

Spider 爬虫
今天把爬虫整理出来:
现在已从移动互联网时代过渡到大数据时代,大数据的核心就是数
据,数据的获取途径主要有以下几种:
(1)企业生产的用户数据:大型互联网公司有海量的用户,他们
积累数据有天然的优势,比如百度指数、阿里指数、新浪微博指数等。
(2)数据管理咨询公司:通常只有大的公司才有数据采集团队,
根据市场调研、问卷调查、样板检测和各行各业的公司进行合作等方
式,进行数据的采集和基类。
(3)政府/机构的公开数据:政府开放的数据都是根据各地上报的
数据进行合并的,比如中华人民共和国国家统计局数据等。
(4)第三方数据平台购买数据:现在人工智能需要用到很多人脸
数据,行为动作都需要大量的数据,也有专门的平台购买,比如贵阳大
数据交易所等
-
HTTP & HTTPS
- 在百度的首页https://www.baidu.com/中,URL的开头都会有http或者https,这就是访问资源需要的协议类型,当然还有其他开头的URL,在爬虫中经常抓取的页面通常都是httphuozhehttps协议
- HTTP 中文叫做<超文本传输协议>,HTTP协议是用于从网络传输超文本数据到客户端本地浏览器的传送协议,
- HTTPS 是以安全为目标的HTTP管道,就是HTTP下的SSl层 简称HTTPS
-
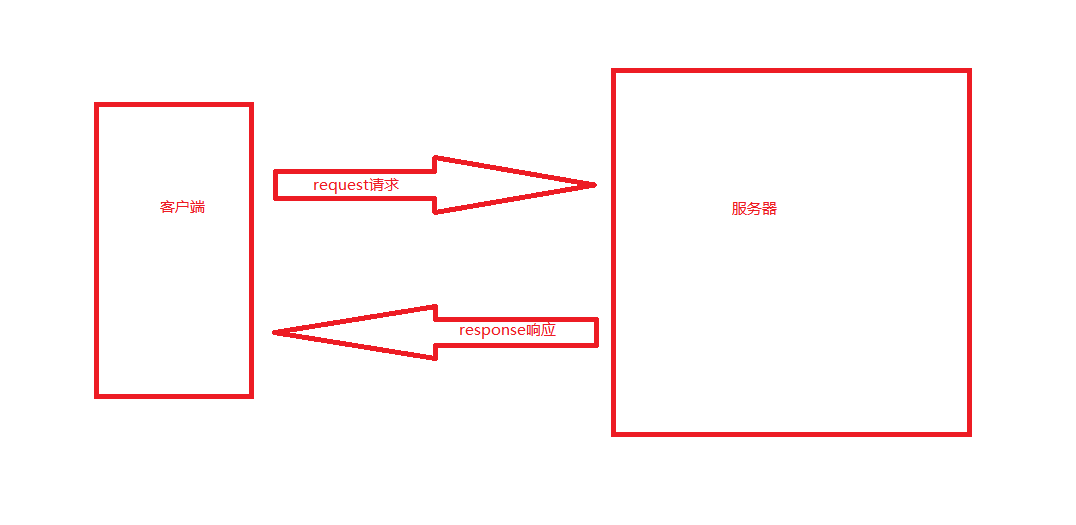
HTTP请求过程
-
当我们在浏览器上输入一个URL 回车之后就会得到相应的内容,这个过程就是浏览器向服务器发送了一个请求,网站服务器接收请求后 对该请求进行处理和解析然后返回相应的数据给浏览器,响应里包含了页面的源代码,浏览器进行解析后 便呈现在客户眼前
-
-
请求
-
请求,由客户端向服务端发出,可以分为四个部分
-
-
请求方法<request method>
- 请求方法常见的有两种GET\POST<在浏览器输入url并回车就发送了一个请求>
- POST请求中的参数包含在url中,数据可以再url中看到,而POST请求的url不会包含数据因为数据都通过表单形式传输的不在url中;另外一个就是GET请求提交的数据最多只有1024字节,而POST没有限制
-
请求的网址<request url>
- 请求的网址 就是唯一可以确定想要请求的资源
-
请求头<request hearders>
- 请求头 就是说明服务器要使用的附加信息 比如Cookie.User-Agent等
-
请求体<request body>
-
请求体的内容一般都是POST请求中的表单数据
-
-
-
-
响应状态码
-
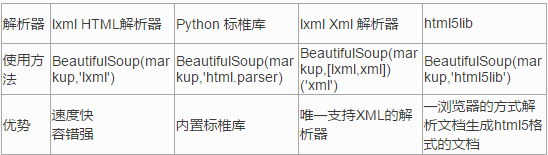
自动化爬虫之selenium
- selenium是一个web应用程序测试的工具,直接运行在浏览器中,就像真正的用户操作一样,支持的浏览器包括IE.chrome等,
但是不管在使用任何浏览器的时候都必须下载一个对应的浏览器驱动<就是webdriver> - selenium driver对象操作
- get(url) 就是传入访问的地址
- close() 关闭浏览器窗口
- quit() 退出当前的webdriver并关闭所有窗口
- current_url 获取当前页面的url
- selenium是一个web应用程序测试的工具,直接运行在浏览器中,就像真正的用户操作一样,支持的浏览器包括IE.chrome等,

end.....

梦想就是确认目标后无微不至的努力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号