
旧,HTTP协议介绍
HTTP协议 超文本传输协议
HTTP协议版本主要有1.0和1.1 版本
HTTP1.0
HTTP1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个tcp连接,服务器完成请求处理后即断开Tcp连接,服务器不跟踪每个客户,也不记录过去的请求
HTTP1.1
在连接方面,HTTP1.1 支持持久连接,在一个tcp连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和时间延迟。
在请求头方面,http/1.1 增加了更多的请求头和响应头信息,用以增强http功能。例如: host 主机头功能,可以让Web 浏览器使用主机头名来明确表示要访问服务器上的那个web站点,这样就可以使用web服务器在同一个ip地址和端口上配置多个虚拟web站点,
HTTP/1.1的持久连接,也需要增加新的请求头来帮助实现,例如,connection请求头的值为Keep-Alive时,表示客户端通知服务器返回本次请求结果后保持连接; Connection请求头的值为close时,表示客户端通知服务器返回本次请求结果后关闭连接。HTTP/1.1 还提供了与身份认证、状态管理和Cache缓存等机制相关的请求头和响应头等
HTTP请求方法
在HTTP通信中,每个HTTP 请求报文都包含一个方法,用以告诉Web服务端需要执行那些具体的动作,这些动作包括:获取指定Web页面,提交内容到服务器,删除服务器上资源文件等,这些HTTP请求报文中保含的方法被称为HTTP请求方法,常见的HTTP 请求方法
| HTTP方法 | 作用描述 |
|
GET |
客户端请求指定资源信息,服务器返回指定资源 |
| HEAD | 只请求响应报文中的HTTP首部 |
| POST | 将客户端的数据提交到服务器 |
| PUT | 用从客户端向服务器传送的数据取代指定的文档内容 |
| DELETE | 请求服务器删除request-URI所标识的资源 |
| MOVE | 请求服务器将指定的页面移到另一个网络地址 |
HTTP状态码
http 状态码(HTT status code) 是用来表示Web 服务器响应HTTP请求状态的数字代码。每当Web客户端向Web 服务器发送一个HTTP请求时,Web服务器都会返回一个状态响应代码。这个状态码是一个三位数字代码,作用是告知Web客户端此次请求是否成功,或者是否采取其他的动作方式
HTTP协议1.1 版本中的状态码可以分为五大类,如表4-2 所示。
表4-2 不同范围的状态码及其对应的作用
| 状态码范围 | 作用描述 |
| 100 ~ 199 | 用于指定客户端响应相应的某些动作 |
| 200 ~ 299 | 用于表示请求成功 |
| 300 ~ 399 | 用于已经移动的文件,并且常被包含在定位头信息中指定新的地址信息 |
| 400 ~ 499 | 用于指出客户端的错误 |
| 500 ~ 599 | 用于指出服务器的错误 |
生产场景常见的状态码及其对应的作用
| 状态码 | 详细描述说明 |
| 200-OK | 服务器成功返回网页,这是成功的http请求返回的标准状态吗 |
| 301-Moved Permanently | 永久跳转,所请求的网页将永久跳转到被设定的新的位置,例如:从etiantian.org跳转到www.etiantian.org |
| 403-Forbidden | 禁止访问,虽然这个请求是合法的,但是服务器端因为匹配了预先设置的规则而拒绝响应客户端的请求,此类问题一般为服务器或服务权限配置不当所致 |
| 404-Not Found | 服务器找不到客户端请求的指定页面,可能是客户端请求了服务器上不存在的资源所致 |
| 500-Internal Server Error | 内部服务器称为,服务器遇到了意料不到的情况,不能完成客户的请求。这是一个较为笼统的报错,一般为服务器的设置或内部程序问题导致。例如:SELinux 开启,而又没有为HTTP设置规则许可,客户端访问就是500 |
| 未完待续~~~ | |
HTTP 报文格式
HTTP报文可分为两种,一种是从Web客户端发往Web服务器的HTTP报文,称为请求报文(Request Message)。另一种是从Web服务器发往Web客户端的报文,称为响应报文(Response Message),HTTP的请求和响应报文的格式类似。
1.HTTP 请求报文(Request Message) 介绍
HTTP请求报文由 请求行,请求头部(header),空行,请求报文主体几部分组成
http请求报文格式说明
| 报文格式 | 报文信息 | 描述 | ||||||||||||
| 请求行 | 请求方法 ,URL , 协议版本 | 用来说明客户端想要做什么。内容由请求方法字段、URL字段和HTTP协议版本字段组成,它们之间用空格分开 | ||||||||||||
| 请求头部 |
字段名1:值1 字段名2 :值2 ...
