


https://github.com/BTD892/python1
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 15 | 15 |
| · Design Review | · 设计复审 | 0 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 0 | 0 |
| · Design | · 具体设计 | 120 | 240 |
| · Coding | · 具体编码 | 240 | 300 |
| · Code Review | · 代码复审 | 360 | 420 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 90 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 120 |
| · 合计 | 1085 | 1405 |
三、计算机模块接口
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
在查询资料后得知了DFA过滤算法检测敏感词,其思想是基于状态转移来检索敏感词,只需对文本进行一次扫描即可对所有敏感词进行检测。DFA形成的数据存储结构如下图

然而,最基础的dfa算法依旧无法满足题目需求。于是在此基础上我又利用拼音的各个字母形成类似以上的结构来协助使用
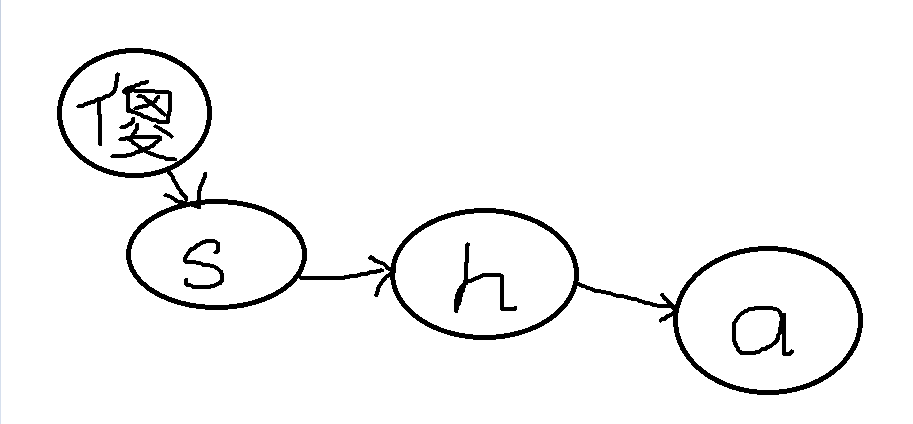
对于这些结构使用了函数add_word(),结果如图,然后本人因为懒惰,还写了个字典来存储汉字与其对应的拼音当个”字典“,方便谐音字转化

