
仁者借力而行,先转高人概念介绍如下:
http://www.cnblogs.com/flowjacky/archive/2013/01/12/2857801.html
大数据:
简而言之,大数据是一个体量特别大,数据类别特别大的数据集。也就是说“大数据”本身并不是一种新的技术,也不是一种新的产品,
而是我们这个时代出现的一种现象。而这个“大”达到了一种什么样的程度呢?可以说他即将突破现有常规软件所能提供的能力极限。
综上所述,我们觉得使用麦肯锡的定义可能会更为简洁明了:大数据是指无法在一定时间内用传统数据库软件工具对其内容进行抓取、管理和处理的数据集合。
“大数据摩尔定律”:全球数据量大约每两年翻一番。
数据产生成本是符合反摩尔定律的,即数据产生成本大概每两年下降一半。
大数据将给我们带来什么样的难题?
无限增长的数据与有限增长的IT人员之间的矛盾
数据体量即将超越传统数据库的管理能力
经典数据库技术并没有考虑数据的多类别
IDC对大数据技术的定义:大数据技术将被设计用于在成本可承受的条件下,通过非常快速的采集、发现和分析,从大量化、多类别的数据中提取价值,将是IT
领域新一代的技术与架构。
NoSQL,指的是非关系型数据库,是一个用来处理半结构化和非结构化信息的数据平台,你可以把他简单理解为下一大数据库技术。
Hadoop,是Apache软件基金会所研发的开放源代码并行运算编程工具和分散式档案系统,你可以把他简单理解为下一代搜索引擎。
http://www.cnblogs.com/yangxudong/p/3736017.html
无论是大数据技术还是云计算技术,其实这些技术都不是突然冒出来的,而是随着互联网技术的发展,人们把现有的技术加以整合,总结,概括出来并冠一个 新名字。由于互联网行业的特殊性,这些新概括出来的名字被媒体过度炒作了。所以普通人完全不必要,因为自己不懂什么是大数据,不懂什么是云计算而感到惶惶 而不可终日。如果一个企业还不知道如何启动大数据处理,说明这个企业可能并不是十分迫切的需要大数据技术。
大数据技术是指对大规模数据的收集、分析、挖掘和应用的技术。数据的采集是大数据技术的第一步,是指通过某种方法或手段收集各种产生数据。举个例 子,比如说现在的互联网网站都有日志记录的功能,把用户在网站上的所有的行为,包括浏览点击购买等等,都记录下来。这样后台服务就能够分析用户的兴趣爱好 并为其推荐个性化的产品。再比如说气象部门会在城市的各个角落布置各种传感器,来采集气象数据。物流公司一般会跟踪采集物流数据,实时掌握物流信息。超市 会在后台的服务器上记录顾客的购买数据。总的来说,所有可能有价值的数据都会被采集,被数字化。数据的采集和记录只是第一步,并不是我们的最终目的。我们 的目的是分析数据的规律,挖掘数据的潜在价值,为决策提供依据,或者直接用到相应的产品或服务中。个人认为这就是大数据技术的核心。通过对数据的挖掘我们 可以知道啤酒和尿布这两件商品是可以捆绑在一起销售的,我们还可以知道某个具体的用户可能偏好什么样的商品,某个广告被点击的概率有多大,用户在一个具体 的场景下会有什么需求,一次贷款的风险有多高。我们甚至能够发现用户为了使得自己的商品在搜索结果中排名靠前使用了哪些作弊手段。这些是数据挖掘和机器学 习等技术的应用,也是发掘数据价值的关键手段。只有挖掘出数据的价值,数据的存在才变得有意义。数据挖掘工程师是大数据时代最紧缺的人才。数据价值体现在 于对其进行的应用。比如说各种可视化的报表,为企业高层的决策提供依据。用户和商品数据可以用来为用户提供个性化的推荐服务,缩短用户的查找路径,为用户 提供有效的信息。
大数据时代的一个问题是让人觉得自己没有隐私,完完全全地暴露在众人面前。你在互联网上的各种行为都会被记录下来,互联网企业可以知道你到底是男是 女,多大的年纪,有没有结婚,小孩有几岁,有没有车子,有没有买房,有没有孝敬父母的习惯,父母是多大的年纪,甚至你的老婆是谁,你的情人是谁,你的小三 是谁,你经常去哪些地方,你喜欢和谁联系,你和谁之间有过资金的交易,你每个月的收入是多少,你的消费习惯是什么样的,等等等等。可能你要问他们需要知道 我这些干什么呀?这就是为什么有的人打开微博或视频时会跳出美容护肤的广告,有的人会跳出成人用品的广告。如果企业对用户一无所知,那么用户看到的可能就 是千人一面了。但是企业对用户很了解,他们就能做到千人千面。