|
请求头部由关键字/值对组成 ,每行一对,关键字和值用因为冒号":" 分隔。请求头部的作用是通过客户端把请求的相关信息告诉服务器,常见的请求头部信息:
|
||||||||||||
| 空行 | 空白无内容 | 通知web服务器空行以下不会再有请求头部的信息了 | ||||||||||||
| 请求报文主体 | Get 请求方法没有请求报文主体,Post 方法才有 | 请求报文主体中包括了要发给Web服务器的数据信息。 |
HTTP响应报文由起始行,响应头部(header),空行,响应报文主体
| 报文格式 | 报文信息 | 描述 |
| 起始行(状态行) | 协议及版本号、数字状态码、状态信息 | 用来说明服务器响应客户端请求的状况 |
| 响应头部 |
字段名1:值1 例如: |
由 键:值对组成 |
| 空行 | 空白无内容 | 通知客户端空行以下不会再有头部的信息了 |
| 响应报文主体 | 装载了要返回给客户端的数据,这些数据既可以是文本,也可以是二进制(如图片,视频) |
HTTP协议原理(HTTP协议属于OSI模型种的第七层协议)
在Web客户端向Web服务器发送请求报文之前,先通过TCP/IP协议在Web客户端和服务端之间建立一个TCP/IP连接。整个HTTP协议请求的工作流程如下
1.客户端用浏览器访问web服务器 如www.itxiaonengsho.com
2.web浏览器请求DNS服务器,把域名解析为ip地址
3.web浏览器通过解析后的ip地址及端口号与web服务器建立一条tcp连接
4.建立tcp连接后,web浏览器向web服务器发送一条http请求报文,
5.web服务器响应并读取浏览器的请求信息,然后返回一条HTTP响应报文
6.web服务器关闭http连接,关闭TCP连接,web浏览器显示访问的网站内容
HTTP 资源
媒体类型
互联网上的数据有很多不同类型,Web服务器会把通过Web传输的每个对象都打上MIME类型(MIME type)的数据格式的标签
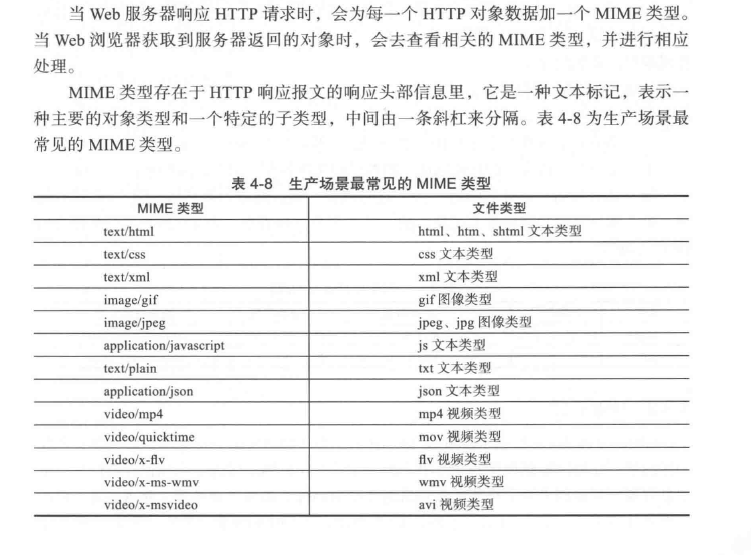
可以从nginx的配置文件conf目录下。查看其支持的媒体类型
less mime.types
URL 介绍
URL ,全称为Uniform Resource Location,中文翻译为统一资源定位符,也称为网页地址(网址)。如同门牌一样,它是因特网上标准的资源唯一地址。通俗地说,URL是Internet 上用来描述信息资源的字符串,主要用在各种www客户端和服务器程序上。URL可以用一种统一的格式来描述各种信息资源,包括文件,服务器的地址和目录等。严格来讲,每个URL都是一个URI,它标识一个互联网资源,并指定对其进行操作或取得该资源的方法
URL的格式由下了三部分组成:
第一部分是协议,例如:http
第二部分是主机资源服务器ip地址或域名(端口号),例如:www.etiantian.org
第三部分是主机资源的具体地址,如目录和文件名等,例如:oldboy/index.html
URL未完待续~~~~
URI
URI,全程为Uniform Resource Identifier ,中文翻译为统一资源标识符,是一个用于标识某一互联网资源名称的字符串。这个字符串在世界范围内唯一标识并定位某一个信息资源。互联网上每个可用的数据资源(如HTML、图片、视频)皆通过统一资源标识符进行定位。URL是URI的子集。
静态网页资源
1.静态网页资源介绍
在网页设计中,纯粹HTML格式的网页通常被称为“静态网页”,静态网页是相对于动态网页而言的,是指没有后台数据库、不含程序(如PHP、JSP、ASP)、不可交互的网页
2.静态网页资源的特点
静态网页资源的特点是,开发者编写的是什么,它显示的就是什么,一旦编写完成,就不会有任何改变。静态网页的维护和更新相对比较麻烦,每个不同的网页都需要单独编辑更新,
静态网页资源有几个重要的特征:
1.每个页面都有一个固定的URL地址,且URL一般以.htm、.html、 .shtml 等常见形式为后缀,而且地址中不含有问号"?" 或"&"等特殊字符。
2.网页内容一经发布到网站服务器上,无论是否有用户访问,每个网页的内容都是保存在网站服务器文件系统上的,也就是说,静态网页是实实在在保存在服务器上的文件实体,每个网页都是一个独立的文件
3.网页内容是固定不变的,因此,容易被搜索引擎收录(容易被用户找到)。
4.因为网页没有数据库的支持,所以在网站制作和维护方面的工作量较大,当网站信息量很大时,完全依靠静态网页比较困难
5.网页的交互性较差,在程序的功能实现方面有较大的限制
6.网页程序在用户浏览器端解析,由于服务器端不进行解析,并且不需要读取数据库,因此服务器端可以接受更多的并发访问。当客户端向服务器请求数据时,服务器会直接从磁盘文件系统上返回数据(不做任何解析),待客户端拿到数据后,在浏览器解析并展现出来
动态网页资源
1.动态网页资源介绍
一般在动态网页网址中会有标志性的符号------"?,&" ,此外,在大多数情况下后端都需要有数据库支持。
2.动态网页资源特点
网页扩展名后缀常见为: .asp、

 浙公网安备 33010602011771号
浙公网安备 33010602011771号