整体的匹配算法是以dfa为主,遇到拼音时在里面对上述生成的字典用一个小循环进行扫描,缩写也是类似
总的就一个DFA类,里面有一些需要用到的字典及队列,还有对应使用的函数add_word()和match_word()
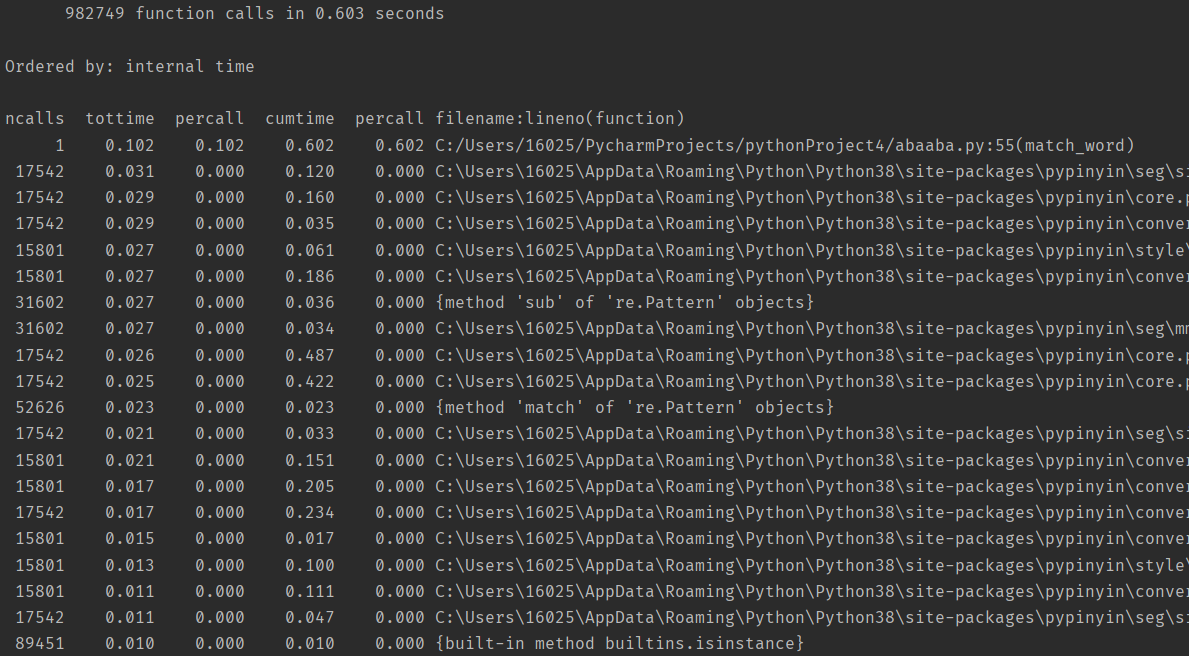
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
由下图可见,最占据运行时间的是来自pinyin库的函数,即汉字转化成拼音,或许拆字的功能添加上去后可以夺得桂冠,但是我实在找不到python里拆字功能的实现样例,人是真麻了。所以只能基于减少pinyin库函数的使用作为思路进行优化,然而为了实现检测到谐音字的功能,又不得不对整体的文本进行拼音转化(或许有更好的方法,但是人菜实在想不出来TT-TT),这样进一步限制了优化的思路。再思虑到后面有可能添加上的拆字功能,必将会占据运行时间的大头,笔者不得已放弃了对他的优化。还不如提早花费时间去解决拆字功能的实现,然后再针对其进行优化。然而天不随人愿,只能后续看看大佬操作了
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
def test_add(self):
word = "test_word.txt"
tmp_ans = {'N': '脑', 'S': '傻', 'is_end': False, '傻': {'B': '逼', 'is_end': False, '逼': {'is_end': True}}, '脑': {'C': '残', 'is_end': False, '残': {'is_end': True}}}
self.dfa.add_word(word)
self.assertEqual(self.dfa.s_word, tmp_ans)
def test_match(self):
org = "test_org.txt"
self.dfa.add_word("test_word.txt")
self.dfa.match_word(org)
self.assertEqual(self.dfa.answer, ['Line1: <傻逼> 傻逼', 'Line2: <脑残> 脑残'])
首先是最基础的匹配

然后是尝试拼音,缩写以及谐音字



关于测试数据的构造,主要针对于缩写和拼音这两个功能的是否会冲突和重叠
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
if len(sys.argv) != 4:
print("error")
exit(-1)
防止输入参数不为3个
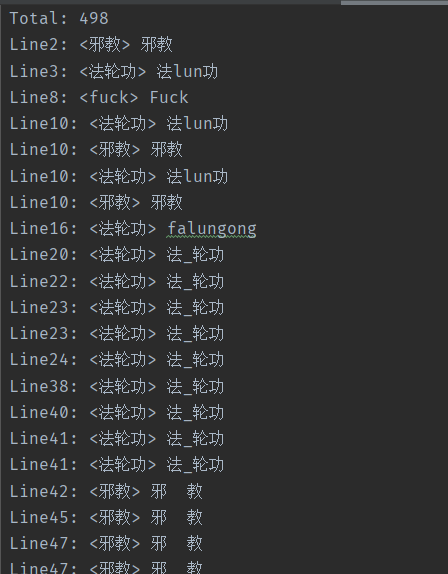
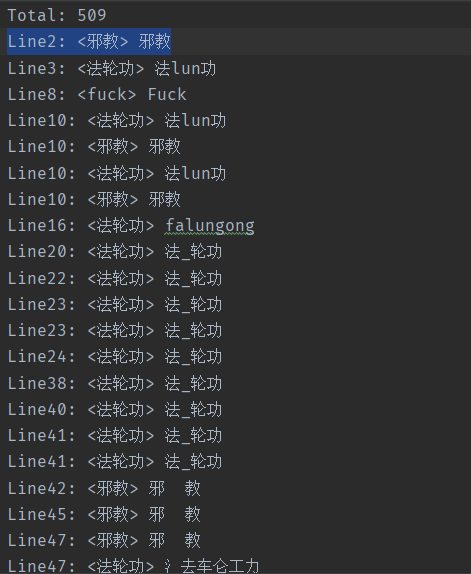
最终答案对比
四、心得体会
这次作业收获还是挺大的,不仅重温了python语法,还学习了新的算法,对一些项目制作的步骤有了一定了解,遗憾的是实现不了拆分汉字偏旁的功能。
