


(一)os模块:
os模块提供了多数操作系统的功能接口函数。当os模块被导入后,它会自适 应于不同的操作系统平台,根据不同的平台进行相应的操作,在python编 程时,经常和文件、目录打交道,所以离不了os模块。
os模块中常见的方法:
os.getcwd()获取当前执行命令所在目录
os.path.isfile()判断是否文件
os.path.isdir() #判断是否是目录
os.path.exists() #判断文件或目录是否存在
os.listdir(dirname) #列出指定目录下的目录或文件
os.path.split(name) #分割文件名与目录
os.path.join(path,name) #连接目录与文件名或目录
os.mkdir(dir) #创建一个目录
os.rename(old,new) #更改目录名称
os.remove() 删除文档
(2)re模块
一、re正则匹配基本介绍
正则匹配:使用re模块实现
1、什么是正则表达式?
正则表达式是一种对字符和特殊字符操作的一种逻辑公式,从特定的字符中,用正则表达字符来过滤的逻辑。
2、正则表达式是一种文本模式;
3、正则表达式可以帮助我们检查字符是否与某种模式匹配
4、re模块使pyhton语言用有全部的表达式功能
5、re表达式作用?
(1)快速高效查找和分析字符比对自读,也叫模式匹配,比如:查找,比对,匹配,替换,插入,添加,删除等能力。
(2)实现一个编译查看,一般在处理文件时用的多
二、认识正则表达式中的特殊元素?
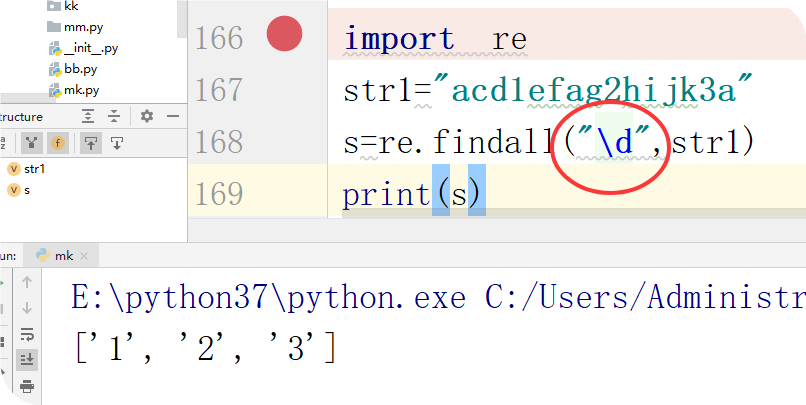
\d:数字0-9
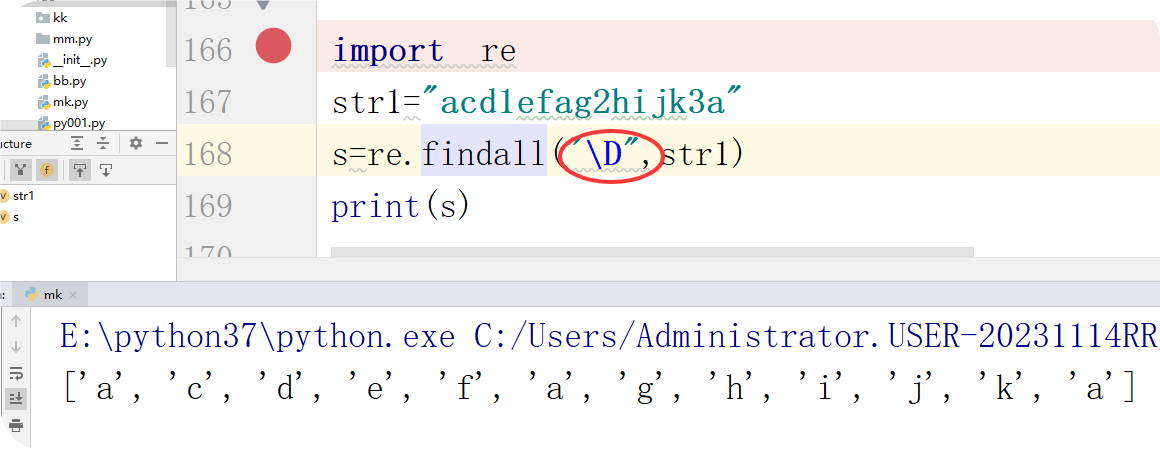
\D:非数字
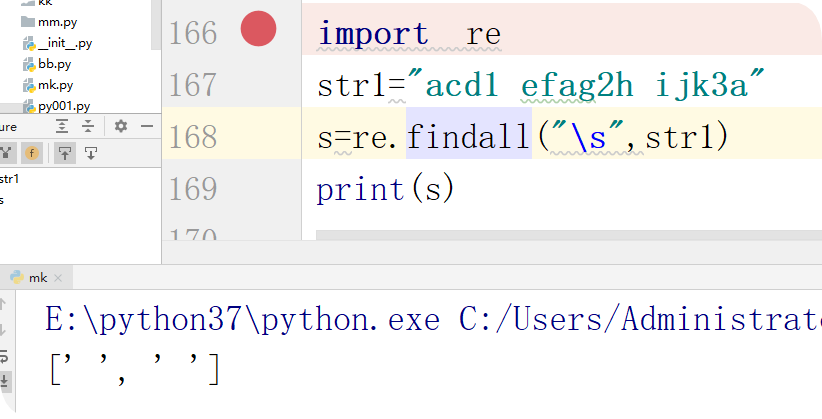
\s:空白字符
\n:换行符
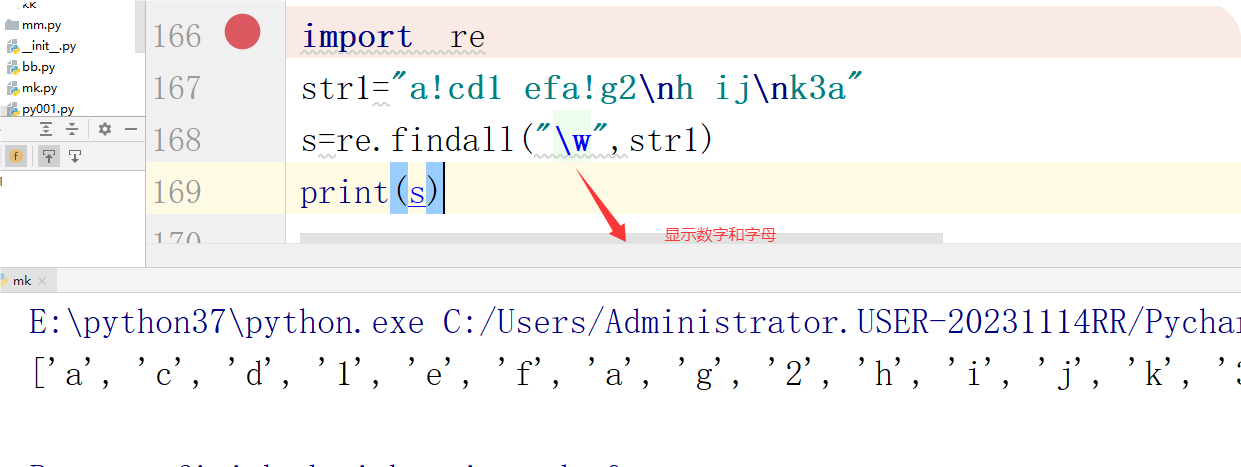
\w 匹配字母数字
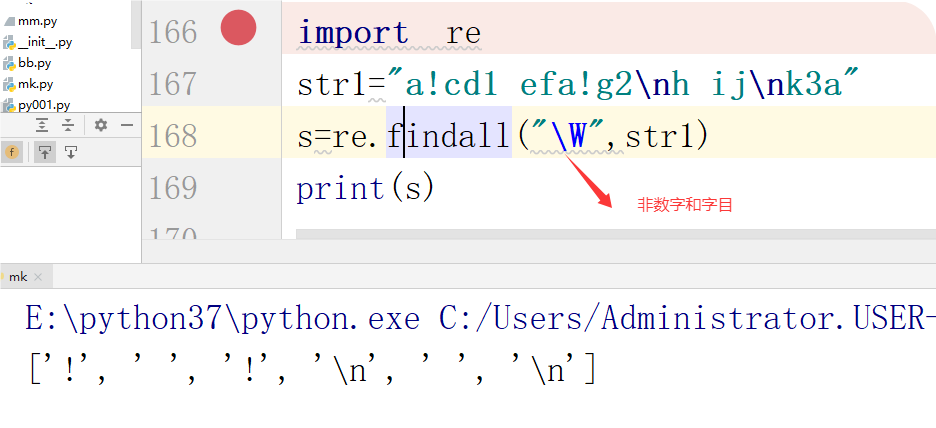
\W 匹配非字母数字
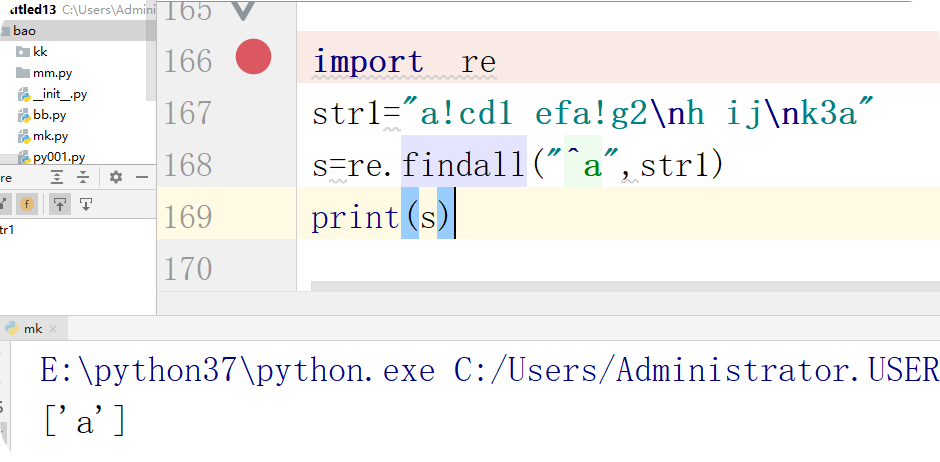
^:表示的匹配字符以什么开头
$:表示的匹配字符以什么结尾
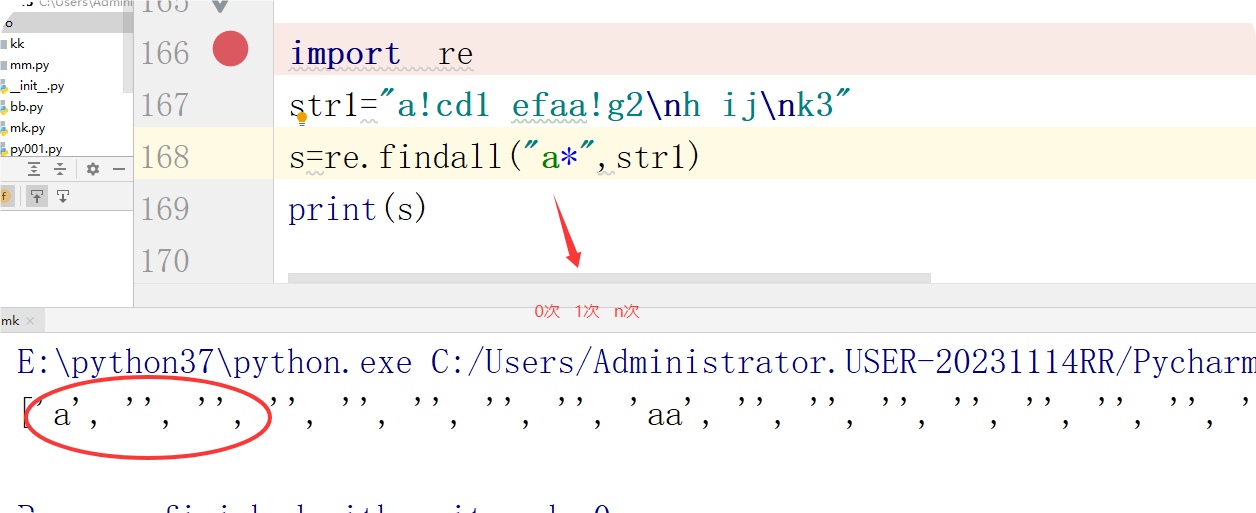
:匹配前面的字符0次或n次 eg:ab (* 能匹配a 匹配ab 匹配abb )
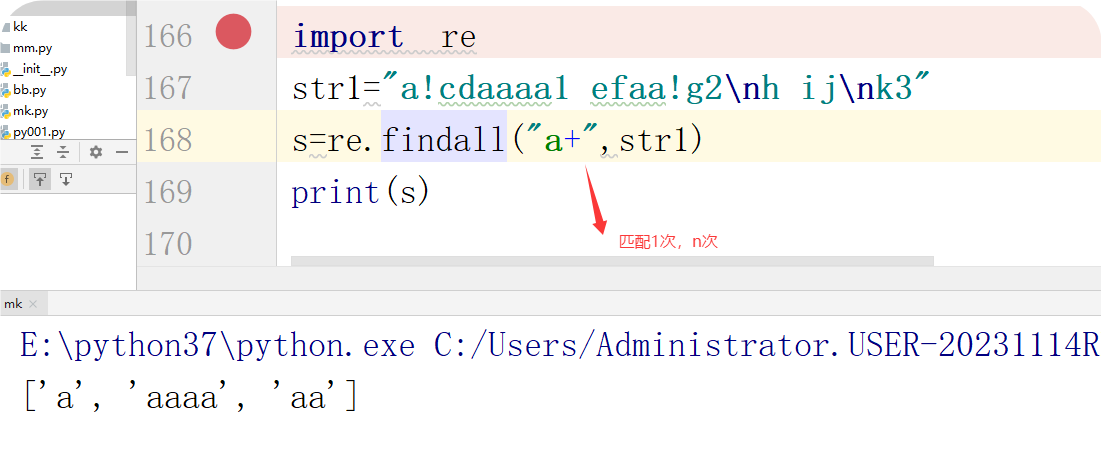
+:匹配+前面的字符1次或n次
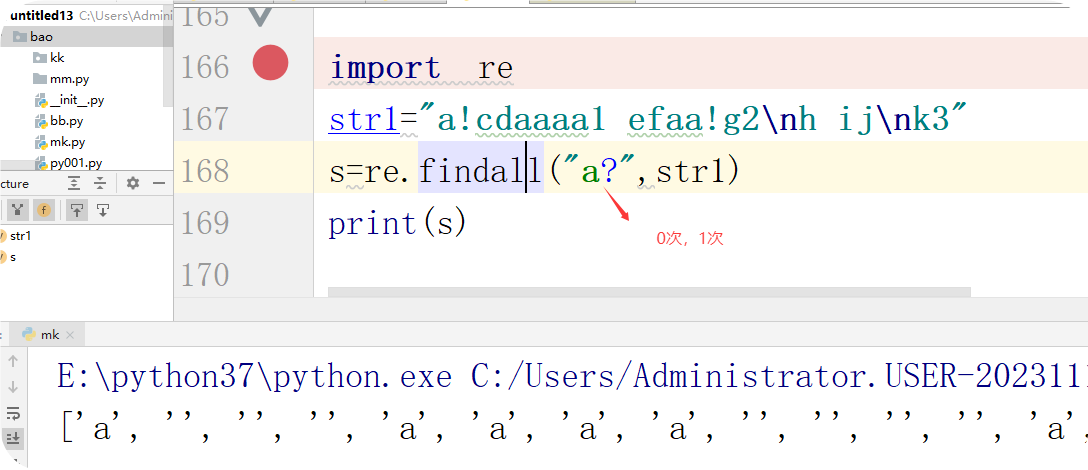
