

程序员的计算机修养-内存模型
内存对于程序员而言可以说是非常重要,但很多人对其只知其名,不知道它的内部原理。
物理结构
看一下它的物理结构,大家肯定见过。
内存的内部是由各种IC电路组成的,主要分为3种
随机存储器(RAM):读写很快,断电失去数据。
只读存储器(ROM):只能读取,断电数据不丢失。
高速缓存(Cache):有3种,L1,L2,L3 Cache。它们位于CPU和内存之间,比内存的读写更快。

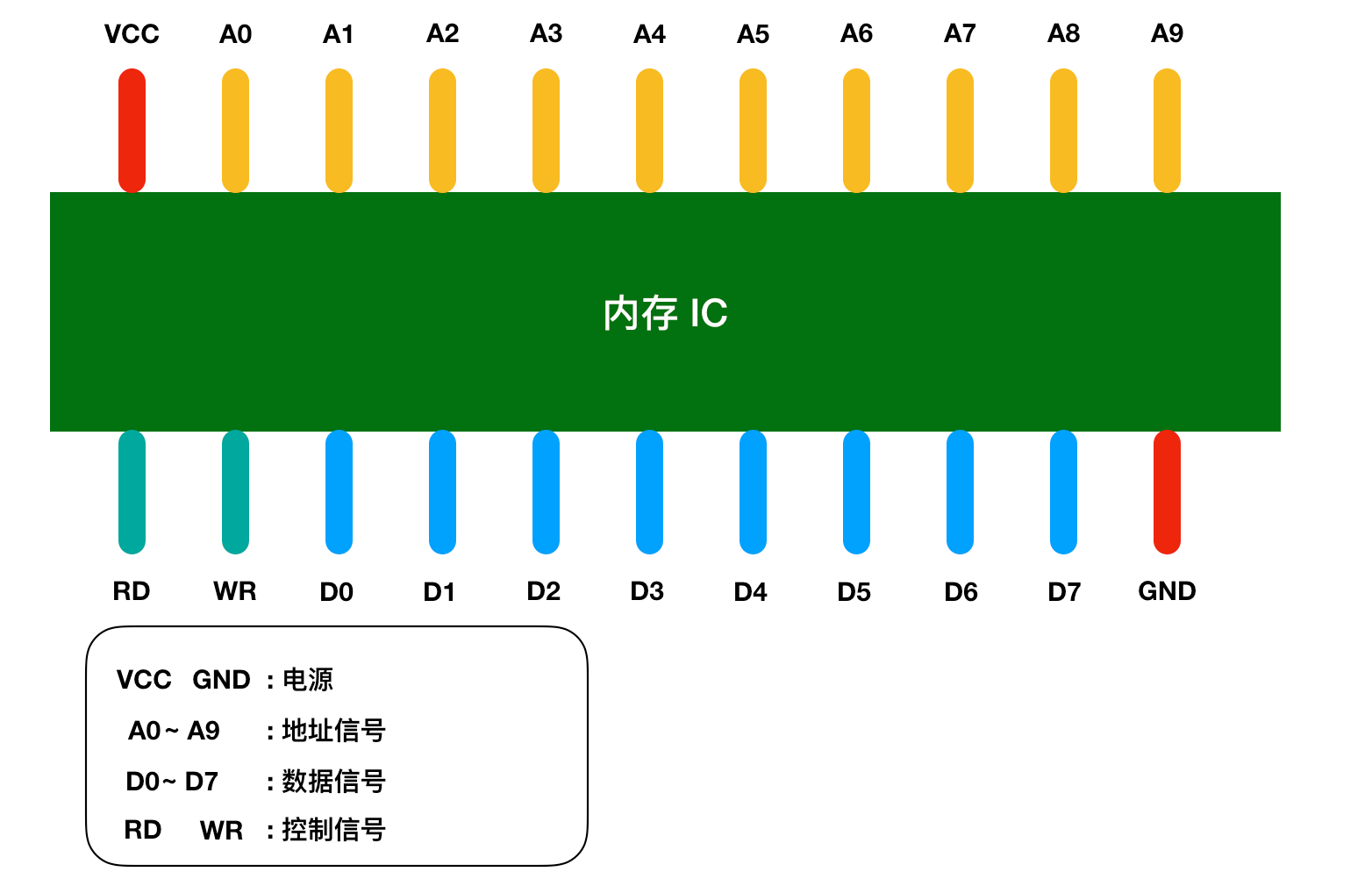
内存IC引脚配置 图中VCC和GND表示电源,A0 - A9是地址信号的引脚,D0 - D7表示的是控制信号、RD和WR都 是好控制信号,我用不同的颜色进行了区分。
将电源连接到VCC和GND后,就可以对其他引脚传递 0和1的信号,大多数情况下,+5V表示1, 0V表示0。 我们都知道内存是用来存储数据,那么这个内存IC中能存储多少数据呢?
