥流
s = Sbox.copy()
(i, j) = (0, 0)
k = [0] * length
for r in range(length):
i = (i + 1) % 256
j = (j + s[i]) % 256
s[i], s[j] = s[j], s[i]
t = (s[i] + s[j]) % 256
k[r] = s[t] # 生成密钥流
return k
def syscall_4001():
# 定义密钥和异或密钥(保持原值)
keys = [0x69, 0x6E, 0x5F, 0x72, 0x33, 0x63, 0x74, 0x66] # ASCII "in_r3ctf"
xorkey = [
0x01, 0xFB, 0xCE, 0x99,
0x7D, 0xDC, 0xD2, 0x9D,
0xA2, 0xE5, 0xFA, 0x13,
0xAB, 0x4E, 0x8C, 0x1D
]
# 初始化S盒和密钥流(假设init_sbox和KeyStream已正确定义)
sbox = init_sbox(keys) # 使用密钥初始化S盒
keystream = KeyStream(16, sbox, keys) # 生成16字节密钥流
# 执行逐字节异或操作
result = bytearray()
for i in range(16):
result.append(keystream[i] ^ xorkey[i])
return result
snake_AES:
继续往下走,会发现有一个AES的SOB,挺明显的,但是这个架构编译出来挺丑的,但是我们都拿到那个16字节的key了直接调用就行了
使用插件也可以发现这个加密

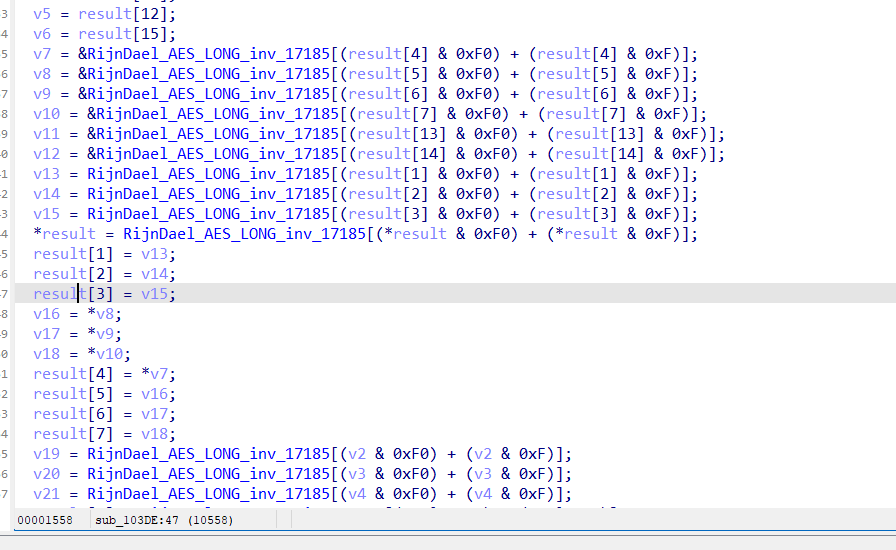
直接调用解密就行啦
syscall_4002:
我们最开始找系统号调用的时候发现了有三个,另外一个可能就存着密文和判断逻辑,直接去最后输出对错的地方找
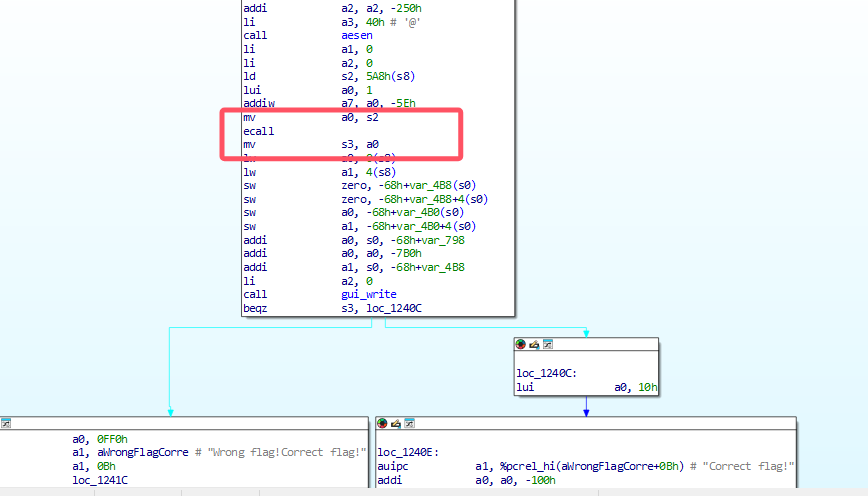
剩下的一部分,我们也没办法进行dump了,只能老老实实解这个tea了,很难看,交给AI把