?:匹配?前面的字符0次或1次
{m}:匹配前一个字符m次
{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
1、findall
从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个空列表[]
2、match
从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败得到一个none值
注意:如果规则带了’+’,则匹配1次或者多次,无’+'只匹配一次
3、compile(不考虑)
编译模式生成对象,找到全部相关匹配为止,找不到返回一个列表[]
4、search
从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则报错
============================
group 以str 形式返回对象中match元素
span 以tuple形式返回范围
====================================
实战案例:
场景一、findall
从第一个字符开始查找,找到全部相关匹配为止,找不到返回一个空列表[]
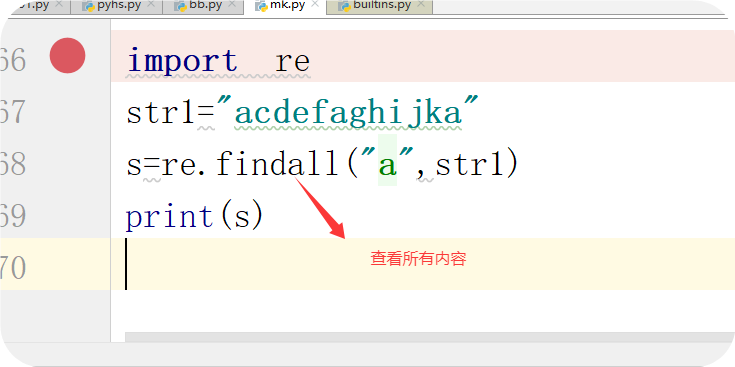
