2-1 进行误差分析
进行误差分析(Carrying out error analysis)
如果你希望让学习算法能够胜任人类能做的任务,但你的学习算法还没有达到人类的表现,那么人工检查一下你的算法犯的错误也许可以让你了解接下来应该做什么。这个过程称为错误分析。
假设你正在调试猫分类器,然后你取得了 90%准确率,相当于 10%错误,在你的开发集上做到这样,这离你希望的目标还有很远。也许你的队员看了一下算法分类出错的例子,注意到算法将一些狗分类为猫,你看看这两只狗,它们看起来是有点像猫,至少乍一看是。

你可以针对狗,收集更多的狗图,或者设计一些只处理狗的算法功能之类的,为了让你的猫分类器在狗图上做的更好,让算法不再将狗分类成猫。所以问题在于,你是不是应该去开始做一个项目专门处理狗?这项目可能需要花费几个月的时间才能让算法在狗图片上犯更少的错误,这样做值得吗?或者与其花几个月做这个项目,有可能最后发现这样一点用都没有。这里有个错误分析流程,可以让你很快知道这个方向是否值得努力。
首先,收集一下,比如说 100 个错误标记的开发集样本,然后手动检查,一次只看一个,看看你的开发集里有多少错误标记的样本是狗。现在,假设事实上,你的 100 个错误标记样本中只有 5%是狗,就是说在 100 个错误标记的开发集样本中,有 5个是狗。这意味着 100 个样本,在典型的 100 个出错样本中,即使你完全解决了狗的问题,你也只能修正这 100 个错误中的 5 个。或者换句话说,如果只有 5%的错误是狗图片,那么如果你在狗的问题上花了很多时间,那么你最多只能希望你的错误率从 10%下降到 9.5%,对吧?错误率相对下降了 5%(总体下降了 0.5%, 100 的错误样本,错误率为 10%,则样本为 1000),那就是 10%下降到 9.5%。你就可以确定这样花时间不好,或者也许应该花时间,但至少这个分析给出了一个上限。如果你继续处理狗的问题,能够改善算法性能的上限,对吧?在机器学习中,有时我们称之为性能上限,就意味着,最好能到哪里,完全解决狗的问题可以对你有多少帮助。
但现在,假设发生了另一件事,假设我们观察一下这 100 个错误标记的开发集样本,你发现实际有 50 张图都是狗,所以有 50%都是狗的照片,现在花时间去解决狗的问题可能效果就很好。这种情况下,如果你真的解决了狗的问题,那么你的错误率可能就从 10%下降到5%了。然后你可能觉得让错误率减半的方向值得一试,可以集中精力减少错误标记的狗图的问题。
在机器学习中,有时候我们很鄙视手工操作,或者使用了太多人为数值。但如果你要搭建应用系统,那这个简单的人工统计步骤,错误分析,可以节省大量时间,可以迅速决定什么是最重要的,或者最有希望的方向。
有时你在做错误分析时,也可以同时并行评估几个想法,比如,你有几个改善猫检测器的想法,也许你可以改善针对狗图的性能,或者有时候要注意,那些猫科动物,如狮子,豹,猎豹等等,它们经常被分类成小猫或者家猫,所以你也许可以想办法解决这个错误。或者也许你发现有些图像是模糊的,如果你能设计出一些系统,能够更好地处理模糊图像。也许你有些想法,知道大概怎么处理这些问题,要进行错误分析来评估这三个想法。
可以建立这样一个表格,人工过一遍你想分析的图像集,列表和评论如下:
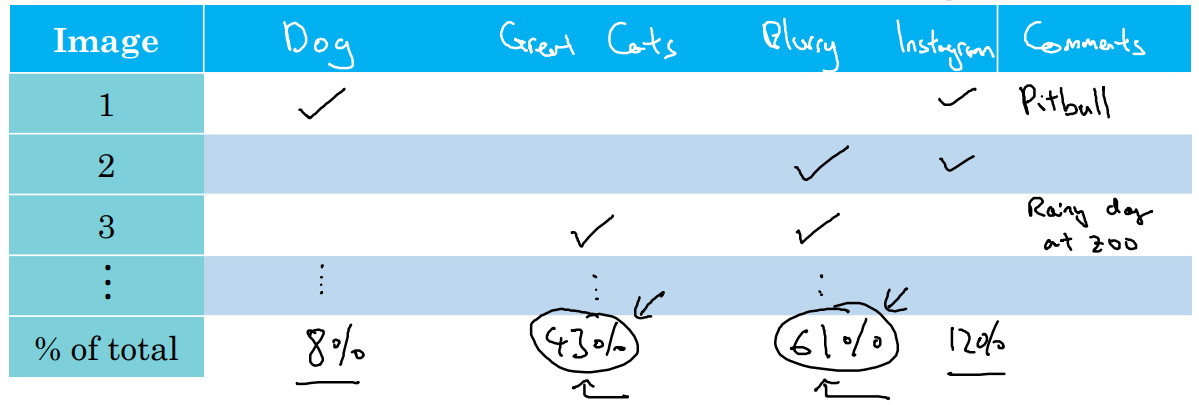
最后,这组图像过了一遍之后,我可以统计这些错误)百分比,或者这里每个错误类型的百分比,有多少是狗,大猫或模糊这些错误类型。所以也许你检查的图像中8%是狗,可能43%属于大猫,61%属于模糊。在这个样本中,有很多错误来自模糊图片,也有很多错误类型是大猫图片。不管你对狗图片或者 Instagram 图片处理得有多好,在这些例子中,你最多只能取得 8%或者 12%的性能提升。而在大猫图片这一类型,你可以做得更好。或者模糊图像,这些类型有改进的潜力。
所以总结一下,进行错误分析,你应该找一组错误样本,可能在你的开发集里或者测试集里,观察错误标记的样本,看看假阳性( false positives)和假阴性( false negatives),统计属于不同错误类型的错误数量。通过统计不同错误标记类型占总数的百分比,可以帮你发现哪些问题需要优先解决,或者给你构思新优化方向的灵感。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号