总之,大数据时代只会为人们带来更好的生活和服务,大数据现象是技术推动生产力进步的表现。大数据技术是人们利用数据的一种工具。劳动工具很大程度 上代表了社会生产力的水平。石器,铁器,铜器,蒸汽机,内燃机,手机,飞机等等是社会各个时期的代表工具。现在已经进入了大数据技术为代表的崭新时代。可 以展望未来只会有越来越多的数据和无处不再的计算。我们每个人都应该庆幸自己生在这样一个时代,我们都应该感谢互联网技术为我们的生活提供的点点滴滴的帮 助,随时拥有一颗感恩的心。
http://www.cnblogs.com/mdyang/archive/2011/08/22/why_mapreduce.html
mapReduce:
MapReduce的设计初衷:解决大规模、非实时数据处理问题。大规模决定数据有局部性特性可利用(从而可以划分)、可以批处理;非实时代表响应时间可以较长,有充分的时间执行程序。比如下面的几个操作:
1. 更新搜索引擎排序(在整个web图上执行PageRank算法)
2. 计算推荐(推荐结果并不需要实时更新,因此设定一个固定时间点周期性更新)
MapReduce的诞生有它的时 代背景:随着web的发展,尤其是SNS和物联网的发展,web上各种由用户、传感器产生数据量呈现出爆炸式的增长。数据存起来只能是死数据,唯有经过分 析处理,才能得到数据中蕴含的信息,进而从信息中总结知识。因此数据重要,处理数据的能力同样重要。传统的基于HPC集群的并行计算已经无法满足飞速增长 的数据处理需要,因此基于普通PC的低成本、高性能、高可扩展性、高可靠性的MapReduce应运而生。
传统的并行计算模型都有着与多线程 模型类似的逻辑,这种编程模型最大的问题是程序的行为难以控制。为了保证正确的执行结果,需要小心控制共享资源的访问,并由此发展出了互斥量、信号量、锁 等一系列同步技术,也带来了诸如争抢、饥饿、死锁等问题。程序员在使用传统并行计算模型编程时,不仅仅要考虑要做的事情(即“what to do”:使用并行模型描述需要解决的问题),还要考虑程序执行的细节(即“how to do”,程序执行中的诸多同步、通信问题),这使得并行编程十分困难。已有的编程模型,例如MPI、OpenCL、CUDA也只是在较低的层次做了封装, 需要处理的程序执行细节依然很多。
MapReduce则做了更多处 理:MapReduce不仅包含编程模型,还提供一个运行时环境,用以执行MapReduce程序,并行程序执行的诸多细节,如分发、合并、同步、监测等 功能均交由执行框架负责。使用MapReduce,程序员只需要考虑如何使用MapReduce模型描述问题(what),而无需操心程序是如何执行的 (how),这使得MapReduce易学易用。
引言
随着互联网数据量的不断增长,对处 理数据能力的要求也变得越来越高。当计算量超出单机的处理能力极限时,采取并行计算是一种自然而然的解决之道。在MapReduce出现之前,已经有像 MPI这样非常成熟的并行计算框架了,那么为什么Google还需要MapReduce,MapReduce相较于传统的并行计算框架有什么优势,这是本 文关注的问题。
文章之初先给出一个传统并行计算框架与MapReduce的对比表格,然后一项项对其进行剖析。
| 传统 | MapReduce | |
| 集群架构/容错性 | 共享式(共享内存/共享存储),容错性差 | 无共享式,容错性好 |
| 硬件/价格/扩展性 | 刀片服务器、高速网、SAN,价格贵,扩展性差 | 普通PC机(便宜),便宜,扩展性好 |
| 编程/学习难度 | what+how,难 | what,简单 |
| 适用场景 | 实时、细粒度计算、计算密集型 | 批处理、非实时、数据密集型 |
http://www.cnblogs.com/tekkaman/p/3298456.html
1、Google三宝:分别是03年SOSP的GFS,04年OSDI的MapReduce,和06年OSDI的BigTable
2、Hadoop实际上就是谷歌三宝的开源实现,Hadoop MapReduce对应Google MapReduce,HBase对应BigTable,HDFS对应GFS。HDFS(或GFS)为上层提供高效的非结构化存储服务,HBase(或 BigTable)是提供结构化数据服务的分布式数据库,Hadoop MapReduce(或Google MapReduce)是一种并行计算的编程模型,用于作业调度。
3、什么是MapReduce?