(1)第一种情况查找字符汇总存在的字符
import re # 导入re模块
import re
str1="acdefaghijka"
s=re.findall("a",str1)
print(s)
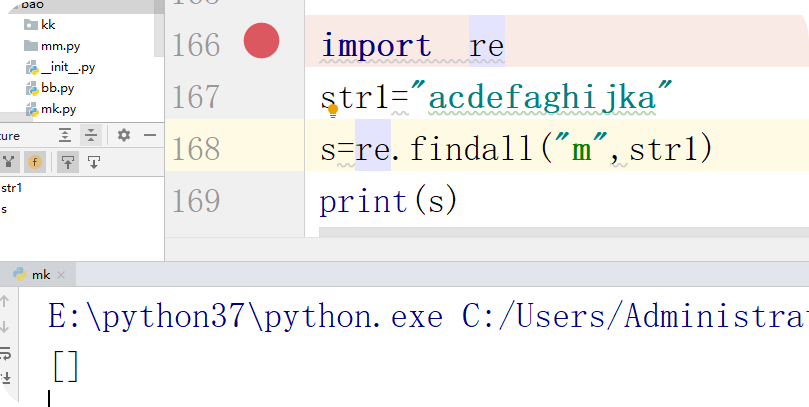
(2)第二种情况查找不存在的字符
显示的是一个空了列场景
import re
str1="acdefaghijka"
s=re.findall("m",str1)
print(s)
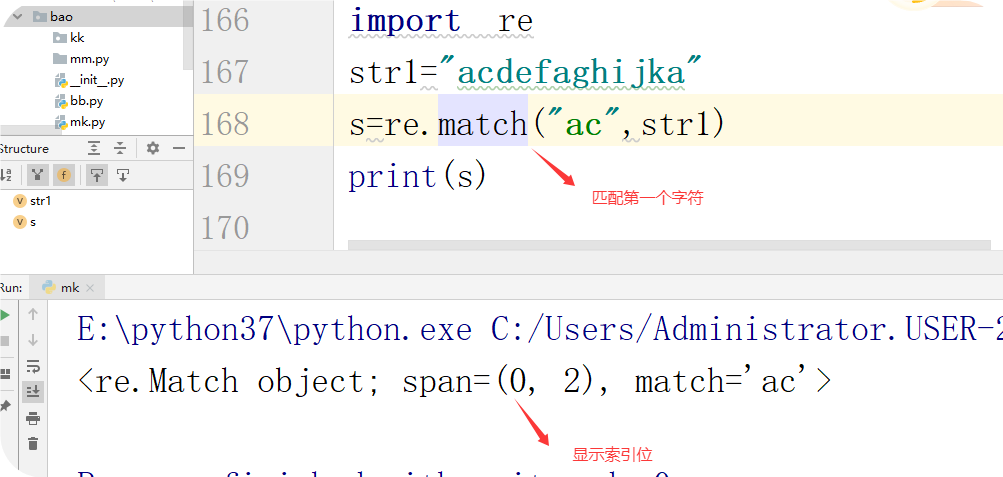
二、match 匹配开头
从第一个字符开始匹配,如果第一个字符不是要匹配的类型、则匹配失败得到一个值就报错
第一种情况:开头是匹配的是存在的字符
import re # 导入re模块
s=‘anbdckk12356afjmba’
c=re.match(‘a’,s)
print(c.span()) #显示结果是索引位:(0, 1)
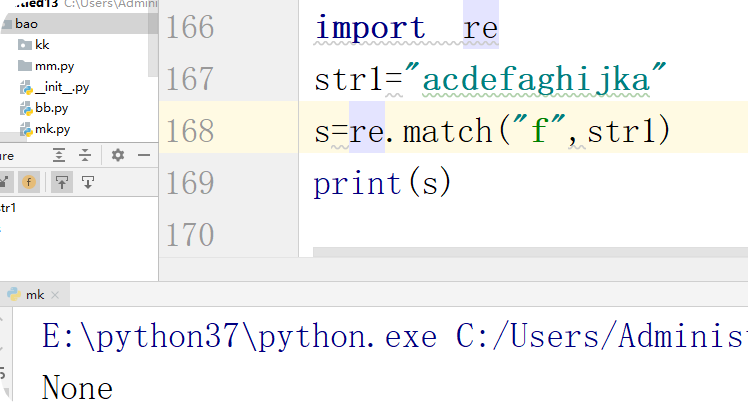
第二种情况:开头匹配的是不存在字符
import re
str1="acdefaghijka"
s=re.match("f",str1)
print(s)
