

hbase基本命令
1、Hbase shell客户端使用
a、进入客户端 hbase shell
b、常用命令
list 列出Hbase中存在的所有表
alter 修改列簇(column family)模式
count 统计表中行的数量
create 创建表
describe 显示表相关的详细信息
delete 删除指定对象的值(可以为表,行、列对应的值,另外也可以指定时间戳的值)
deleteall 删除指定行的所有元素值
disable 使表无效
drop 删除表
enable 使表有效
exists 测试表是否存在
exit 退出Hbaseshell
get 获取行或单元(cell)的值
incr 增加指定表,行或列的值
put 向指向的表单元添加值
tools列出Hbase所支持的工具
scan 通过对表的扫描来获取对用的值
status 返回Hbase集群的状态信息
shutdown 关闭Hbase集群(与exit不同)
c、关于表: (创建表create、查看表列表list、查看表的详细信息desc、删除表drop、清空表truncate、修改表的定义alter、)
d、关于数据的操作(增put、删delete、查get + scan,改=变相的增加)
e、查看有哪些命令: help;如果哪个命令不会使用 help "command"
2、操作例子
a、创建表student和stu
create 'student','cf1'
create 'stu','cf1','cf2','cf3'
查看表的描述: desc 'student'
一个大括号就相当于一个列簇: {NAME => 'cf1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACH
E_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER
=> 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false',
COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'}
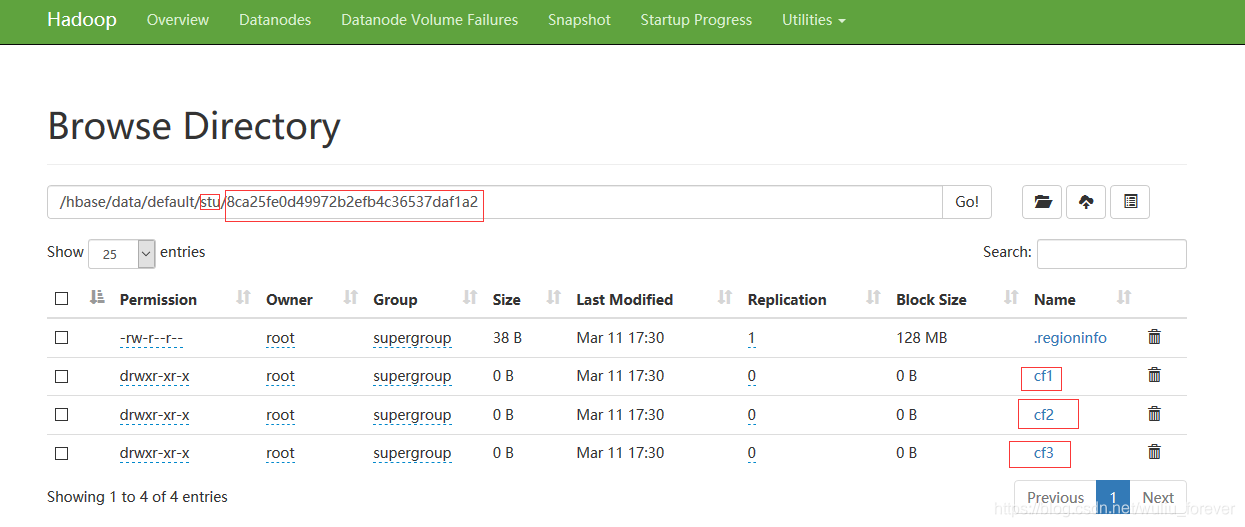
stu插入一条数据:
put 'stu','rk001','cf1:age','18'
put 'stu','rk001','cf1:name','zhangsan' 发现hdfs中stucf1下没有内容去观察对应表的region在那一台服务器上杀掉regionserver之后就会有了...
