

linux三剑客grep,sed,awk学习
此文章为B站视频https://www.bilibili.com/video/BV1rA4y1S7Hk的个人记录版,方便以后自己回来复习,如果不对请多多见谅。
概述
三剑客有各自的领域:
grep:擅长查找功能
sed:擅长编辑
awk:擅长取列
1、正则表达式
正则表达式:Regual Expression ,由一类特殊字符及文本字符所编写的模式,其中有些字符不表示其字面意义,而是用于表达控制或通配的功能。
正则表达式的意义:通过特殊字符的辅助,可以快速过滤、替换、处理所需的字符串、文本,让工作效率更加高效。
:正则表达式以行为单位进行工作,一次处理一行。
普通正则表达式:
| 符号 | 作用 |
| ^ | 用于模式的最左侧,匹配以设置字符开头的行。如"^我是小萌新",则是匹配以我是小萌新开头的行 |
| $ | 用于模式的最右侧,匹配以设置字符结尾的行。如"$我是小萌新",则是匹配以我是小萌新结尾的行 |
| ^$ | 表示空行 |
| . | 匹配除了空行外的任意有且只有一个字符 |
| \ | 转义字符,屏蔽正则表达式中字符的特殊含义,如\.表示小数点 |
| * | 匹配前一个字符(连续出现)0次或1次以上,重复0次为空,即匹配所有内容 |
| .* | 匹配所有 |
| ^.* | 匹配以任意多个字符开头的行 |
| .*$ | 匹配以任意多个字符结尾的行 |
| [abcd]或[a-d] | 匹配集合内的任意一个字符,a或b或c或d |
| [^abcd] | 匹配除了集合内的任意字符 |
| \w(\w) | 匹配字母或数字或下划线或汉字(匹配不是字母、数字、下划线、汉字的字符) |
| \s(\S) | 匹配空白符(匹配不是空白行的字符) |
| \d(\D) | 匹配数字(匹配不是数字的字符) |
| \b(\B) | 匹配单词的开始或结束(匹配不是单词开头或结尾的单词) |
扩展正则表达式:
对于grep而言扩展正则表达式必须用grep -E 才能生效;sed必须使用sed -r才能生效,
| 字符 | 作用 |
| + | 匹配一个字符1次或多次 |