场景三、search
从第一个字符开始查找、一找到就返回第一个字符串,找到就不往下找,找不到则None
第一种情况:查看的字符存在,返回字符的索引位
import re # 导入re模块
import re
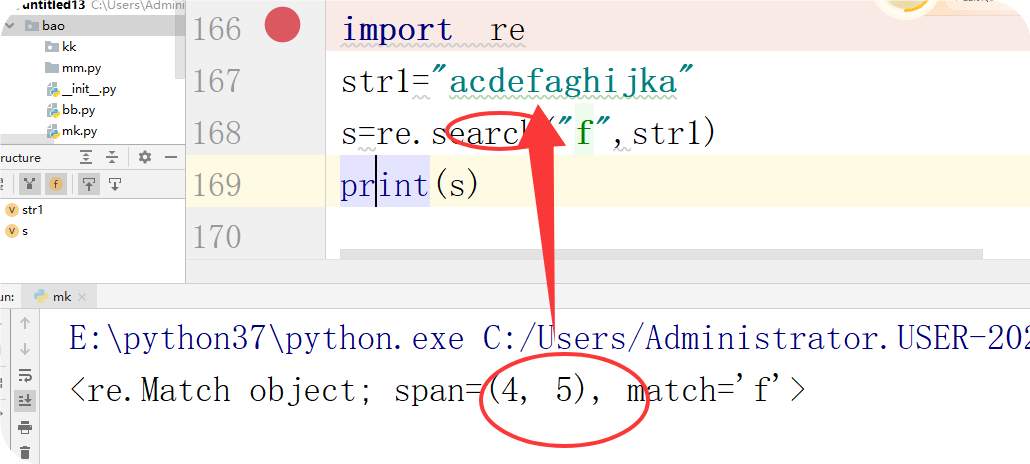
第二种情况:查看的字符不存在,返回字符的是none
import re # 导入re模块

-=========
re正则 字符集匹配

d:数字0-9
\D:非数字
\s:空白字符
\n:换行符
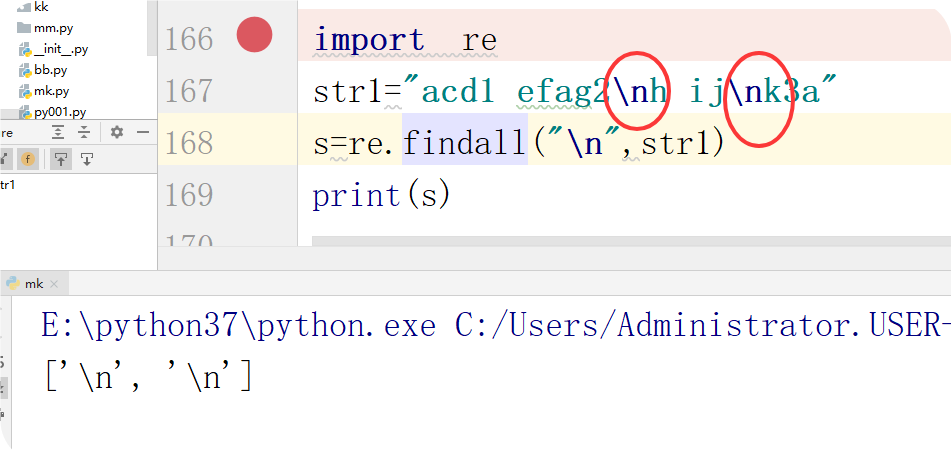
\w 匹配字母数字
\W 匹配非字母数字
^:表示的匹配字符以什么开头
$:表示的匹配字符以什么结尾
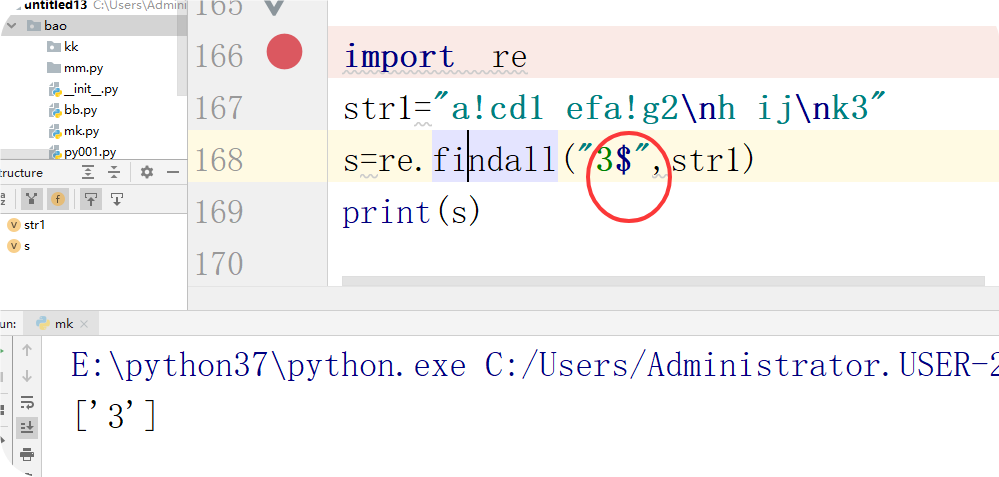
*:匹配前面的字符0次或n次 eg:ab (* 能匹配a 匹配ab 匹配abb )
+:匹配+前面的字符1次或n次
?:匹配?前面的字符0次或1次
{m}:匹配前一个字符m次

{m,n}:匹配前一个字符m到n次(包括n次),m或n可以省略,mn都是
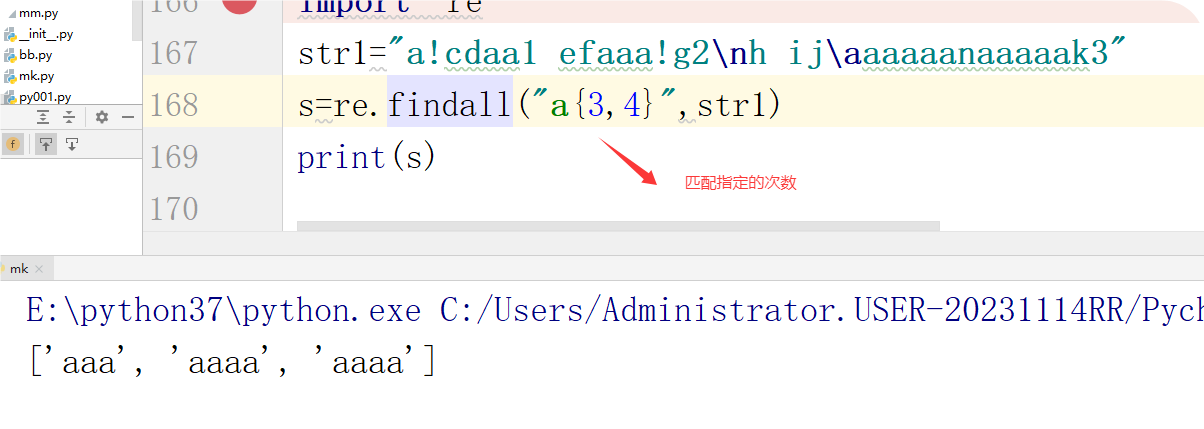
re 标识符:
flags=标识符
