
pandas(10):数据增删改
目录
一个数据框包含索引和数据,可以对索引和数据进行操作。原始数据框:
# 数据
index = [['a','a','b','b'],[1,2,3,4],[4,3,2,1]]
dict = {
'姓名':['任*','江*','陈*','罗*'],
'数学':[67,81,81,62],
'语文':[71,91,67,61]
}
df = pd.DataFrame(data=dict,index=index)
df
一、对索引进行操作
索引常见的属性:索引值、索引名称、索引类型等。
1 操作索引值df.rename()
df.rename(mapper=None, index=None, columns=None,
axis=None, copy=True, inplace=False, level=None)
| 参数说明: |
- mapper:dict or function,映射关系,可以是字典,也可以是一个函数。
- index、columns、axis:3个参数作用类似,用来控制轴向,默认为行。
- copy:默认为True,拷贝底层数据。
- level :int,level name,default none,针对多层索引,控制操作的索引层级。
df.rename(index = mapper) 等价于 df.rename(mapper)
df.rename(columns=mapper) 等价于 df.rename(mapper,axis=1)
# 传入字典
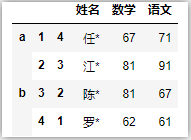
df.rename({2:222})
# 传入函数
df.rename(lambda x: str(x) + '_t')
# 指定轴向,方式一
df.rename(lambda x: x + '_t',axis=1)
# 指定轴向,方式二
df.rename(columns=lambda x: x + '_t')
# 指定索引层级
df.rename(index={1:'tt'},level=2)
备注:也可以用df.set_axis()将所需的索引更新给给定的轴。参考网站:https://www.cjavapy.com/article/772/
二、指定数据替换、修改df.replace()
可以全表替换df.replace() ,或只替换某列df[col]replace()。
df.replace(to_replace=None, value=None, inplace=False,
limit=None, regex=False, method='pad')
| 参数说明: |
- to_replace: str, regex, list, dict, Series, int, float, or None。被替换的值
- value:替换后的值
- inplace:是否要改变原数据,False是不改变,True是改变,默认是False
- limit:控制填充次数,和method参数搭配使用。
- regex:是否使用正则,False是不使用,True是使用,默认是False
- method:填充方式,pad,ffill,bfill,默认为pad。pad/ffill向前填充,用前一个值填充;bfill向后填充。设置这个参数后,就不用了设置替换的值value了。
# 某1列
df['数学'].replace(67,100)
# 某几列
df[['数学','语文']].replace(67,100)
# 某1行
df.iloc[0].replace(67,100)
# 某几行
df.iloc[0:3].replace(67,100)
# 整个数据框,所有61换成100
df.replace(61,100)
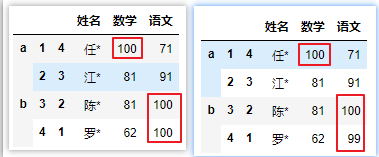
# 多对一映射,67和61都换成100
df.replace([67,61], 100)
# 一对一映射,67->100,61->99,对应替换
df.replace([67,61],[100,99])
# 向前填充,
# 设置method时,只需要传入被替换的值
# df.replace(np.nan,method='bfill') # method参数一般用于填充空值
df.replace(81,method='pad')
# 向后填充
df.replace(81,method='bfill')
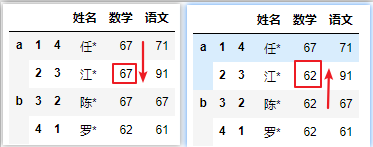
# 传入字典一一对应
df.replace({67: 100,61: 99})
# 修改指定列的指定值,
df.replace({'姓名': '任*','数学': 81}, 100)
# 嵌套字典,指定列的值一一对应修改
df.replace({'姓名':{'任*':99, '江*': 100}})
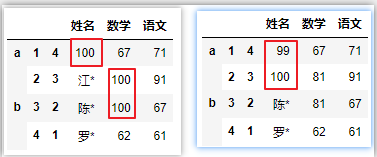
# 限制填充个数,结合method参数使用
df.replace(81,limit=1)
# 使用正则表达式,regex=True
#用r''表示''内部的字符串默认不转义
df.replace(r'[\u4E00-\u9FA5]\W','正则',regex=True)
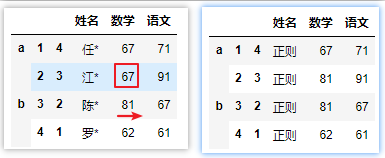
三、特殊值——缺失值处理