| [:/]+ | 匹配[]一内的:或/字符1次或多次 |
| ? | 匹配前一个字符0次或1次 |
| | | 表示或者,同时过滤多个字符串 |
| () | 分组过滤,被括起来的内容为一个整体 |
| a(n,m) | 匹配a最少n次,最多m次 |
| a(n,) | 匹配a最少n次 |
| a(n) | 匹配a正好n次 |
| a(,m) | 匹配a最多m次 |
2、grep
grep全拼:Global search Regular expression and Print out the line
作用,文本搜索工具,根据用户指定的条件对目标文本进行匹配检查并打印匹配的行。
语法:
grep [options ] [pattern] file
语法 参数 匹配模式 文本
| 参数 | 作用 |
| -v | 排除匹配结果,即显示不被匹配到的行 |
| -n | 显示匹配行与行号 |
| -i | 忽略大小写 |
| -c | 只统计匹配到的行数 |
| -E | 使用egrep命令 |
| --color=auto | 为匹配的字符串添加颜色 |
| -w | 只匹配过滤的单词 |
| -o | 只输出匹配的内容 |
| -q | --quite,静默模式,即不输出任何内容 |
3、sed
注意:sed和awk使用单引号,双引号有特殊的解释。
sed是Stream Editor (字符流编辑器)的缩写,简称流编辑器。
sed是操作、过滤和转换文本内容的强大工具。
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。
sed工作流程图:
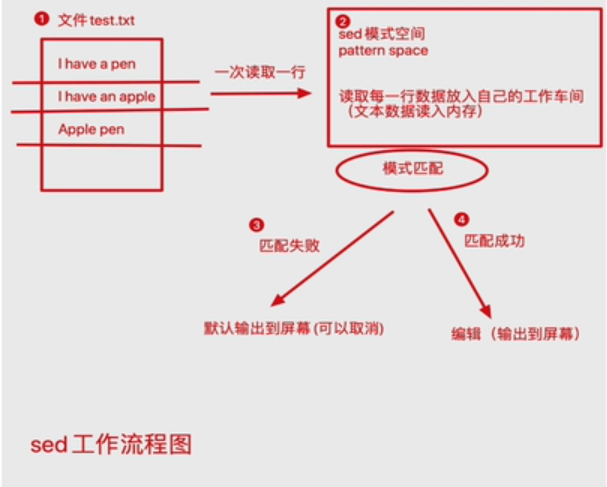
sed语法及其常用参数:
语法:sed [选项] [sed内置命令符] [文件]
| 参数 | 解释 |
| -n | 取消sed默认输出(默认输出:无论是不是匹配项都输出,即像cat一样把文本内容打印出来),常与sed内置命令p一起使用 |
| -i | 直接将修改结果写入文件,不用-i,sed修改的是内存数据而不是修改源文件 |