如果我想统计下过去10年计算机论文出现最多的几个单词,看看大家都在研究些什么,那我收集好论文后,该怎么办呢?
方法一:我可以写一个小程序,把所有论文按顺序遍历一遍,统计每一个遇到的单词的出现次数,最后就可以知道哪几个单词最热门了。
这种方法在数据集比较小时,是非常有效的,而且实现最简单,用来解决这个问题很合适。
方法二:写一个多线程程序,并发遍历论文。
这个问题理论上是可以高度并发的,因为统计一个文件时不会影响统计另一个文件。当我们的机器是多核或者多处理器,方法二肯定比方法一高效。但是写一个多线程程序要比方法一困难多了,我们必须自己同步共享数据,比如要防止两个线程重复统计文件。
方法三:把作业交给多个计算机去完成。
我们可以使用方法一的程序,部署到N台机器上去,然后把论文集分成N份,一台机器跑一个作业。这个方法跑得足够快,但是部署起来很麻烦,我们要人工把程序copy到别的机器,要人工把论文集分开,最痛苦的是还要把N个运行结果进行整合(当然我们也可以再写一个程序)。
方法四:让MapReduce来帮帮我们吧!
MapReduce本质上就是方法三,但是如何拆分文件集,如何copy程序,如何整合结果这些都是框架定义好的。我们只要定义好这个任务(用户程序),其它都交给MapReduce。
4、map函数和reduce函数
- map函数:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。
- reduce函数:接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
5、MapReduce函数如何工作?

上图是论文里给出的流程图。一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
- MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
- user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
- 被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
- 缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
- master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对 都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个 Reduce作业(谁让分区少呢),所以排序是必须的。
- reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
- 当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是 将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输 出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的 分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函 数,Reduce作业最终也对应一个输出文件。
http://www.cnblogs.com/npumenglei/p/3631244.html
Hadoop 越来越火, 围绕Hadoop的子项目更是增长迅速, 光Apache官网上列出来的就十几个, 但是万变不离其宗, 大部分项目都是基于Hadoop common
MapReduce 更是核心中的核心。那么到底什么是MapReduce, 它具体是怎么工作的呢?
关于它的原理, 说简单也简单, 随便画个图喷一下Map 和 Reduce两个阶段似乎就完了。 但其实这里面还包含了Sort, Partition, Shuffle, Combine, Merge等子阶段,尤其是Shuffle, 很多资料里都把它称为MapReduce的“心脏”, 和所谓“奇迹发生的地方”。真正能说清楚其中关系的人就没那么多了。可是了解这些流程对我们理解和掌握MapReduce 并对其进行调优是非常有用的。
本文名为详解, 其实笔者水平有限, 也就是结合自己的一些理解争取能够深入浅出地描述一下整个过程, 如有错误, 敬请指出。
首先我们看一副图, 包含了从头到尾的整个过程, 后面对所有步骤的解释都以此图作为参考 (此图100%原创)
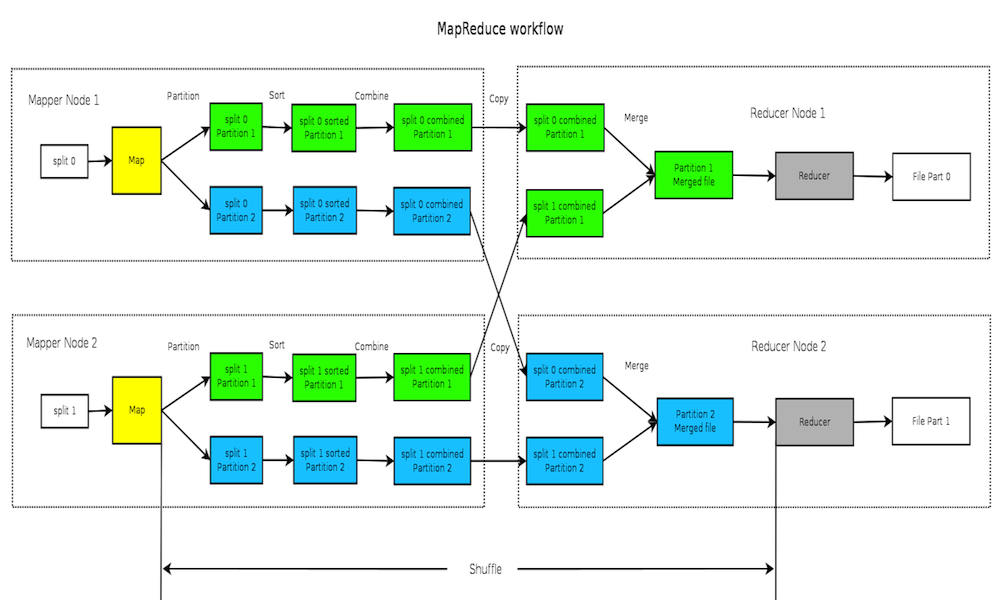
这张图简单来说, 就是说在我们常见的Map 和 Reduce 之间还有一系列的过程, 其中包括Partition, Sort, Combine, Copy, Merge等. 而这些过程往往被统称为"Shuffle" 也就是 “混洗”. 而Shuffle 的目的就是对数据进行梳理,排序,以更科学的方式分发给每个Reducer,以便能够更高效地进行计算和处理。 (难怪人家说这是奇迹发生的地方, 原来这里面有这么多花花, 能没奇迹么?)
