
倒排索引
将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。那么索引里面究竟存的什么,以及如何创建索引呢?在这通过下面的例子来解答这个问题。
首先构造三个不同的句子,有长有短:
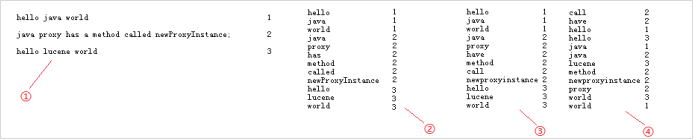
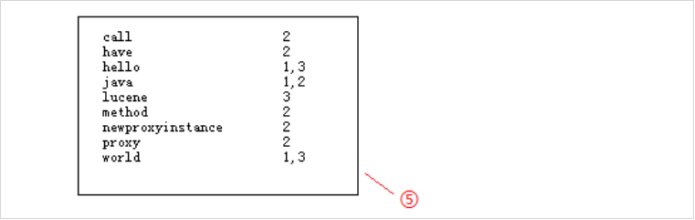
在①处分别为3个句子加上编号,然后进行分词,把被一个单词分解出来与编号对应放在②处;在搜索的过程总,对于搜索的过程中大写和小写指的都是同一个单词,在这就没有区分的必要,按规则统一变为小写放在③处;要加快搜索速度,就必须保证这些单词的排列时有一定规则,这里按照字母顺序排列后放在④处;最后再简化索引,合并相同的单词,就得到如下结果:
通常在数据库中我们都是根据文档找到内容,而这里是通过词,能够快速找到包含他的文档,这就是文档倒排链表。
以上就是lucene索引结构中最核心的部分。我们注意到关键字是按字符顺序排列的(lucene没有使用B树结构),因此lucene可以用二元搜索算法快速定位关键词。
3.2.2.索引搜索
就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。

比如我们要搜
索java world两个关键词,符合java的有1,2两个文档,符合world的有1,3两个文档,在搜索引擎中直接这样排列两个词他们之间是OR的关系,出现其中一个都可以被找到,所以这里3个都会出来。全文检索中是有相关性排序的,那么结果在是怎么排列的呢?hello java world中包含两个关键字排在第一,另两个都包含一个关键字,得到结果,hello lucene world排在第二,java在最长的句子中占的权重最低排在结果集的第三。从这里可以看出相关度排序还是有一定规则的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号