| -e | 多次编辑,不再需要管道符了 |
| -r | 制成正则扩展 |
sed常用内置命令符:
| sed内置命令符 | 解释 |
| a | append,对文本进行追加,在指定行后添加一行或多行文本 |
| d | delete,删除匹配行 |
| i | insert,插入文本,在指定行后添加一行或多行文本 |
| p | print,打印匹配行的内容,p与-n通常一起使用 |
| s/正则/替换内容/g | 匹配正则内容,然后替换内容,结尾g表示全局匹配 |
sed匹配范围:
| 范围 | 解释 |
| 空地址 | 全文处理 |
| 单地址 | 指定文件某一行 |
| /pattern/ | 被模式匹配到的每一行 |
| 范围区间 | 10,20表示10~20行;10,+5第10行向下5行;/pattern1/,/pattern2/ |
| 步长 | 1~2表示1,3,5,7奇数行,2~2表示2,4,6,8偶数行 |
sed案例演示:
演示文本:test.txt,里边是一些自己导入的信息
1、显示文本的第2,3行内容:
如果是:sed "2,3p" test.txt,发现系统打印整个文件的内容:(我这里有个173行的测试文件使用这条语句无法打印出内容,不知道机子内存太小还是sed输出有限制)
root@VM-12-13-debian:/# sed "2,3p" test.txt PID TTY TIME CMD 1376691 pts/1 00:00:00 bash 1376691 pts/1 00:00:00 bash 1396054 pts/1 00:00:00 ps 1396054 pts/1 00:00:00 ps
这是因为sed默认把内容打印出来,而想要只输出2,3行需要加参数-n取消sed默认输出:
root@VM-12-13-debian:/# sed "2,3p" test.txt -n 1376691 pts/1 00:00:00 bash 1396054 pts/1 00:00:00 ps
2、打印文本的2~5行