如果您是Hadoop的大牛, 看了这幅图可能马上要跳出来了, 不对! 还有一个spill 过程云云...
且慢, 关于spill, 我认为只是一个实现细节, 其实就是MapReduce利用内存缓冲的方式提高效率, 整个的过程和原理并没有受影响, 所以在此处忽略掉spill 过程, 以便更好理解。
光看原理图还是有点费解是吧? 没错! 雷子一直认为, 没有例子的文章就是耍流氓 :) 所以我们就用大家都耳熟能详的WordCount 作为例子, 开始我们的讨论。
先创建两个文本文件, 作为我们例子的输入:

File 1 内容:
My name is Tony
My company is pivotal
File 2 内容:
My name is Lisa
My company is EMC
1. 第一步, Map
顾名思义, Map 就是拆解.
首先我们的输入就是两个文件, 默认情况下就是两个split, 对应前面图中的split 0, split 1
两个split 默认会分给两个Mapper来处理, WordCount例子相当地暴力, 这一步里面就是直接把文件内容分解为单词和 1 (注意, 不是具体数量, 就是数字1)其中的单词就是我们的主健,也称为Key, 后面的数字就是对应的值,也称为value.
那么对应两个Mapper的输出就是:
split 0
My 1
name 1
is 1
Tony 1
My 1
company 1
is 1
Pivotal 1
split 1
My 1
name 1
is 1
Lisa 1
My 1
company 1
is 1
EMC 1
2. Partition
Partition 是什么? Partition 就是分区。
为什么要分区? 因为有时候会有多个Reducer, Partition就是提前对输入进行处理, 根据将来的Reducer进行分区. 到时候Reducer处理的时候, 只需要处理分给自己的数据就可以了。
如何分区? 主要的分区方法就是按照Key 的不同,把数据分开,其中很重要的一点就是要保证Key的唯一性, 因为将来做Reduce的时候有可能是在不同的节点上做的, 如果一个Key同时存在于两个节点上, Reduce的结果就会出问题, 所以很常见的Partition方法就是哈希。
结合我们的例子, 我们这里假设有两个Reducer, 前面两个split 做完Partition的结果就会如下:
split 0
Partition 1:
company 1
is 1
is 1
Partition 2:
My 1
My 1
name 1
Pivotal 1
Tony 1
split 1
Partition 1:
company 1
is 1 is 1
EMC 1
Partition 2:
My 1
My 1
name 1
Lisa 1
其中Partition 1 将来是准备给Reducer 1 处理的, Partition 2 是给Reducer 2 的
这里我们可以看到, Partition 只是把所有的条目按照Key 分了一下区, 没有其他任何处理, 每个区里面的Key 都不会出现在另外一个区里面。
3. Sort
Sort 就是排序喽, 其实这个过程在我来看并不是必须的, 完全可以交给客户自己的程序来处理。 那为什么还要排序呢? 可能是写MapReduce的大牛们想,“大部分reduce 程序应该都希望输入的是已经按Key排序好的数据, 如果是这样, 那我们就干脆顺手帮你做掉啦, 请叫我雷锋!” ......好吧, 你是雷锋.