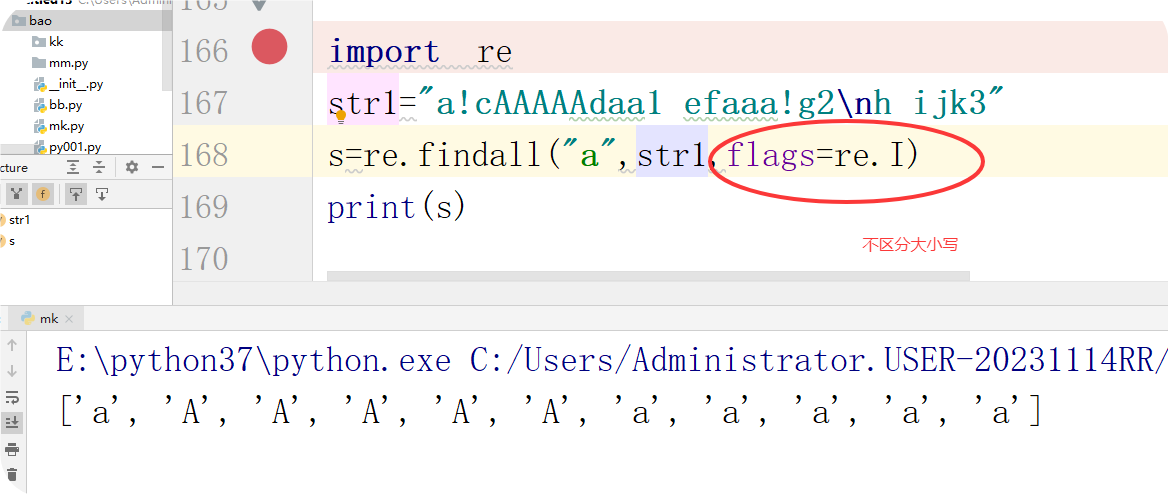
(1)re.I(大写的i) 不区分大小写
import re # 导入re模块
import re
str1="a!cAAAAAdaa1 efaaa!g2\nh ijk3"
s=re.findall("a",str1,flags=re.I)
print(s)
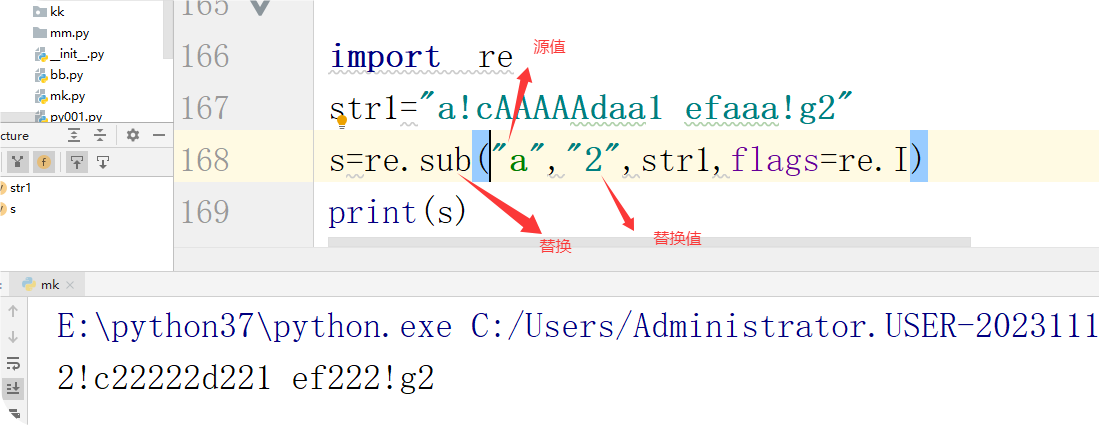
sub 替换
import re # 导入re模块
import re
str1="a!cAAAAAdaa1 efaaa!g2"
s=re.sub("a","2",str1,flags=re.I)
print(s)
================================
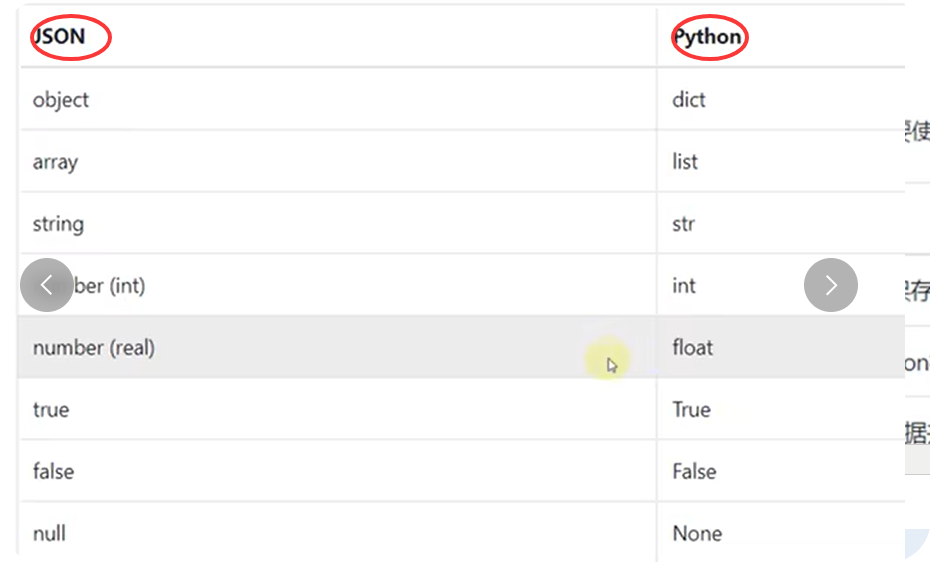
python标准模块之json
定义:json (java script object notation)是轻量级的文本数据交换格式
案例json:
json和字典 一样
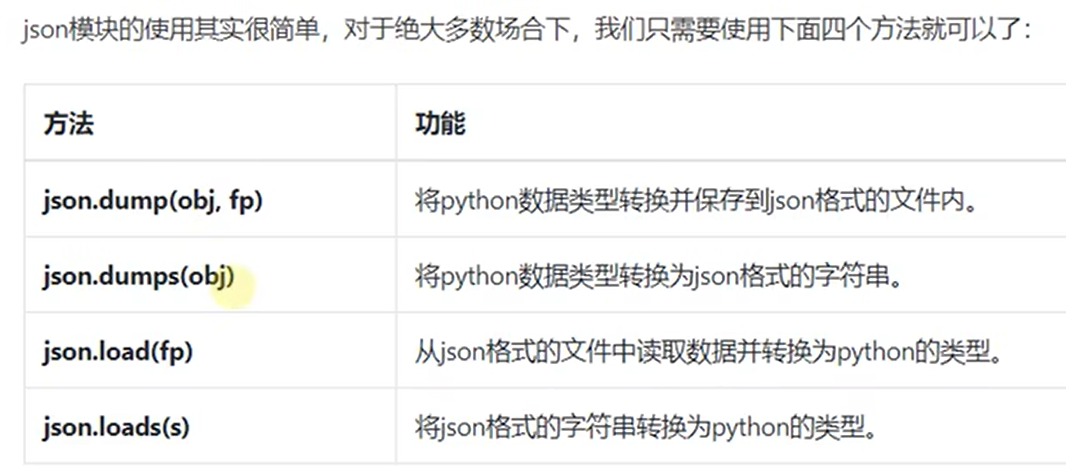
一、json模块可以实现json数据的序列化和反序列化
(1)序列化:将可存放在内存中的python 对象转换成可物理存储和传递的形式