第一种方法:sed "2,5p" test,txt -n root@VM-12-13-debian:/tmp# sed "2,6p" test.txt -n 1067176 pts/0 00:00:00 bash 1083172 pts/0 00:00:00 ps Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:sshdd 0.0.0.0:* LISTEN 第二种方法:sed "2,+3p" test.txt -n root@VM-12-13-debian:/tmp# sed "2,+3p" test.txt -n 1067176 pts/0 00:00:00 bash 1083172 pts/0 00:00:00 ps Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State
3、打印含有State的行:(和grep “State” test.txt 结果一致)
root@VM-12-13-debian:/tmp# sed -n "/State/p" test.txt Proto Recv-Q Send-Q Local Address Foreign Address State Proto RefCnt Flags Type State I-Node Path
4、删除含有State的行:
sed "/State/d" test.txt -n
但是再在test.txt文本组查找State字符串发现依旧存在:
root@VM-12-13-debian:/tmp# sed -n "/State/p" test.txt Proto Recv-Q Send-Q Local Address Foreign Address State Proto RefCnt Flags Type State I-Node Path
这是因为sed会把文本内容一行一行读取到内存中进行操作,修改的是内存中的数据,如果需要对源文件进行修改需要加-i(-i.bak表示备份源文件并对源文件进行修改)参数:
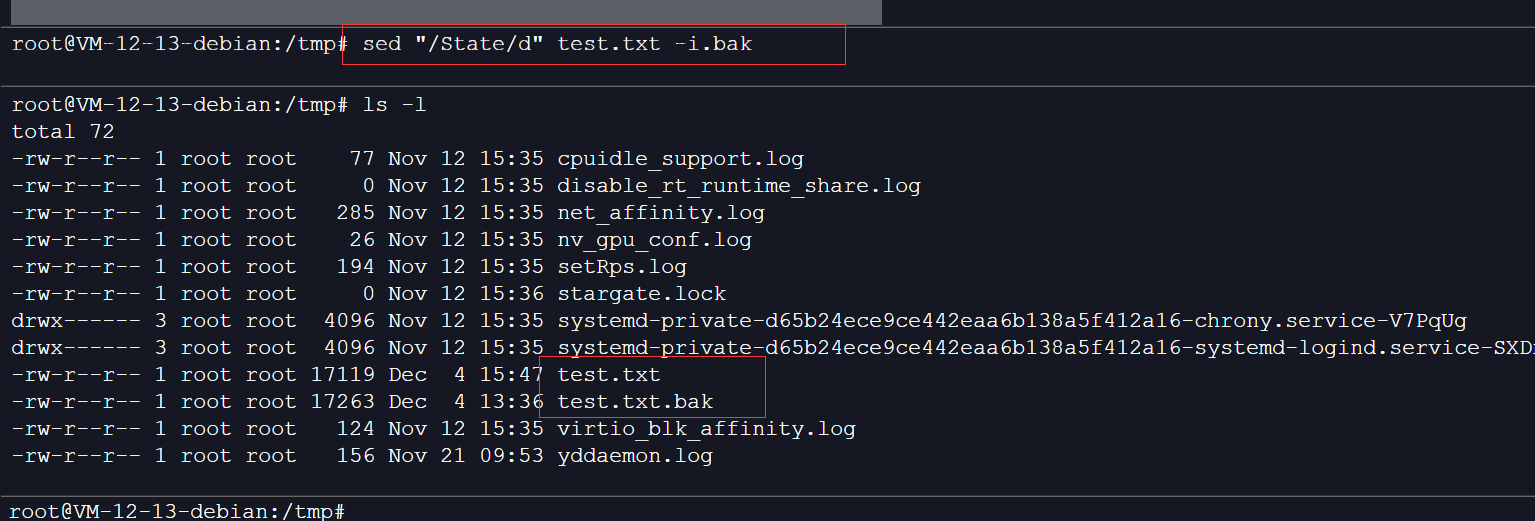