那么我们假设对前面的数据再进行排序, 结果如下:
split 0
Partition 1:
company 1
is 1
is 1
Partition 2:
My 1
My 1
name 1
Pivotal 1
Tony 1
split 1
Partition 1:
company 1
EMC 1
is 1 is 1
Partition 2:
Lisa 1
My 1
My 1
name 1
这里可以看到, 每个partition里面的条目都按照Key的顺序做了排序
4. Combine
什么是Combine呢? Combine 其实可以理解为一个mini Reduce 过程, 它发生在前面Map的输出结果之后, 目的就是在结果送到Reducer之前先对其进行一次计算, 以减少文件的大小, 方便后面的传输。 但这步也不是必须的。
按照前面的输出, 执行Combine:
split 0
Partition 1:
company 1
is 2
Partition 2:
My 2
name 1
Pivotal 1
Tony 1
split 1
Partition 1:
company 1
EMC 1
is 2
Partition 2:
Lisa 1
My 2
name 1
我们可以看到, 针对前面的输出结果, 我们已经局部地统计了is 和My的出现频率, 减少了输出文件的大小。
5. Copy
下面就要准备把输出结果传送给Reducer了。 这个阶段被称为Copy, 但事实上雷子认为叫他Download更为合适, 因为实现的时候, 是通过http的方式, 由Reducer节点向各个mapper节点下载属于自己分区的数据。
那么根据前面的Partition, 下载完的结果如下:
Reducer 节点 1 共包含两个文件:
Partition 1:
company 1
is 2
Partition 1:
company 1
EMC 1
is 2
Reducer 节点 2 也是两个文件:
My 2
name 1
Pivotal 1
Tony 1
Partition 2:
Lisa 1
My 2
name 1
这里可以看到, 通过Copy, 相同Partition 的数据落到了同一个节点上。
6. Merge
如上一步所示, 此时Reducer得到的文件是从不同Mapper那里下载到的, 需要对他们进行合并为一个文件, 所以下面这一步就是Merge, 结果如下:
Reducer 节点 1
company 1
company 1
EMC 1 is 2
is 2
Reducer 节点 2
Lisa 1
My 2
My 2 name 1
name 1 Pivotal 1 Tony 1
7. Reduce
终于可以进行最后的Reduce 啦...这步相当简单喽, 根据每个文件中的内容最后做一次统计, 结果如下:
Reducer 节点 1
company 2
EMC 1 is 4
Reducer 节点 2
Lisa 1
My 4 name 2 Pivotal 1 Tony 1
至此大功告成! 我们成功统计出两个文件里面每个单词的数目, 同时把它们存入到两个输出文件中, 这两个输出文件也就是传说中的 part-r-00000 和 part-r-00001, 看看两个文件的内容, 再回头想想最开始的Partition, 应该是清楚了其中的奥秘吧。
如果你在你自己的环境中运行的WordCount只有part-r-00000一个文件的话, 那应该是因为你使用的是默认设置, 默认一个job只有一个reducer
如果你想设两个, 你可以:
1. 在源代码中加入 job.setNumReduceTasks(2), 设置这个job的Reducer为两个
或者
2. 在 mapred-site.xml 中设置下面参数并重启服务
<property>
<name>mapred.reduce.tasks</name>
<value>2</value>
</property>
这样, 整个集群都会默认使用两个Reducer
http://blog.csdn.net/athenaer/article/details/8203990
前言:
前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了、学了很多东
西,收获颇丰。可是开学后,大家都忙各自的事情,云计算方面的动静都不太大。呵呵~不过最近在胡老大的号召下,我们云计算团队重振旗鼓了,希望大伙仍高举
“云在手,跟我走”的口号战斗下去。这篇博文就算是我们团队“重启云计算”的见证吧,也希望有更多优秀的文章出炉。汤帅,亮仔,谢总•••搞起来啊!
呵呵,下面我们进入正题,这篇文章主要分析以下两点内容:
目录:
1.MapReduce作业运行流程
2.Map、Reduce任务中Shuffle和排序的过程
正文:
1.MapReduce作业运行流程
下面贴出我用visio2010画出的流程示意图:

流程分析:
1.在客户端启动一个作业。
2.向JobTracker请求一个Job ID。
3.将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存
放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job
ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这
个作业启动多少个map任务等信息。
4.JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度(这里是不是很像微机中的进程调度呢,呵呵),当作业调度器
根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和
reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便
便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的
TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考
虑数据本地化。
5.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,
比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状
态时,它将得知任务已完成,便显示一条消息给用户。
以上是在客户端、JobTracker、TaskTracker的层次来分析MapReduce的工作原理的,下面我们再细致一点,从map任务和reduce任务的层次来分析分析吧。
2.Map、Reduce任务中Shuffle和排序的过程
同样贴出我在visio中画出的流程示意图:

流程分析:
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出
的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的
80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免
有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后
对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两
个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,
这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父
TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信
息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中
(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据
量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号