实现方法:load() loads()
(2)反序列化:将可物理存储和传递的json数据形式转换为在内存中表示的python对象
实现方法:dump() dumps()
查看 dump用法:ctrl+点击dump
1、由python对象格式化成为json()dumps()
案例1:将字典格式转化字符
import json
d1={"name":"zs","age":18}
print(type(d1)) #<class 'dict'>
print(d1) #{'name': 'zs', 'age': 18}
js=json.dumps(d1)
print(type(js)) #<class 'str'>
print(js) #{"name": "zs", "age": 18}
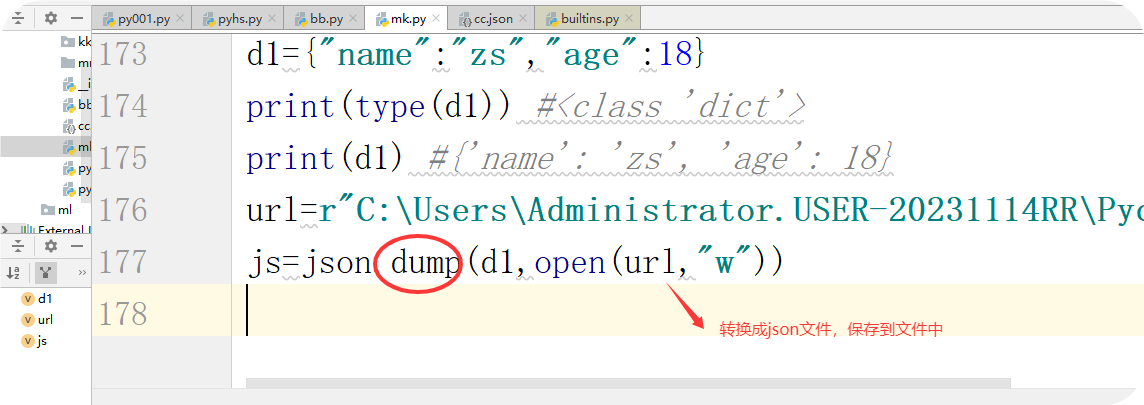
(2)通过dump转换成json格式保存在文档中
import json
d1={"name":"zs","age":18}
print(type(d1)) #<class 'dict'>
print(d1) #{'name': 'zs', 'age': 18}
url=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled13\bao\cc.json"
js=json.dump(d1,open(url,"w"))
(3)loads 将josn类型转换成python类型
json1='{"name":"zs","age":18}'
print(type(json1)) #<class 'str'>
d=json.loads(json1)
print(type(d)) #<class 'dict'>
print(d) #{'name': 'zs', 'age': 18}
(4)load 将文件中的json格式转换成python类型
# json1='{"name":"zs","age":18}'
url=r"C:\Users\Administrator.USER-20231114RR\PycharmProjects\untitled13\bao\cc.json"
js=open(url,"r",encoding="utf-8")
print(type(js.read())) #<class 'str'>
js1=json.load(open(url,"r",encoding="utf-8"))
print(type(js1)) #<class 'dict'>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号