Python机器学习笔记(6)—DBscan聚类—DBSCAN
一、内容大纲
1,算法原理
2,数据模型
二、算法原理
为了解决K均值聚类对于异常值的处理不够精细的问题,使用了DBscan的算法,通过对参数的设置查找异常值;
2.1 参数
eps:密度阀值
min_samples:每一类最小个数
三、数据模型
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
数据预处理,该处使用的是链家的售房信息,具体数据集合可网络下载
data1 = pd.read_csv('datasets/lianjia/lianjia1.csv',encoding = 'gbk')
data2 = pd.read_csv('datasets/lianjia/lianjia2.csv',encoding = 'gbk')
data3 = pd.read_csv('datasets/lianjia/lianjia3.csv',encoding = 'utf-8')
data4 = pd.read_csv('datasets/lianjia/lianjia4.csv',encoding = 'utf-8')
data5 = pd.read_csv('datasets/lianjia/lianjia5.csv',encoding = 'utf-8')
data6 = pd.read_csv('datasets/lianjia/lianjia6.csv',encoding = 'utf-8')
data7 = pd.read_csv('datasets/lianjia/lianjia7.csv',encoding = 'utf-8')
data = pd.concat([data1,data2,data3,data4,data5,data6,data7])
data = data.dropna()
data.head()
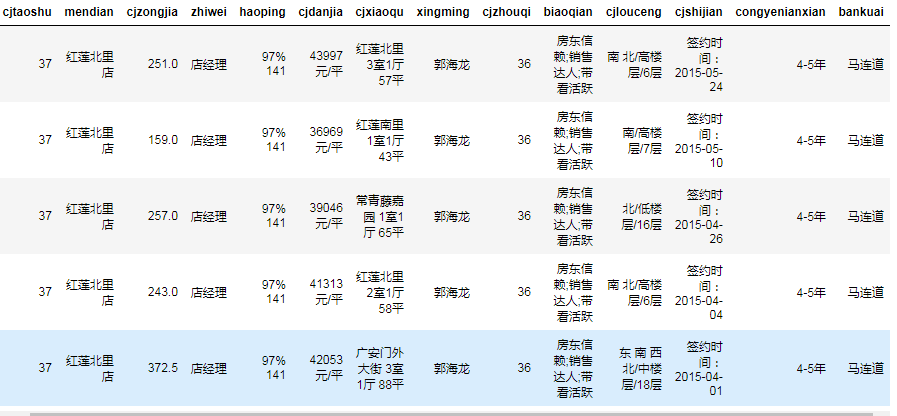
预处理成交单价列数据做预测
data['cjdanjia'] = data.cjdanjia.str.replace('元/平','').astype(np.float32).map(lambda x: round(x/10000,2))
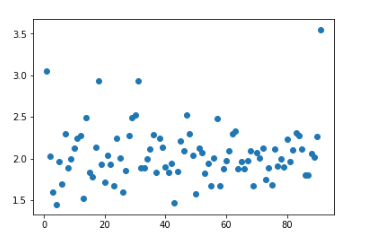
data2 = data[data.cjxiaoqu.str.contains('龙锦苑东五区 3室2厅 124平')]
plt.scatter(range(1,len(data2)+1), data2.cjdanjia)
使用DBSCAN建立模型,使用默认eps值
from sklearn.cluster import DBSCAN
y_pred = DBSCAN().fit_predict(data2.cjdanjia.values.reshape(-1, 1))
plt.scatter(range(1,len(data2)+1), data2.cjdanjia, c = y_pred)

对比使用eps=0.3值
y_pred = DBSCAN(eps=0.3).fit_predict(data2[['cjdanjia']])
plt.scatter(range(1,len(data2)+1), data2.cjdanjia, c = y_pred)

使用DBSCAAN进行异常值处理可以及时掌握异常值,比如较低售价的房屋;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号