再查询时States所在的行已经被删除:

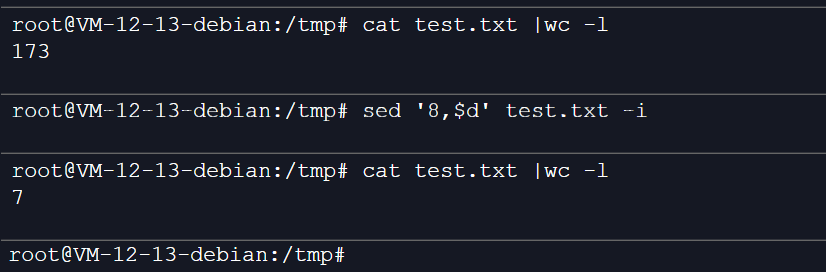
5、删除8(指定行)到结尾的行:
root@VM-12-13-debian:/tmp# sed '8,$d' test.txt PID TTY TIME CMD 1067176 pts/0 00:00:00 bash 1083172 pts/0 00:00:00 ps Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:sshdd 0.0.0.0:* LISTEN tcp 0 0 localhost:postgresql 0.0.0.0:* LISTEN
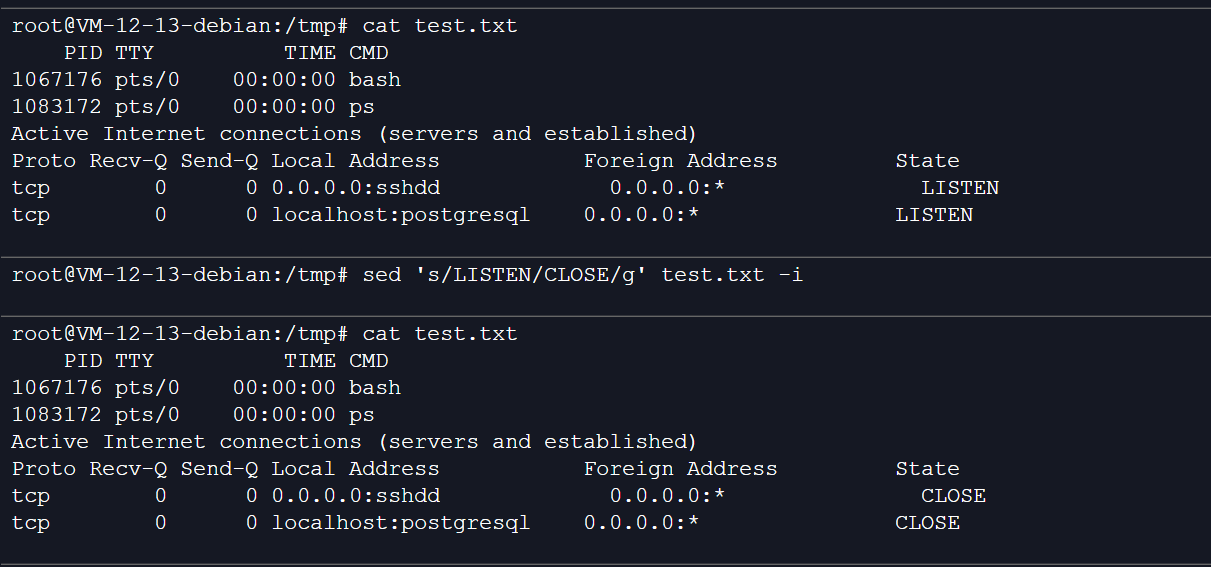
6、将文件中的LISTEN替换为CLOSE:
语法:sed 's/旧内容/新内容/g' filename -i //s,g为sed内置符,s为search查找,g为global全局
sed 's/LISTEN/CLOSE/g' test.txt -i
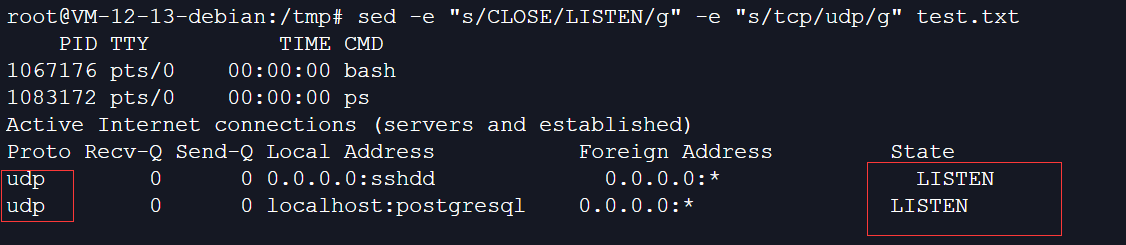
7、将文件中的CLOSE替换为LISTEN以及tcp替换为usp:
sed -e "s/CLOSE/LISTEN/g" -e "s/tcp/udp/g" test.txt
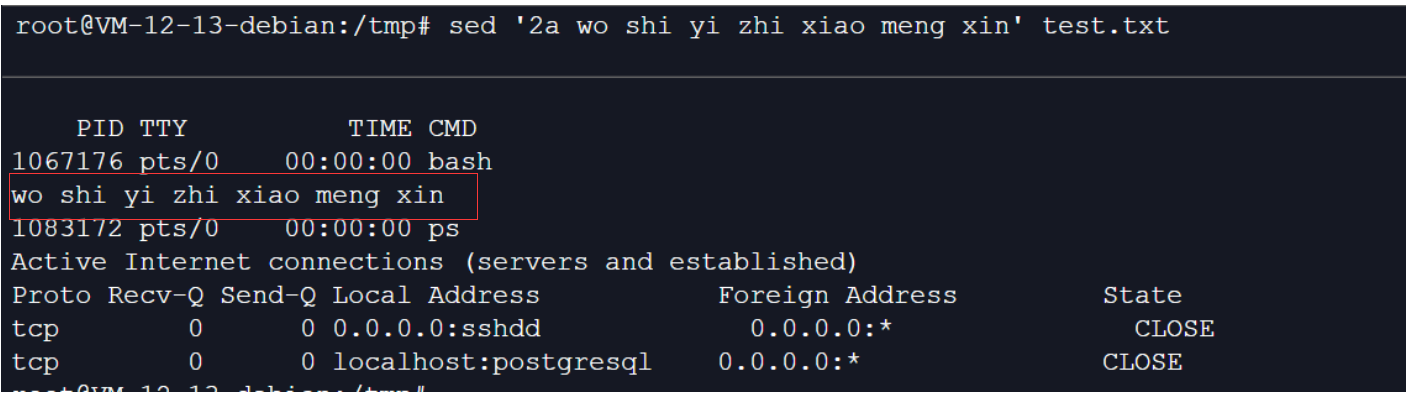
8、在文件中的第二行之后追加一行数据
sed '2a wo shi yi zhi xiao meng xin' test.txt
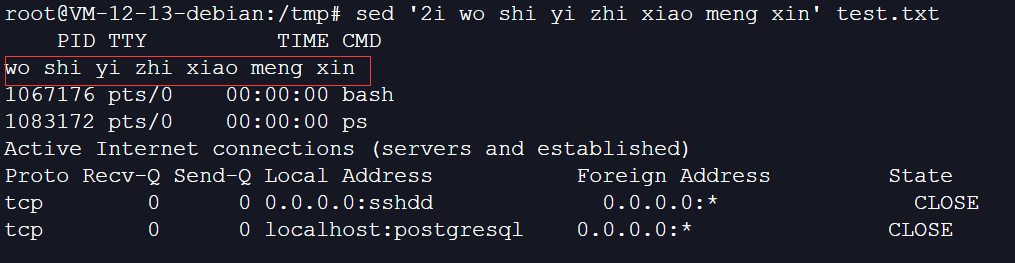
9、在第2行之前添加一行数据:
10、在第4行后追加多行数据(利用\n)

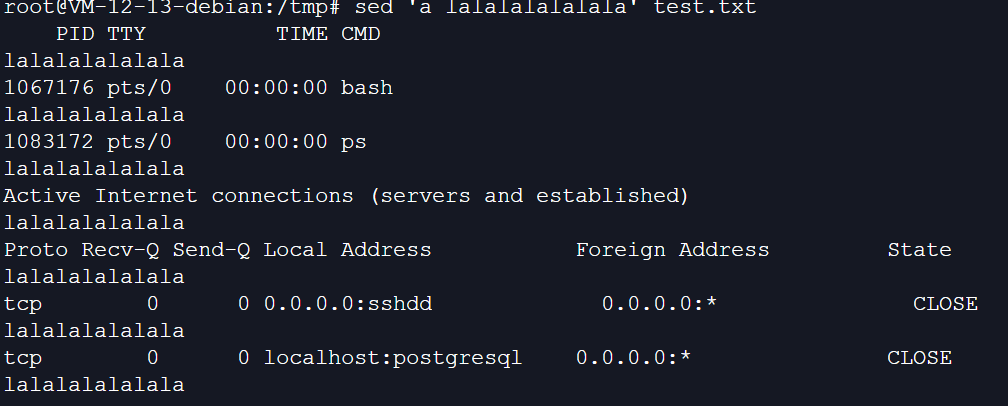
11、在每一行的后边加一行数据(不指定范围则默认为全文):
4、awk
awk具有强大的文本格式化能力,好比将一些数据故事化为专业的excel表的样式。
awk更是一门编程语言,支持判断、循环、数组等功能。

