

6 爬取微信搜索平台的微信文章保存为本地网页
基本框架参考 5 使用ip代理池爬取糗事百科
其中,加载网页使用的方式:
def load_page(self, url, header): print ("进入load_page函数") print("load_url:",url) #获取有效能使用的代理 proxy=self.get_proxy() print("暂取出的代理是:",proxy) success=validUsefulProxy(proxy) print("代理是否有效的验证结果:",success) while ((proxy==None)|(success==False)): proxy=self.get_proxy() print("暂取出的代理是:",proxy) success=validUsefulProxy(proxy) print("代理是否有效的验证结果:",success) continue print("获取有效能使用的代理是:",proxy) proxy=proxy.decode('utf-8')#必须解码。如果直接转为str,前面会加上b',变成类似b'101.96.11.39:86的形式 print (proxy) proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) #参数传入"http://"+str(proxy) headers=("User-Agent",header) opener=urllib.request.build_opener(proxy) opener.addheaders=[headers] try: response=opener.open(url) data=response.read() except HTTPError as e: print(("访问%s出现HTTP异常")%(url)) print(e.code) print(e.reason) return None except URLError as e: print(("访问%s出现URL异常")%(url)) print(e.reason) return None finally: pass #read返回的是bytes。 print ("使用代理成功加载url:",url) print ("退出load_page函数") return data #使用代理加载网页
编码网址的方式:
key="博士怎么读" pagestart=1 pageend=10 for page in range(pagestart,pageend+1): #如果超出糗事百科热门内容的页数,均会被导向第一页。 self.pagenum=page #编码"&page" header = self.headers() urltmp="http://weixin.sogou.com/weixin?type=2&query="+key+"&page="+str(page) url=urllib.request.quote(urltmp,safe=";/?:@&=+$,",encoding="utf-8") #safe是指定安全字符 html = self.load_page(url, header) self.parse(html,3)
结果报出:
http.client.InvalidURL: nonnumeric port: '60088''
60088就是当时所用代理的端口号
nonnumeric port: '60088''的解决
我访问糗事百科的网址,也用的是这些代理,就没有这么多问题。
为什么这里编码了微信搜索平台的网址以后,还是不行呢。
https://stackoverflow.com/questions/16253049/python-nonnumeric-port-exception
里面建议用:
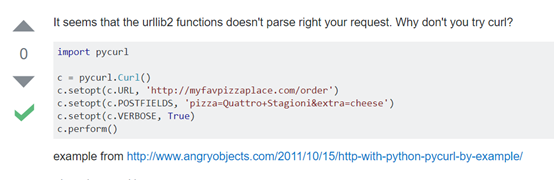
使用pycurl替代urllib
https://blog.csdn.net/xsj_blog/article/details/52102652
https://blog.csdn.net/sunchenzl/article/details/50373689
http://pycurl.io/docs/latest/quickstart.html官网
#使用pycurl c=pycurl.Curl() c.setopt(pycurl.URL,url) #模拟浏览器 c.setopt(pycurl.USERAGENT,header) #使用代理 proxy_str="http://"+str(proxy) print (proxy_str) c.setopt(pycurl.PROXY,proxy_str) b = io.StringIO() #StringIO仍然是获取bytes流 c.setopt(pycurl.WRITEFUNCTION, b.write) c.perform() data=b.getvalue() return data
但是报出:
error: (5, "Could not resolve proxy: b'59.106.213.54")
而输出proxy_str的时候,发现代理地址变成了这个。
pycurl和urllib使用代理的不同,建议一律加上proxy=proxy.decode('utf-8')语句
urllib使用代理:
# proxy=urllib.request.ProxyHandler({"http":"http://"+str(proxy)})
# headers=("User-Agent",header)
其中,str(proxy)转化以后,会多带一个b’, 类似于
http://b'203.130.46.108:9090'就没有任何问题。
但是pycurl就会出问题。
可能urllib.request.ProxyHandler内部有更严谨的处理机制。
从开源代理池项目中获取的proxy,见 5 使用ip代理池爬取糗事百科
也就是从flask接口获取的时候,可能由于编码问题。数据库中的101.96.11.39:86在获取到的时候,会是一个bytes对象。
这个bytes对象,如果使用str或者.format的形式直接转变为字符串,或者拼接到字符串后面的时候,会出现一个重大的bug。也就是,会变成b’ 101.96.11.39:86’。这个时候,很巧的是:
proxy=urllib.request.ProxyHandler({"http":"http://"+str(proxy)})比较变态,能够正确处理。
但是,pycurl则不能正常处理。
pycurl的问题
- l ipdb> pycurl.error: (7, 'Failed to connect to 60.13.156.45 port 8060: Timed out')
代理连接不上。Pycurl连不上代理。但是urllib能连接上。我的每一个代理都是验证能够使用以后才用的。验证的方式是用urllib进行验证。而这里pycurl却不能用。