D0 - D7表示的是数据信 号,也就是说,一次可以输入输出8 bit = 1 byte的数据。A0 - A9是地址信号共十个,表示可以指定 00000 00000 - 11111 11111共2的10次方=1024个地址。
每个地址都会存放1 byte的数据,因 此我们可以得出内存IC的容量就是1 KB。 如果我们使用的是512 MB的内存,这就相当于是512000(512 * 1000)个内存IC。当然,一台计 算机不太可能有这么多个内存IC,然而,通常情况下,一个内存IC会有更多的引脚,也就能存储更多数据。
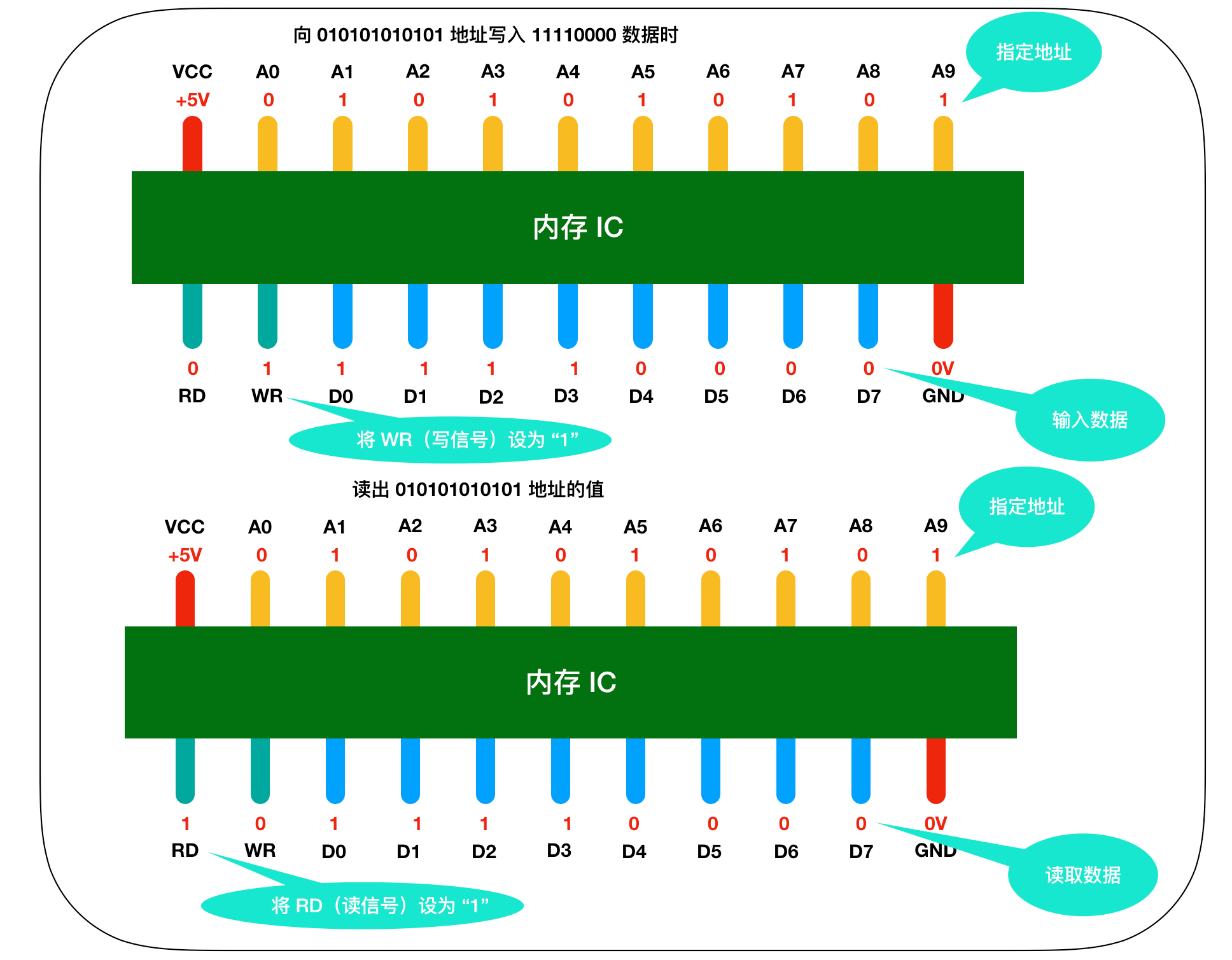
来详细描述一下这个过程,假设我们要向内存IC中写入Ibyte的数据的话,它的过程是这样的: ・ 首先给VCC接通+5V的电源,给GND接通0V的电源,使用A0 - A9来指定数据的存储场 所,然后再把数据的值输入给D0 - D7的数据信号,并把WR (write)的值置为1,执行完这些操作后,即可以向内存IC写入数据 ・ 读出数据时,只需要通过A0 - A9的地址信号指定数据的存储场所,然后再将RD的值置为1即 可。 ・ 图中的RD和WR又被称为控制信号。其中当WR和RD都为0时,无法进行写入和读取操作。
现实模型