scan 'stu'
解释:/hbase/data/default/stu/8ca25fe0d49972b2efb4c36537daf1a2/cf1/d89f620da4754e1092402b577f589f8a
data:目录即是Hbase自动生成的用来存储所有表数据的一个目录
default:默认的一个namespace
stu:就是一张表,其实就是一个文件夹
8ca25fe0d49972b2efb4c36537daf1a2:就是stu这张表中的一个region
cf1:就是这个region中第一个列簇所对应的一个store
d89f620da4754e1092402b577f589f8a:这就是用来存储真实数据的hfile
b、创建表指定版本
create 'stu2',{NAME => 'cf1', VERSIONS => 5},{NAME => 'cf2', VERSIONS => 2} cf1下任何一个key-value最多版本5个
放入数据:
put 'stu2','rk01','cf1:age',18
put 'stu2','rk01','cf1:age',19
put 'stu2','rk01','cf1:age',20
put 'stu2','rk01','cf1:age',21
put 'stu2','rk01','cf1:name','lisi'
get 'stu2','rk01' 出现:(默认的情况下是最新的值,get指定rowkey,scan )
COLUMN CELL
cf1:age timestamp=1552348396259, value=21
cf1:name timestamp=1552348699286, value=lisi
1 row(s)
Took 0.0201 seconds
put 'stu2','rk01','cf1:age',22
get 'stu2','rk01',{COLUMN => 'cf1:age', VERSIONS => 5}
put 'stu2','rk01','cf1:age',23
get 'stu2','rk01',{COLUMN => 'cf1:age', VERSIONS => 5} 18不出现了
get 'stu2','rk01',{COLUMN => 'cf1:age', TIMESTAMP => 1552348396259} 根据时间戳获取唯一的一个
put 'stu2','rk01','cf2:p','xxxxxx'
get 'stu2','rk01','cf2'
查询分页:
scan 'stu2',{COLUMNS => 'cf1:age'}
scan 'stu2',{COLUMNS => 'cf1:age', LIMMIT 10, STARTROW => 'xx'}
删除某个时间戳的: delete 'stu2','rk01','cf1:age',1552348396259;这个时间戳以前的数据都被删除了
put命令的使用:
put 表 行健 列定义 值
put 'stu2','rk01','cf1:age',22
get 表 行健
get 表 行健 列簇
get 表 行健 列簇:列
get 表 行健 列簇:列 时间戳
scan 表
scan 表 起始行健 结束行健
scan 表 列簇
scan 表 列簇:列
c、删除表
disable 'student'
drop 'student'
d、清空truncate 'stu' 删除数据key-value也删除
drop == 情况数据truncate + 删除表定义
e、Hbase的表一经创建之后,那么列簇的名字就不能更改了,列簇的属性可以改。
如果说列簇的名字指定有误,可以通过线删除列簇,然后添加回来。
但是你必须要承受,损失这个列簇数据的代价。
f、修改alter
1、增加一个列簇
alter 'stu2',NAME=>'f1',VERSIONS=>4 增加一个列簇f1,每个region会多一个store
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.8088 seconds
2、删除一个列簇
alter 'stu2', NAME => 'cf1',METHOD => 'delete'
alter 'stu2', 'delete' => 'f1'
g、show_filters 查看所有过滤器
h、往HBase插入数据的五种方式
1、table.put(put)
2、table.put(puts)
3、MR
4、多线程多客户端并发写入
5、bulkload 其实是使用MR程序提前生成好HFile
1、首先往WAL LOG中记录日志数据
2、把数据更新到内存
3、内存达到一定的值,就会flush数据到磁盘HFile
4、Hfile达到一定数据之后,就会进行合并,storefile
3、过滤器查询
引言:过滤器主要分为两大类(比较过滤器、专用过滤器)
过滤器的作用是在服务端判断数据是否满足条件,然后只将满足条件的数据返回给客户端;
条件:各种过滤规则 + 比较规则;
比较规则: == 、!=、<、>、>=、<=
hbase过滤器的比较运算符:
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
hbase过滤器的比较器(指定比较机制):
BinaryComparator按字节索引顺序比较指定字节数组,采用Bytes.compareTo(byte[]);
BinaryPrefixComparator跟前面相同,只是比较左端的数据是否相同;
NullComparator判断给定的是否为空;
BitComparator按位比较;
RegexStringComparator 提供一个正则的比较器,仅支持EQUAL和非EQUAL;
SubstringComparator判断提供的子串是否出现在value中;
1、比较过滤器
a、行健过滤器RowFilter
Filter filter = new RowFilter (CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("user000")));
b、列簇过滤器FamilyFilter
Filter filter = new FamilyFilter(CompareOp.LESS, new BinaryComparator(Bytes.toBytes("列簇name->cf1")));
c、 列过滤器QualifierFilter
Filter filter = new QualifierFilter(CompareOp.LESS_OR_EQUAL, new BinaryComparator(Bytes.toBytes("name")));
d、 值过滤器ValueFilter
Filter filter = new ValueFilter(CompareOp.EQUAL, new SubstringComparator("zhangsan");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号