解密就行了,看大佬的吧,我写的很丑陋
def syscall_4002(inp):
target = bytes.fromhex(
'8fa816a57febd339903ada09539fc20900fca8744ae927f48df8ee4d26da9c14f308c5919700e9f8d6537d18bb5c4525668f136c3715485bdd21212254752e02')
buf = list(struct.unpack('>16I', inp))
detla = -1640531527
for j in range(2):
sums = 0
for i in range(64):
buf[8 * j + 0] += ((16 * buf[8 * j + 1] + 0x66616365) ^ (buf[8 * j + 1] + sum) ^ (
(buf[8 * j + 1] >> 5) + 0x66343464)) & mask32
buf[8 * j + 2] += ((16 * buf[8 * j + 3] + 0x66616365) ^ (buf[8 * j + 3] + sum) ^ (
(buf[8 * j + 3] >> 5) + 0x66343464)) & mask32
buf[8 * j + 4] += ((16 * buf[8 * j + 5] + 0x66616365) ^ (buf[8 * j + 5] + sum) ^ (
(buf[8 * j + 5] >> 5) + 0x66343464)) & mask32
buf[8 * j + 6] += ((16 * buf[8 * j + 7] + 0x66616365) ^ (buf[8 * j + 7] + sum) ^ (
(buf[8 * j + 7] >> 5) + 0x66343464)) & mask32
buf[8 * j + 1] += ((16 * buf[8 * j + 0] + 0x63306434) ^ (sum + buf[8 * j + 0]) ^ (
(buf[8 * j + 0] >> 5) + 1667327540)) & mask32
buf[8 * j + 3] += ((16 * buf[8 * j + 2] + 0x63306434) ^ (sum + buf[8 * j + 2]) ^ (
(buf[8 * j + 2] >> 5) + 1667327540)) & mask32
buf[8 * j + 5] += ((16 * buf[8 * j + 4] + 0x63306434) ^ (sum + buf[8 * j + 4]) ^ (
(buf[8 * j + 4] >> 5) + 1667327540)) & mask32
buf[8 * j + 7] += ((16 * buf[8 * j + 6] + 0x63306434) ^ (sum + buf[8 * j + 6]) ^ (
(buf[8 * j + 6] >> 5) + 1667327540)) & mask32
sum = sum - detla & mask32
return buf
def desyscall_4002():
target = bytes.fromhex(
'8fa816a57febd339903ada09539fc20900fca8744ae927f48df8ee4d26da9c14f308c5919700e9f8d6537d18bb5c4525668f136c3715485bdd21212254752e02')
v = list(struct.unpack('>16I', target))
for j in range(2):
sum = -1640531527 * 64 & mask32
for i in range(64):
v[8 * j + 7] = v[8 * j + 7] - (((v[8 * j + 6] << 4) + 1664115764) ^ (v[8 * j + 6] + sum) ^ (
(v[8 * j + 6] >> 5) + 1667327540)) & mask32
v[8 * j + 5] = v[8 * j + 5] - (((v[8 * j + 4] << 4) + 1664115764) ^ (v[8 * j + 4] + sum) ^ (
(v[8 * j + 4] >> 5) + 1667327540)) & mask32
v[8 * j + 3] = v[8 * j + 3] - (((v[8 * j + 2] << 4) + 1664115764) ^ (v[8 * j + 2] + sum) ^ (
(v[8 * j + 2] >> 5) + 1667327540)) & mask32
v[8 * j + 1] = v[8 * j + 1] - (((v[8 * j + 0] << 4) + 1664115764) ^ (v[8 * j + 0] + sum) ^ (
(v[8 * j + 0] >> 5) + 1667327540)) & mask32
v[8 * j + 6] = v[8 * j + 6] - (((v[8 * j + 7] << 4) + 1717658469) ^ (v[8 * j + 7] + sum) ^ (
(v[8 * j + 7] >> 5) + 1714697316)) & mask32
v[8 * j + 4] = v[8 * j + 4] - (((v[8 * j + 5] << 4) + 1717658469) ^ (v[8 * j + 5] + sum) ^ (
(v[8 * j + 5] >> 5) + 1714697316)) & mask32
v[8 * j + 2] = v[8 * j + 2] - (((v[8 * j + 3] << 4) + 1717658469) ^ (v[8 * j + 3] + sum) ^ (
(v[8 * j + 3] >> 5) + 1714697316)) & mask32
v[8 * j + 0] = v[8 * j + 0] - (((v[8 * j + 1] << 4) + 1717658469) ^ (v[8 * j + 1] + sum) ^ (
(v[8 * j + 1] >> 5) + 1714697316)) & mask32
sum = sum + 1640531527 & mask32
return struct.pack('>16I', *v)
总结:
加密解密的代码如下:
def encode(buf):
buf = syscall_4000(buf)
buf = AES.new(syscall_4001(), AES.MODE_ECB).encrypt(bytes(buf))
return syscall_4002(buf)
def decode():
buf = desyscall_4002()
# 将整数列表转换为 bytes(每个整数是 4 字节)
print(buf)
# AES 解密
decrypted = AES.new(syscall_4001(), AES.MODE_ECB).decrypt(buf)
# 转换为列表
decrypted_list = list(decrypted)
# 执行反洗牌
result = desyscall_4000(decrypted_list)
# 打印结果
print("Result as bytes:", bytes(result))
print("Result as hex:", bytes(result).hex())
print("Result as string (if printable):", bytes(result).decode(errors='ignore'))
decode()
解题的流程就是这样,体验了一次gdb的使用,以及内核调用题的解法,还是收获蛮大的
引用:
Rcore-os项目:https://github.com/rcore-os/rCore-Tutorial-v3
rCore-os的说明文档:https://ycznkvrmzo.feishu.cn/docx/JNd6ddaPzotsVWxRtEScMfxynec
参考了LaoGong 战队中逆向大佬对这个题目的解析 https://ycznkvrmzo.feishu.cn/docx/JNd6ddaPzotsVWxRtEScMfxynec

 浙公网安备 33010602011771号
浙公网安备 33010602011771号