为了便于记忆,我们把内存模型映射成为我们现实世界的模型,在现实世界中,内存的模型很想我们生活的楼房。在这个楼房中,1层可以存储一个字节的数据,楼层号就是地址,下面是内存和楼层整合的模型图。
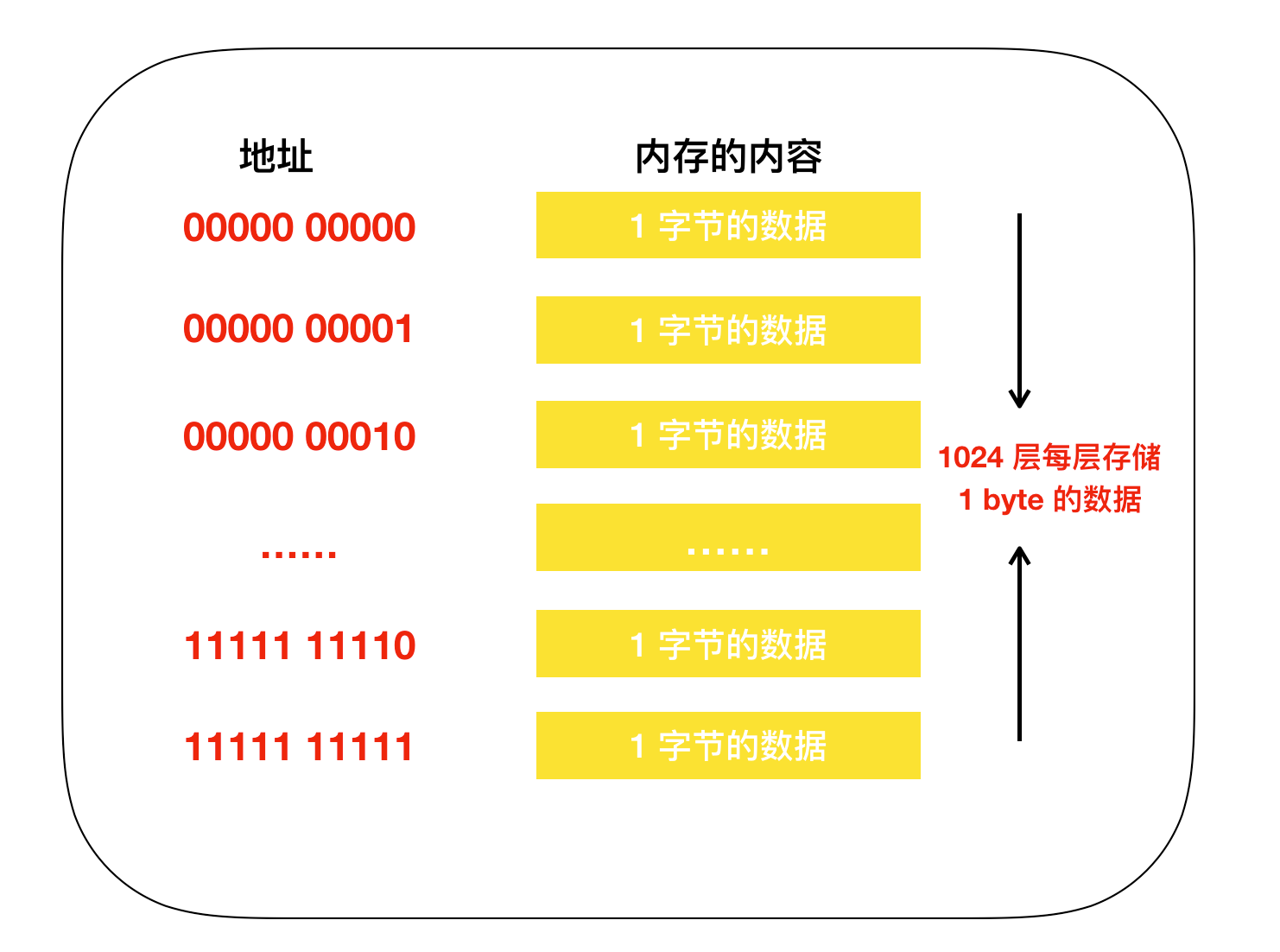
下面看一个实际例子的内存模型
//定义变量 char a; short b; long c; //变量赋值 a = 123; b = 123; c = 123;
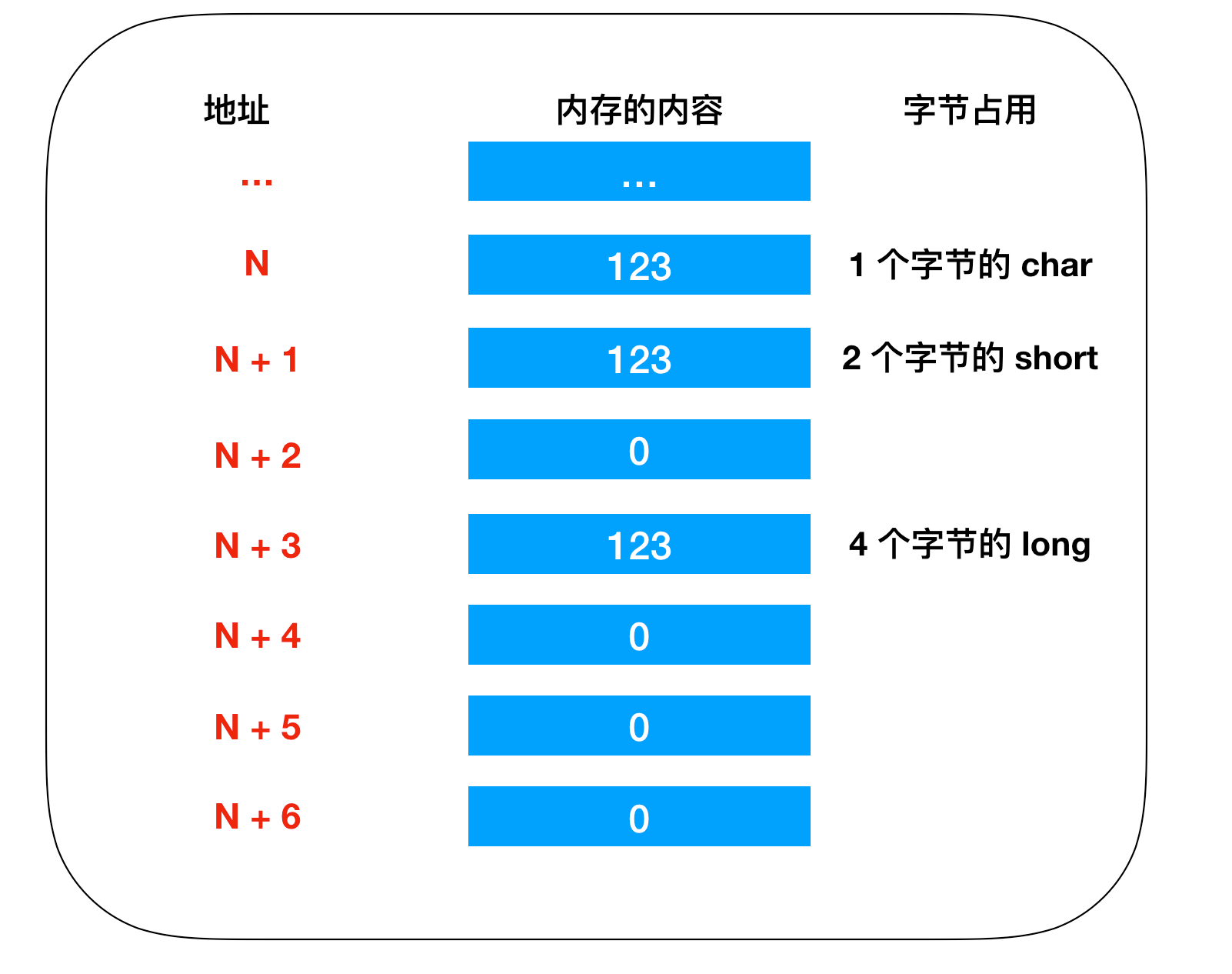
真正的内存模型
前面讲的只是内存的模型,下面要描述的是关于不同的CPU,不同的操作系统下的内存模型。
在这之前我们先看下不同的语言和编译器为内存分配的内存区域
C语言:代码区、初始化数据区、未初始化数据区、堆区和栈区5个部分 C++: 堆、栈、自由存储区、全局/静态存储区和常量存储区 c#: 代码区、常量区、静态区、堆、栈
不管是什么语言,到最终都会被编译成机器语言,然后cpu会一条一条指令的去执行,CPU和内存并不是直接交换数据的,它们之间还隔着一个高速缓存。高速缓存是对程序员透明的,这意味在编程的时候是感知不到CPU的缓存的存在的。一般情况下确实如此,但在,在某些特殊的情形下(多核多线程),就不能忽略缓存的存在了。这其实是和缓存的设计有关系,一般多处理器下的每个CPU都有一个自己的缓存,存储在这个缓存的数据是其它CPU是无法查看的。