- l 重新运行程序,从数据库中又取出了一个代理,结果不再提示代理错误,又出现
ipdb> pycurl.error: (23, 'Failed writing body (0 != 154)')
|
按网上的说法讲stringio改为io.BytesIO即可。 |
但是又出现新的错误,即ipdb> pycurl.error: (52, 'Empty reply from server')
改为post方式:
c=pycurl.Curl() url="http://weixin.sogou.com/weixin" c.setopt(pycurl.URL,url) #模拟浏览器 c.setopt(pycurl.USERAGENT,header) #使用代理 proxy=proxy.decode('utf-8') #避免变成b'203.130.46.108:9090',这是开源代理池项目的弊端 print (proxy) proxy_str="http://{}".format(proxy) print (proxy_str) post_data_dic = urllib.parse.urlencode({ "type":"2", "key":"博士怎么读", "page":"1" }).encode('utf-8') c.setopt(pycurl.POSTFIELDS,post_data_dic) c.setopt(pycurl.PROXY,proxy_str) b = io.BytesIO() c.setopt(pycurl.WRITEFUNCTION, b.write) c.perform() data=b.getvalue() print (data) return data
结果输出的是:
b'<html>\r\n<head><title>302 Found</title></head>\r\n<body bgcolor="white">\r\n<center><h1>302 Found</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>\r\n'
可见pycurl不能解决。
继续用urllib解决问题(终极解决方案,误打误撞)
在前面使用pycurl以后,我准备使用post方式去解决这个问题。于是回到urllib以后,我改用post方式去解决这个问题。由于写程序的时候,post方式必然要求如下写法:
proxy=self.get_proxy() print("暂取出的代理是:",proxy) success=validUsefulProxy(proxy) print("代理是否有效的验证结果:",success) while ((proxy==None)|(success==False)): proxy=self.get_proxy() print("暂取出的代理是:",proxy) success=validUsefulProxy(proxy) print("代理是否有效的验证结果:",success) continue print("获取有效能使用的代理是:",proxy) proxy=proxy.decode('utf-8')#必须解码。如果直接转为str,前面会加上b',变成类似b'101.96.11.39:86’的字符串 print (proxy) proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) req=urllib.request.Request(url) req=urllib.request.Request(url,postdata) #req.add_header("User-Agent",header) req.set_proxy("http://{}".format(proxy),"http") try: response=urllib.request.urlopen(req) data=response.read() except HTTPError as e: print(("访问%s出现HTTP异常")%(url)) print(e.code) print(e.reason) return None except URLError as e: print(("访问%s出现URL异常")%(url)) print(e.reason) return None except Exception as e: print(("访问%s出现异常")%(url)) print(e) return None finally: pass #read返回的是bytes。 print ("使用代理成功加载url:",url) print ("退出load_page函数") return data
接着传入postdata。
postdata=urllib.parse.urlencode({
"type":type,
"key":key,
"page":page
}).encode('utf-8')
这个时候我的url忘记改了:仍然是:
urltmp="http://weixin.sogou.com/weixin?type=2&query="+key+"&page="+str(page) url=urllib.request.quote(urltmp,safe=";/?:@&=+$,",encoding="utf-8")
- 网页解析成功。我以为是post方式起了作用。当我将url改为http://weixin.sogou.com以后,程序立刻报出异常,即访问http://weixin.sogou.com/出现HTTP异常,405Not Allowed
- 这个时候,我将上面的程序中的
req=urllib.request.Request(url,postdata)
改为:
req=urllib.request.Request(url)
问题立刻解决了。
这说明什么:http://weixin.sogou.com无法处理post数据。也就是服务器就不接受post请求。
最后的解决措施是什么:
从:
proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) #参数传入"http://"+str(proxy)
headers=("User-Agent",header)
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
try:
response=opener.open(url)
data=response.read()
改为:
proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)})
req=urllib.request.Request(url)
req=urllib.request.Request(url,postdata)
#req.add_header("User-Agent",header)