awk基础
awk语法:awk [option] 'pattern{action}' file
awk 参数 模式{动作} file
awk擅长文本格式化且输出格式化后的结果,一次最常用的动作是print和printf。
awk内置变量含义:
| 变量 | 解释 |
| $0 | 表示一整行信息 |
| $1 | 表示一行中的表示第一列 |
| $2 | 表示一行中的第二列 |
| $n | 表示一行中的第n列 |
| $NF | 表示一行中的最后一列,倒数第二列可以表示为$(NF-1) |
| FS | 字段分隔符,默认是空格 |
| NF(Number of fields) | 分割后,当前行有一共多少个字段 |
| NR(Number of records) | 当前记录数,行数 |
| OFS | 输出字段分割符,默认为空白字符 |
| FS | 输入字段分割符,默认为空白字符 |
| ORS | 输出换行符,输出时用指定符号代替换行符 |
| RS | 输入换行符,指定输入时的换行符 |
| awk man | 更多变量及其详细信息查看手册 |
| FNR | 各文件分别计数的行号 |
| FILENAME | 当前文件名 |
| ARGD | 命令行参数的个数 |
| ARGV | 数组,保存着命令行给定的各参数 |
awk参数:
| 参数 | 解释 |
| -F | 指定分割符 |
| -v | 定义或修改一个awk内部的变量 |
| -f | 从脚本文件中读取awk命令 |
实例:
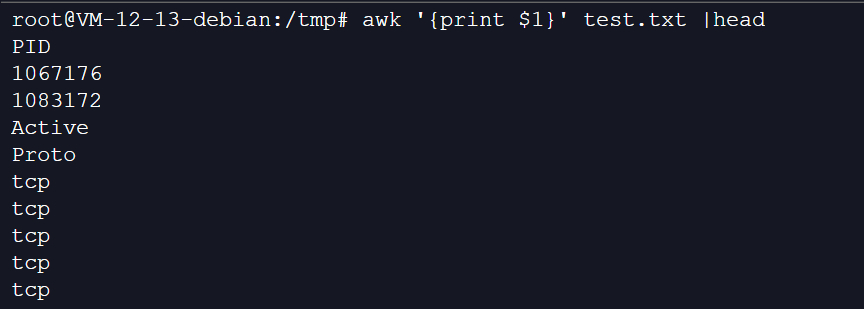
1、打印文中数据的第一列:
awk '{print $1}' test.txt
//awk '{print $0}' test.txt==awk '{print}' test.txt-->$0表示一整行的信息,语句相当于打印全文数据,即cat test.txt
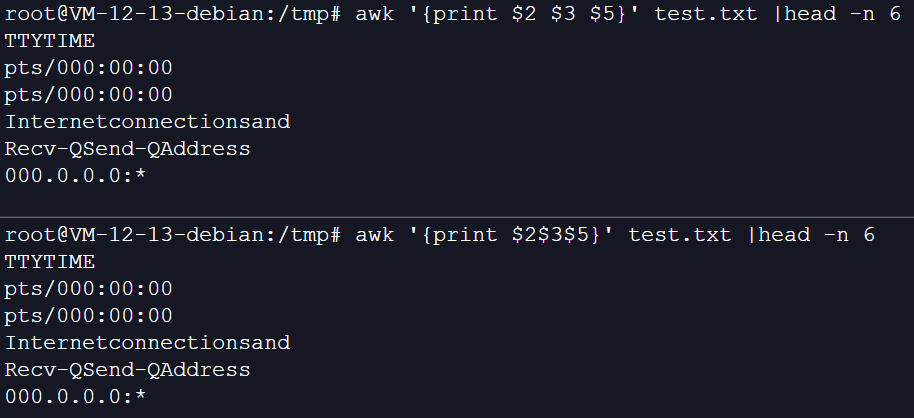
2、打印2,3,5列
如果使用:
awk '{print $2$3$5}' test.txt |head或是awk '{print $2 $3 $5}' test.txt |head
发现输出的数据没有分隔符,可观看性极差:
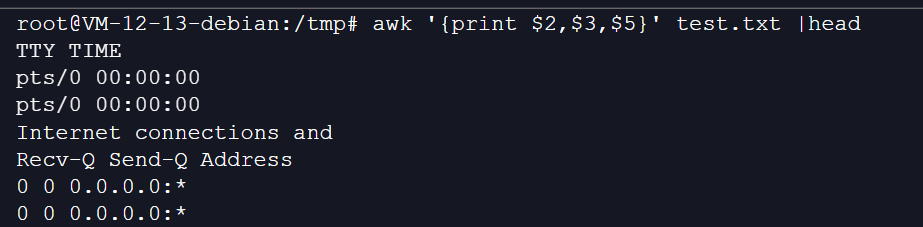
此时可以在列数之间加逗号,系统会将打印的数据以空格为分隔符:
awk '{print $2,$3,$5}' test.txt |head
3、自定义输出内容
此时必须外层单引号,内层双引号;但是内置变量$2,$3不能添加双引号,否则会被认为是单纯的字符:
awk '{print "第一列数据"$2,"第二列数据"$3}' test.txt |head -n 6

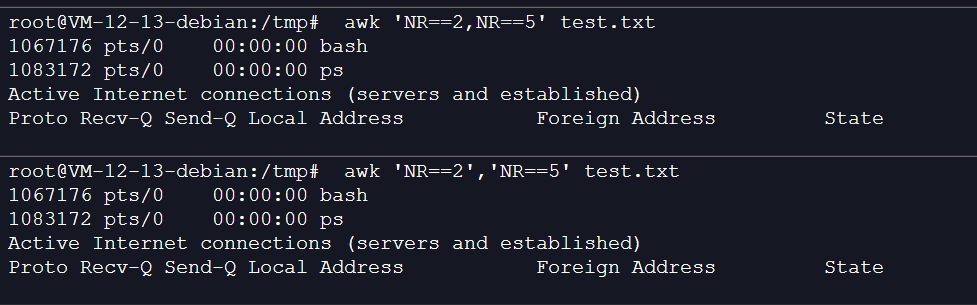
4、显示文件指定行
NR在awk中表示行号,NR==5表示行号是5的那一行,NF为一行中的列数,$NF为最后一列
需要注意:一个等号(=)为赋值,两个等号才是关系运算符(==)
awk 'NR==5' test.txt

awk 'NR==2','NR==5' test.txt 或awk 'NR==2,NR==5' test.txt//输出2~5行
5、打印行号

6、输入分割符及输出分割符的修改
awk有两个分割符,一为输入分割符(变量为PF,也可以使用-F指定),二为输出分割符(变量为OFS)
awk在处理文本时,以输入分隔符为准,把文本切成多个片段,默认符号时空格。同时我们也可以使用-F指定分割符。
awk -F ":" '{print $1}' test.txt |head -n 5 //也可以为 awk -v PF=":" ":" '{print $1}' test.txt |head -n 5
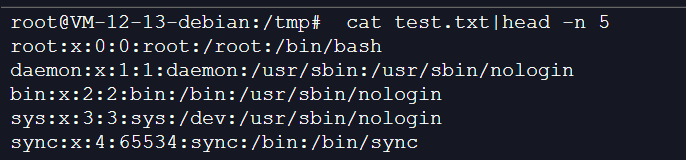

以"----------"进行输出分割:
awk -F ":" -v OFS="------" '{print $1,$2}' test.txt |head -n 5

7、未完待续

 浙公网安备 33010602011771号
浙公网安备 33010602011771号