

Pandas-DataFrame
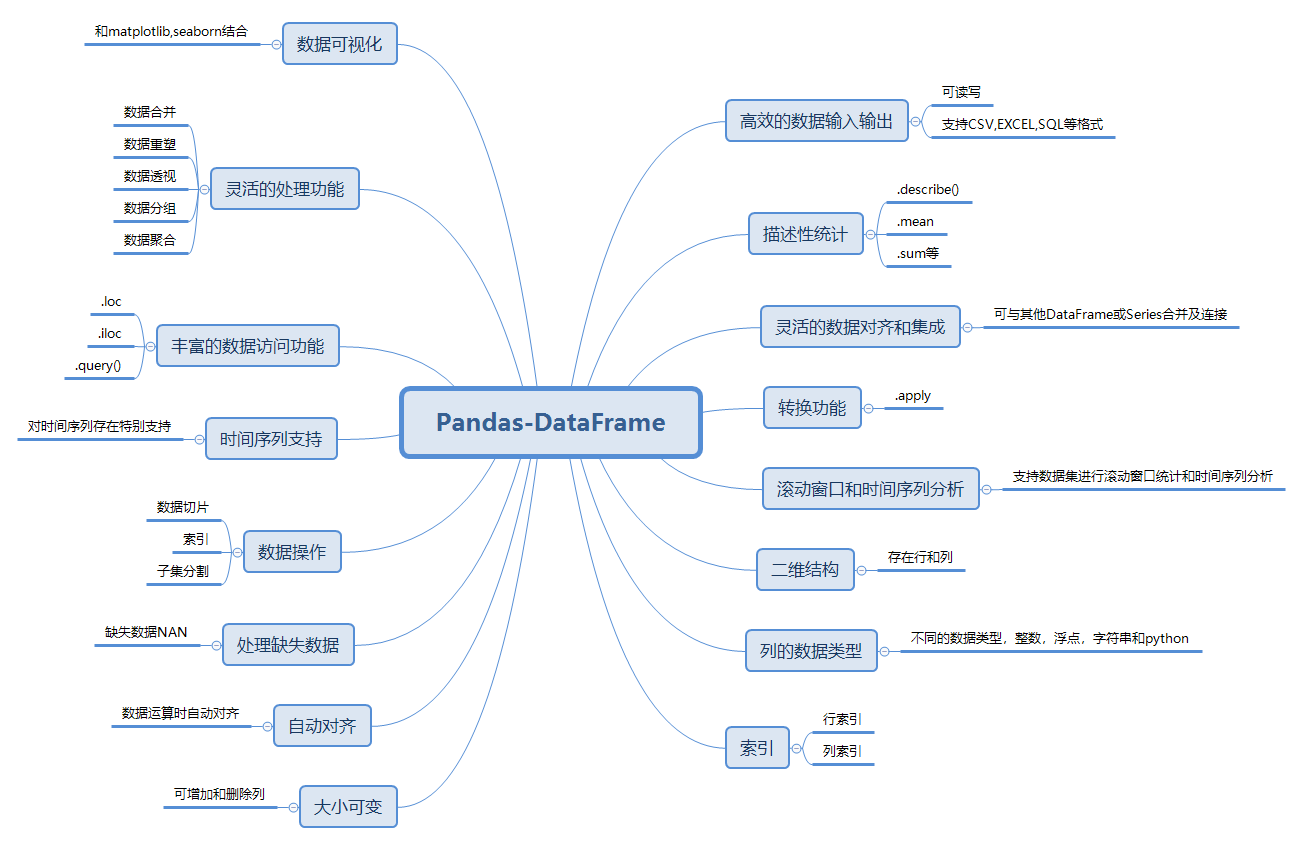
一、Pandas-DataFrame特点
二、特征练习
# 从列表嵌套字典创建DataFrame
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print(df)
print('-----------')
# 从字典创建DataFrame
data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]}
df = pd.DataFrame(data, index=['s1','s2','s3','s4'])
print(df)
print('-----------')
# 从字典创建DataFrame
data = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(data)
print(df)
print('-----------')
#从数组中读取数据
data=[['zhaosan',12],['lisi',15],['wangwu',19]]
df=pd.DataFrame(data,columns=['name','age'])
print(df)
print('-----------')
a b c
0 1 2 NaN
1 5 10 20.0
-----------
Name Age
s1 Tom 28
s2 Jack 34
s3 Steve 29
s4 Ricky 42
-----------
one two
a 1.0 1
b 2.0 2
c 3.0 3
d NaN 4
-----------
name age
0 zhaosan 12
1 lisi 15
2 wangwu 19
-----------
执行结果
data={
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston']
}
df=pd.DataFrame(data)
# 查看前两行数据
print(df.head(2))
print("-----------------")
# 查看 DataFrame 的基本信息
print(df.info())
print("-----------------")
# 获取描述统计信息
print(df.describe())
print("-----------------")
# 按年龄排序
df_sorted = df.sort_values(by='Age', ascending=False)
print(df_sorted)
print("-----------------")
# 选择指定列
print(df[['Name', 'Age']])
print("-----------------")
# 按索引选择行
print(df.iloc[1:3]) # 选择第二到第三行(按位置)
print("-----------------")
# 按标签选择行
print(df.loc[:2]) # 选择第二到第三行(按标签)
print("-----------------")
# 计算分组统计(按城市分组,计算平均年龄)
print(df.groupby('City')['Age'].mean())
print("-----------------")
# 处理缺失值(填充缺失值)
df.loc[2,'Age']=None
print(df)
print("-----------------")
df['Age'] = df['Age'].fillna(30)
print(df)
print("-----------------")
# 导出为 CSV 文件
df.to_csv('output.csv', index=False)
执行结果:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
-----------------
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 4 non-null object
1 Age 4 non-null int64
2 City 4 non-null object
dtypes: int64(1), object(2)
memory usage: 224.0+ bytes
None
-----------------
Age
count 4.000000
mean 32.500000
std 6.454972
min 25.000000
25% 28.750000
50% 32.500000
75% 36.250000
max 40.000000
-----------------
Name Age City
3 David 40 Houston
2 Charlie 35 Chicago
1 Bob 30 Los Angeles
0 Alice 25 New York
-----------------
Name Age
0 Alice 25
1 Bob 30
2 Charlie 35
3 David 40
-----------------
Name Age City
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
-----------------
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
-----------------
City
Chicago 35.0
Houston 40.0
Los Angeles 30.0
New York 25.0
Name: Age, dtype: float64
-----------------
Name Age City
0 Alice 25.0 New York
1 Bob 30.0 Los Angeles
2 Charlie NaN Chicago
3 David 40.0 Houston
-----------------
Name Age City
0 Alice 25.0 New York
1 Bob 30.0 Los Angeles
2 Charlie 30.0 Chicago
3 David 40.0 Houston
-----------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号