req.set_proxy("http://{}".format(proxy),"http")
try:
response=urllib.request.urlopen(req)
data=response.read()
就是这么一点简单的变动:下面的url编码以后能够直接在浏览器中打开
urltmp="http://weixin.sogou.com/weixin?type=2&query="+key+"&page="+str(page) url=urllib.request.quote(urltmp,safe=";/?:@&=+$,",encoding="utf-8")
处理同样的url编码:
前者会提示http.client.InvalidURL: nonnumeric port: '60088'''60088''就是你用的代理的端口号。
这说明,urllib.request.urlopen要比opener.open使用起来更健壮。
这一定是urllib的一个bug。因为前者在之前做糗事百科爬虫的时候也会考虑到page的变动,就不会出现这个问题。做微信搜索平台爬虫只多了一个key=“博士怎么读”,但是编码的也没有任何问题,在浏览器中能够打开编码后的网址。但是就是会报出异常。
完整代码
# -*- coding: utf-8 -*- """ Created on Sat Jul 14 15:24:51 2018 @author: a """ import urllib.request import re from urllib.error import HTTPError from urllib.error import URLError import os import time import random from lxml import etree import requests import sys import pycurl import io from threading import Thread sys.path.append('H:\proxy_pool-master') from Util.utilFunction import validUsefulProxy class MySpider: pagenum=0 def headers(self): headers_list = [ "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400", "Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0", "Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)", "Mozilla/5.0(WindowsNT6.1;rv:2.0.1)Gecko/20100101Firefox/4.0.1", "Opera/9.80(WindowsNT6.1;U;en)Presto/2.8.131Version/11.11", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TencentTraveler4.0)", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Maxthon2.0)", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;360SE)", "Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)", ] ua_agent = random.choice(headers_list) return ua_agent def load_page(self, url, header,postdata=None): print ("进入load_page函数") print("load_url:",url) #获取有效能使用的代理 proxy=self.get_proxy() print("暂取出的代理是:",proxy) success=validUsefulProxy(proxy) print("代理是否有效的验证结果:",success) while ((proxy==None)|(success==False)): proxy=self.get_proxy() print("暂取出的代理是:",proxy) success=validUsefulProxy(proxy) print("代理是否有效的验证结果:",success) continue print("获取有效能使用的代理是:",proxy) proxy=proxy.decode('utf-8')#必须解码。如果直接转为str,前面会加上b',变成类似b'101.96.11.39:86的形式 print (proxy) proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) req=urllib.request.Request(url) ##不能用postdata的方式,因为http://weixin.sogou.com不处理post数据 #req=urllib.request.Request(url,postdata) req.add_header("User-Agent",header) req.set_proxy("http://{}".format(proxy),"http") try: response=urllib.request.urlopen(req) data=response.read() except HTTPError as e: print(("访问%s出现HTTP异常")%(url)) print(e.code) print(e.reason) return None except URLError as e: print(("访问%s出现URL异常")%(url)) print(e.reason) return None except Exception as e: print(("访问%s出现异常")%(url)) print(e) return None finally: pass #read返回的是bytes。 print ("使用代理成功加载url:",url) print ("退出load_page函数") return data #用urllib解析网址,总是报出nonnumeric port异常,而且异常数字是代理的端口号。 #之前搜索糗事百科的时候就没有这个问题。而且我编码后的url直接在浏览器中打开,就能 #访问微信搜索平台。因此,用post方式试试。 # proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) # headers=("User-Agent",header) # opener=urllib.request.build_opener(proxy) # opener.addheaders=[headers] # try: # response=opener.open(url) # data=response.read() # except HTTPError as e: # print(("访问%s出现HTTP异常")%(url)) # print(e.code) # print(e.reason) # return None # except URLError as e: # print(("访问%s出现URL异常")%(url)) # print(e.reason) # return None # except Exception as e: # print(("访问%s出现异常")%(url)) # print(e) # return None # finally: # pass # #read返回的是bytes。 # print ("使用代理成功加载url:",url) # print ("退出load_page函数") # return data #使用代理加载网页 def parse(self, html,switch): print ("进入parse函数") if switch==3: print("这里是微信搜索平台的网页解析规则") data=html.decode('utf-8') #print (data) xpath_value='//div[@class="txt-box"]/h3/a/@href' #注意xpath选择器返回的是列表 selector = etree.HTML(data) titilelist=selector.xpath(xpath_value) print(titilelist) print ("解析第{}页,共获取到{}篇文章".format(self.pagenum,len(titilelist))) else: print("尚未制定解析规则") print ("退出parse函数") def get_proxy(self): return requests.get("http://localhost:5010/get/").content def delete_proxy(self,proxy): requests.get("http://localhost:5010/delete/?proxy={}".format(proxy)) def main(self): #设置搜索关键词 key="博士怎么读" pagestart=1 pageend=10 for page in range(pagestart,pageend+1): #如果超出糗事百科热门内容的页数,均会被导向第一页。 self.pagenum=page #编码"&page" ##不能用postdata的方式,因为http://weixin.sogou.com不处理post数据 # postdata=urllib.parse.urlencode({ # "type":str(type__), # "key":key, # "page":str(page) # }).encode('utf-8') header = self.headers() urltmp="http://weixin.sogou.com/weixin?type=2&query="+key+"&page="+str(page) url=urllib.request.quote(urltmp,safe=";/?:@&=+$,",encoding="utf-8") #safe是指定安全字符 html = self.load_page(url, header) self.parse(html,3) if __name__ == "__main__": myspider = MySpider() myspider.main()
反思
程序调试其实对个人的水平是没有什么进步的。总是在向着错误的方向去排查问题。
只能希望以后少遇到这种问题。先思考几点问题:
- 正确的做法是什么?书上其实用的就是urllopen,但是我平时用opener.open习惯了,形成了一种惯性。于是,我总是怀疑是url编码出问题,或者根据错误的代码去搜索解决方案。而忽略了一件事情,那就是,正确的做法是什么。如果跟书中的代码进行了比对,立刻就解决了。我平时看代码很快,但是没想到总是把大量时间花在了调试上。
- 其次,适当的时候,学会寻求别人的帮助。时间是无价之宝,不要耗费在这种细节和小问题上,否则,时间没了,就是真的没了。
2018年7月20日20:28:55日补充:nonnumerical port错误真正的原因
后来上面的代码再次遇到错误:说//是非数字端口号,即nonnumerical port。
真正的错误是:
- 我一开始用的是:proxy=urllib.request.ProxyHandler({"http":"{}".format(proxy)})。接着又req.set_proxy("{}".format(proxy),"http")。因此存在了重复。此时proxy已经不是类似“101.96.11.58:80”的内容了。
- 此外设置代理的时候,不要用:#proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)})而应该是:proxy=urllib.request.ProxyHandler({"http":"{}".format(proxy)})。这也是为什么会提示://非数字端口号的原因
将最初使用的open的代码
proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) #参数传入"http://"+str(proxy)
headers=("User-Agent",header)
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
try:
response=opener.open(url)
data=response.read()
改为:
proxy=urllib.request.ProxyHandler({"http":"http://{}".format(proxy)}) #参数传入"http://"+str(proxy)
headers=("User-Agent",header)
opener=urllib.request.build_opener(proxy)
opener.addheaders=[headers]
try:
response=opener.open(url)
data=response.read()
问题也解决了。
所以,根本原因在于设置的时候用的是类似于下面的,而书上是不需要在value值中放入http://的。
({"http":"http://{}".format(proxy)})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号