那么就引出了一个如何确保数据一致性的问题,其实这个跟当前web缓存和数据库一致性的问题类似,加一些读写锁就能解决。
还有个问题是cpu为优化指令执行速度提升效率会对指令进行指令重排。同样的对于多线程就会有问题存在。
举个例子,CPU-0将要执行两条指令,分别是: STORE x LOAD y 当CPU-0执行指令1的时候,发现这个变量x的当前状态为Shared,这意味着其它CPU也持有了x,因此根据缓存一致性协议,CPU-0在修改x之前必须通知其它CPU,直到收到来自其它CPU的ack才会执行真正的修改x。
但是,事情没有这么简单。现代CPU缓存通常都有一个Store Buffer,其存在的目的是,先将要Store的变量记下来,注意此时并不真的执行Store操作,然后待时机合适的时候再执行实际的Store。
有了这个Store Buffer,CPU-0在向其它CPU发出disable消息之后并不是干等着,而是转而执行指令2(由于指令1和指令2在CPU-0看来并不存在数据依赖)。这样做效率是有了,但是也带来了问题。
虽然我们在写程序的时候,是先STORE x再执行LOAD y,但是实际上CPU却是先LOAD y再STORE x,这个便是CPU乱序执行(reorder)的一种情况! 当你的程序要求指令1、2有逻辑上的先后顺序时,CPU这样的优化就是有问题的。但是,CPU并不知道指令之间蕴含着什么样的逻辑顺序,在你告诉它之前,它只是假设指令之间都没有逻辑关联,并且尽最大的努力优化执行速度。
因此我们需要一种机制能告诉CPU:这段指令执行的顺序是不可被重排的!做这种事的就是内存屏障(memory barrier)!
那么内存模型是什么
首先,残酷的现实就是每个CPU设计都是不同的,每个CPU对指令乱序的程度也是不一样的。比较保守的如x86仅会对Store Load乱序,但是一些优化激进的CPU(PS的Power)会允许更多情况的乱序产生。如果目标是写一个跨平台多线程的程序,那么势必要了解每一个CPU的细节,来插入确切的、足够的内存屏障来保证程序的正确性。这是多么的不科学啊!科学的做法应该是,我为一个抽象的机器写一套抽象的程序,然后在不同的平台下让编程语言、编译器来生成合适的内存屏障。因此,我们有了内存模型的概念。不同平台下的实现差别被统一的内存模型所隐藏,只需要根据这个抽象的内存模型来编写程序即可,所以jvm, .net才应运而生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号