对于空值,pandas有专门删除函数df.dropna()和填充函数df.fillna(0)。
跳转连接:缺失值处理
四、新增行列
1 直接赋值添加新列
# 增加一列,全是100
df['英语'] = 100
# 根据已存列,计算新列
df['总分'] = df['数学'] + df['语文'] + df['英语']
# 推荐使用.loc的方式来赋值一列,直接用df[xxx]=的方式在某些情况会出现警告(链式)
df.loc[:, '测试'] = 'test'
# 根据其他列条件新增列
df.loc[df['数学']>= 80 ,'数学优秀'] = '优良'
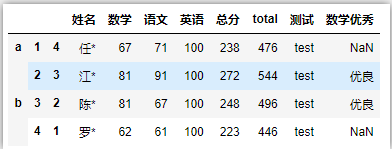
2 df.assign()函数添加新列
df.assign(**kwargs)
返回值:一个新的DataFrame对象。注意新增的列名不加引号。
# 新增一列,返回是新的DataFrame对象,改变原DF,需要赋值生效
df.assign(性别='男')
# df = df.assign(性别='男')
# 计算增加列
df.assign(t1=df['语文']-df['数学'])
# lambda表达式
df.assign(t2=lambda x: x['数学']*1.2+15)
# 逻辑判断,返回bool值:True or False
df.assign(t3=df['数学']>df['语文'])
# 类型转换,返回1 或 0
df.assign(t4=(df['数学']>df['语文']).astype(int))
# map映射,返回指定值
df.assign(t5=(df['数学']>df['语文']).map({True:'大于',False:'小于'}))
# 同时增加多列,且列之间有关联
df.assign(col1=lambda x: x['数学']*5,
col2 = lambda x: x['语文']*5,
col3 = lambda x: x['col1'] - x['col2']) # col1和col2没有直接生效,不能直接用df['col1']

3 df.eval()函数新增新列
df.eval(expr, inplace=False, **kwargs)
| 参数说明: |
- expr:str,字符串计算评估表达式,表达式可以直接使用列名
- inplace:默认为False
- 可以接受关键参数
返回:ndarray、标量、pandas对象。根据表达式计算列关系,可以指定列名生成新列。
# 直接使用列名,返回series
df.eval('语文 + 数学')
# 生成新列,返回DataFrame
df.eval('e1 = 语文 + 数学')
# df.eval('e1 = 语文 + 数学',inplace=True) 立即生效
# 生成两列,有依赖关系,必须用三引号
df.eval("""c2 = 语文 + 数学
c2_1 = c2 + 英语"""
)
temp = df['语文'].mean()
# 使用外部变量
df.eval('e2 = 数学 - @temp')
# 逻辑判断,True or False
df.eval('e3 = 10 < (数学 - @temp)')

4 df.insert()任意位置插入新列
可以根据列索引位置插入新列。参考网站:df.insert()
5 依据新索引插入新行
6 df.append()追加新行
7 pd.concat()通过拼接的方式加新行
五、删除行列
1 df.pop()直接删除某列
删除某一列(不能是多列),只有一个参数,就是列名,传入str参数。返回:被删除的列,原df直接处理。
2 df.drop()删除指定多行或多列
df.drop(labels=None, axis=0, index=None, columns=None,
level=None, inplace=False, errors='raise')
通过指定标签名称和相应的轴,或直接指定索引或列名称,删除行或列。使用多索引时,可以通过指定级别来删除不同级别上的标签。
| 参数说明: |
- labels:要删除的列或者行,多个传入列表
- axis:轴的方向,0为行,1为列,默认为0
- index:单个标签或类似列表,指定轴的替代方法(labels, axis=0 等价于 index=labels)
- columns:单标签或类似列表,指定轴的替代方法(labels, axis=1 等价于 columns=labels)
- level:int或级别名称,可选,对于MultiIndex,将从中删除标签的级别。
- inplace:
- errors:{'ignore','raise'},默认为'raise',如果'ignore',则抑制错误,仅删除现有标签 。
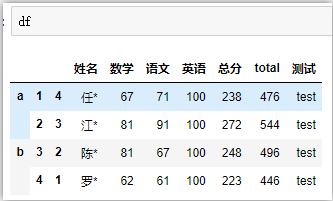
# 删除列
df.drop(['数学','语文'],axis=1)
# df.drop(columns=['数学','语文']) 等价
# 删除a层级的所有行
df.drop(['a'])
# 删除第2层级的,索引为1的行
df.drop(index=1,level=1)
# 删除行列:删除b层级所有行和‘测试这一列’
df.drop(index='b',columns=['测试'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号