

pandas-Series
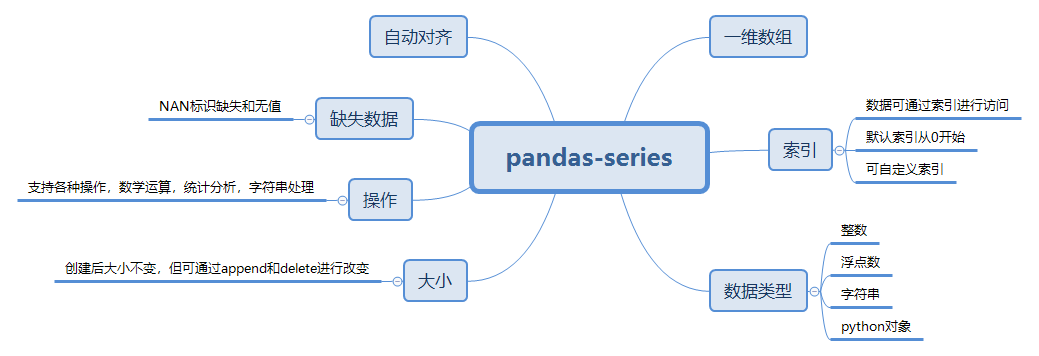
一、Series特点
二、特点练习
import pandas as pd
import numpy as np
#pandas---Series
#默认索引从0开始且数组类型数据
data=np.array(['张三','李四','王五','赵六'])
s=pd.Series(data)
print(s)
#自定义索引
s=pd.Series(data,index=['100','101','102','103'],name='series_name')
print(s)
#字典类型数据
data={'S100':'张三','S101':'李四','S102':'王五','S103':'赵六',}
s=pd.Series(data)
print(s)
#数字类型数据
s=pd.Series(5,index=[0,1,2,3])
print(s)
#默认索引从0开始且数组类型数据
data=[12,13,14,11,16]
df=pd.Series(data)
#查看基本信息
print("索引:", df.index)
print("数据:", df.values)
print("数据类型:", df.dtype)
print("前两行数据:", df.head(2))
#对数据进行处理
#使用map函数将每个元素加倍
df_s=df.map(lambda x:x*2)
print(df_s)
#计算累计和
df_sum=df.cumsum()
print(df_sum)
#输出空值
print(df.isnull())
#对数据排序
df_sort=df.sort_values()
print(df_sort)
df=pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])
print(df[2]) #索引为2的值
print(df['b']) #索引名称为b的值
print(df[1:4]) #索引切片形式读取
#读取series序列种的索引及值
for index ,value in df.items():
print(index,value)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号